
『如果可以,我想和你回到那天相遇』(韋禮安,2021)
「與當時查出來的資料面貌再次相遇」在資料的世界,可能嗎?這和軟體工程,又有什麼牽連?
我們曾經提過,資料倉儲是一個 OLAP 系統,常用於生成報表、執行多維資料分析,並提供關鍵決策的支援。如果資料分析的結果在不同時間點產生不一致的結果,會導致錯誤的解讀或決策。
在以下幾種資料分析的情況,資料可重現性都至關重要。
在機器學習的領域上,資料的可重現性也是重要的。它能夠確保模型的訓練、測試和評估過程的一致性。以下場景是為什麼可重現性在機器學習中如此關鍵的幾個原因:
總結來說,資料可重現性在描述的是對同一份資料,我和別人做同樣的操作,獲取結果要一樣。我在今天和過去做同一個操作,獲取結果也要一樣。
可重現性的概念不難理解,但和我們這幾天密切介紹的 Airflow 有什麼關係呢?
以 Day 08 提到的例子延伸,如果我們在 7/20 時,想要透過 Airflow 重新產製 7/1 的 RFM 分析報表,得要確認分析上游的訂單表 orders 及顧客表 users 都是 7/1 當日的情況。
在一張增量表中,每筆源頭資料的變動紀錄都會被保留下來,我們可以透過 重現當時的狀況了!但衍生兩個問題:
如何正確地選取資料,呈現「當天日期」?
每張表都可以重現當時的狀況嗎?
如何正確地選取時間?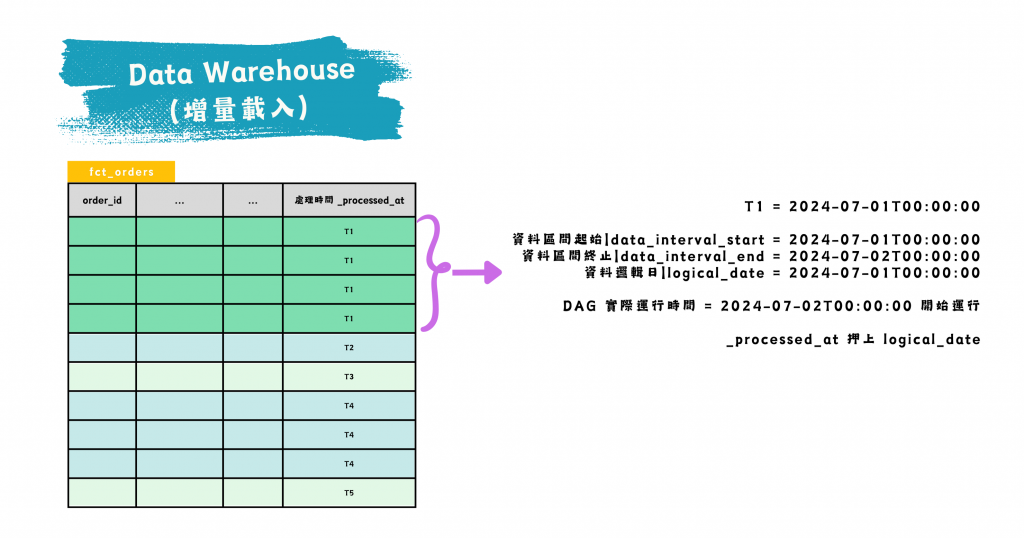
圖/DAG 執行日期與邏輯日期的差異。簡書廷製。
從這張圖我們可以掌握到,若想重新呈現 7/1 當時 fct_order 這張增量表的狀況,得先確定是 7/1 開始時還是結束時。
假設是 7/1 結束時的狀況,那就是針對 7/1 00:00 ~ 23:59 這段區間的增量匯入結束為截止線,選取 fct_order 截止線以前的資料使用 window funtion 去除重複 order_id 資料,即可重現 OLTP 裡面的 orders 當時狀況!
--- 增量
WITH orders AS (
SELECT
order_id,
...,
ROW_NUMBER() OVER(
PARTITION BY order_id ORDER BY _processed_at DESC
) AS rn
FROM
`fct_orders`
WHERE
資料時間篩選條件
)
SELECT
...
FROM
orders
WHERE
rn = 1
資料時間篩選條件的候選寫法:
_processed_at <= '{{ logical_date }}' _processed_at <= '{{ data_interval_start }}' _processed_at < '{{ data_interval_end }}' _processed_at < datatime.now()
用 (D) 的 Python datatime 套件作為時間篩選條件,會讓時間線無法重回「當時」,因為 datatime.now() 指的是系統當下時間。只有 (A)(B)(C) 能幫助我們在 7/20 時,透過 Airflow 的 Backfill 重新產製 7/1 的 RFM 分析報表。
airflow dags backfill \
--start-date START_DATE \
--end-date END_DATE \
dag_id
用 Airflow 來做工作流程設計時,別忘了善用 jinja template 參數化 的功能處理 **批量 (batch) ** 特性的資料。若用一般軟體開發的思路進行,用了不適當的時間條件,那 Airflow 就只能做為一個不具資料可重現性的排程器了!
每張表都可以重現當時的狀況嗎?
答案是否定的。如果資料倉儲內每一張表都設計的像 OLTP 一樣,只呈現「事務的最新狀態」,那資料一但被更新就是直接覆蓋寫入,怎麼 query 也回不去了。
因此源頭資料進來後,至少得有一張表做增量或全量的匯入,不能覆蓋任何的歷史,這樣才保有日後需要進行資料回溯時的可重現性。
今天提的都是「資料」的可重現性。而軟體工程上,RESTful API 談到的冪等性,指的是指多次對同一資源進行相同的操作,不會導致系統狀態的變化。例如 HTTP method 裡的 GET 操作。
有趣的是,RESTful API 搭配 OLTP 系統下,雖然 GET 操作不會改變該資料的狀態,但是 OLTP 的特性是只呈現事務的最新狀態,一旦該資料被其他請求改變了,下一次 GET 時,就無法重現資料先前的狀況了!
*註:今天並非討論資料庫本身的援備及回溯機制,或應用程式的歷程紀錄。

