
『如果工作流程很複雜,任務的相依性很高,Airflow 還是能實現嗎?』
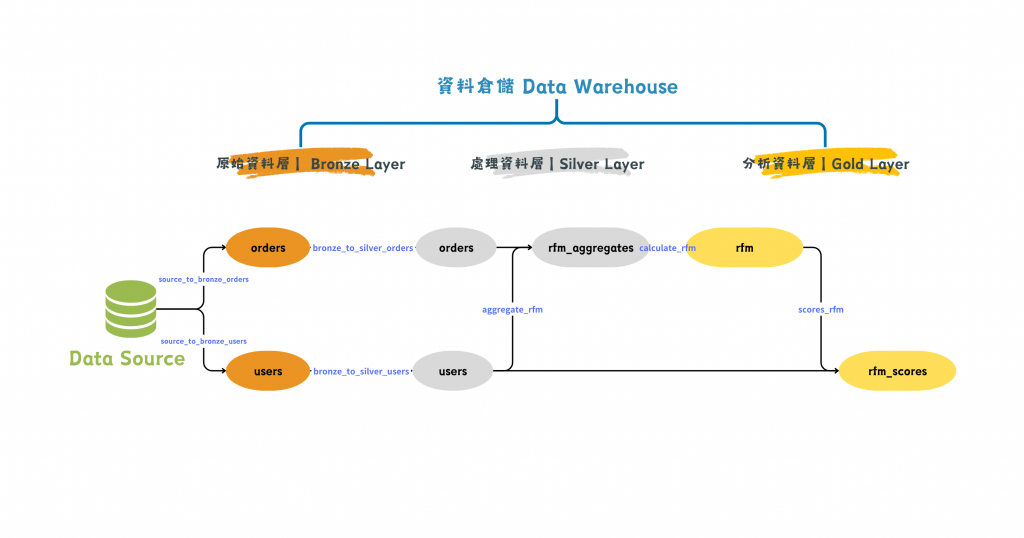
圖/一個 DAG 完成 RFM 分析。簡書廷製。
我們以 Day 06 提到的 RFM 模型來說明吧!節點 (node) 表示資料表,連線 (link) 表示一段資料轉換 (transformation) 的任務。
如果把這所有的任務透過一個 DAG 完成,任務相依性會長得像這樣:
...
(
[source_to_bronze_orders, source_to_bronze_users]
>> [bronze_to_silver_orders, bronze_to_silver_users]
>> aggregate_rfm
>> calculate_rfm
>> score_rfm
)
這是一個好的相依性設計嗎?
Airflow 官方文件的 Best Practices 提到,雖然 Airflow 能夠支援彈性且大量的 DAG,但若有太多過於複雜的 DAG,會降低排程系統的效能,應該要「降低 DAG 複雜性 (Reducing DAG complexity)」。
針對 DAG 複雜度,雖然官方文件提到沒有明確指標 (metrics) 可以評估,但文件揭示了一些設計準則。
提升載入 DAG 的速度:簡言之是讓 DAG 專注於定義排程與任務相依性,Task 才去撰寫任務本身的邏輯及引入套件等。
保持 DAG 本身的結構簡單: A -> B -> C 的線性結構會比複雜的巢狀樹 (nested tree) 來得更好,因為同時運行的任務會比較少。
看起來,我們目前的設計可以進一步拆解。
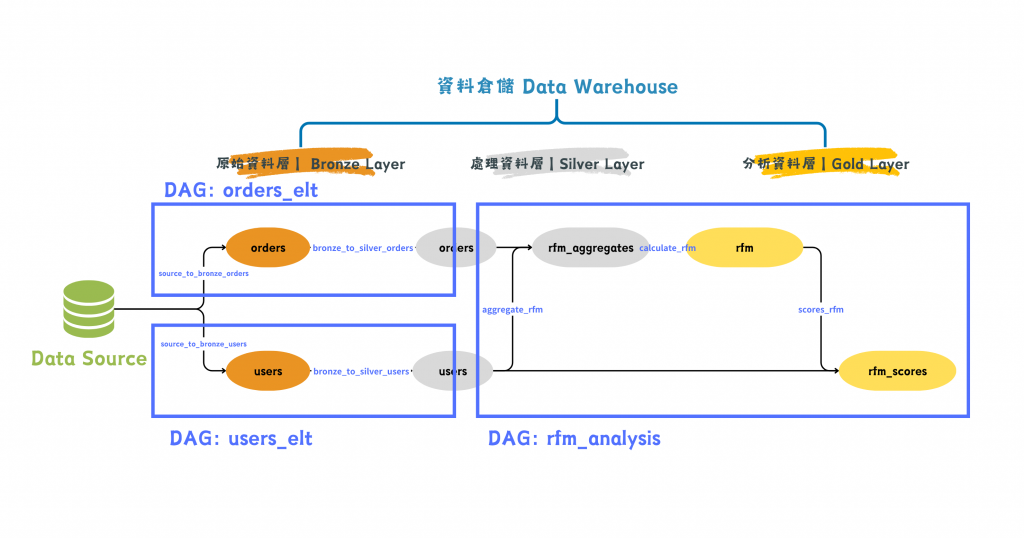
圖/多個 DAG 完成 RFM 分析。簡書廷製。
我們把 orders 和 users 的 ELT 流程分別拆成兩個 DAG,最後一個 DAG 則專心處理 RFM 分析的轉換。
在 DAG 層級的設計,程式碼模組化的理念依然適用,在此案例下 ELT 任務與分析任務也被分離,兼顧了效能與易讀性。不過新的問題衍生了:如何確保前面資料源的 ELT 流程都完成了,才進行 RFM 分析的執行?
新的課題是跨 DAG 間的相依性設計。有幾個可能的解法都能夠在 Airflow UI 上產出相依關係線圖,讓我們一一探討。
ExternalTaskSensor 是一個內建於 Airflow 中的感應器 (sensor),用於等待另一個 DAG 中的特定任務完成。這是處理跨 DAG 相依性最直接的方法。程式碼如下:rfm_analysis.py
from airflow.sensors.external_task import ExternalTaskSensor
with DAG(
dag_id='rfm_analysis'
...
):
wait_for_orders = ExternalTaskSensor(
task_id='wait_for_orders',
external_dag_id='orders_elt',
external_task_id='bronze_to_silver_orders'
)
wait_for_users = ExternalTaskSensor(
task_id='wait_for_users',
external_dag_id='users_elt',
external_task_id='bronze_to_silver_users'
)
[wait_for_orders, wait_for_users] >> aggregate_rfm >> ...
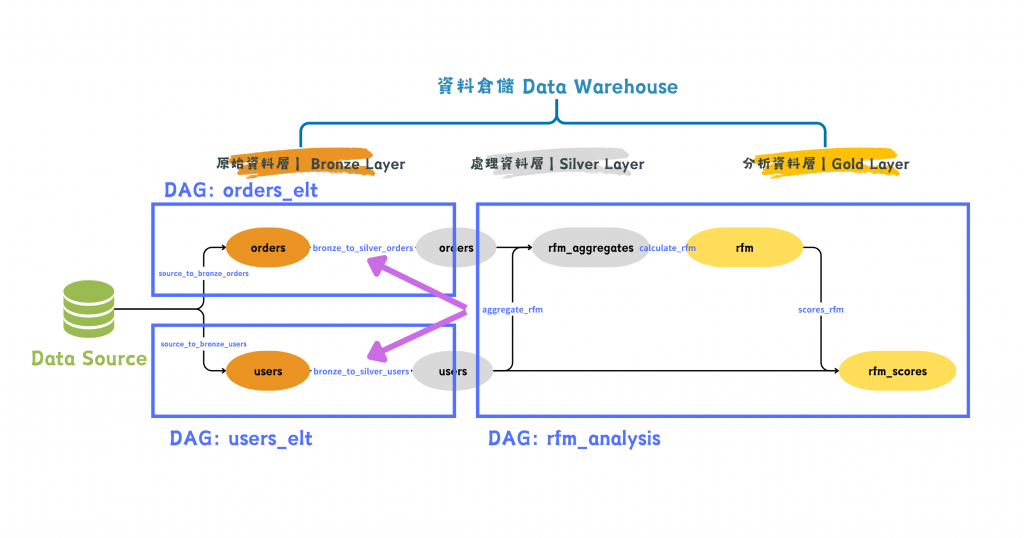
圖/透過 Sensor 串接多個 DAG 完成 RFM 分析。簡書廷製。
透過 ExternalTaskSensor 的持續感應,直到指定的任務都完成之後,再進行 aggregate_rfm 這個任務,就能達成一樣的效果!
優點
缺點
TriggerDagRunOperator 是另一個處理 DAG 之間相依的方法。這個執行單位可以用在一個任務完成後即刻觸發另一個 DAG 的執行。例如我們希望在 DAG: orders_elt 的工作流程觸發 DAG: rfm_analysis,就可以用以下程式碼達成。
orders_elt.py
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
with DAG(
dag_id='orders_elt'
) as dag:
trigger_dag = TriggerDagRunOperator(
task_id='trigger_rfm',
trigger_dag_id='rfm_analysis',
)
不過觸發器和感應器是恰好相反的做法,觸發器可以一個上游對多個下游。如果我們做成這樣的設計,是沒辦法保證 orders 和 users 資料都完整走完 ELT 流程才進行下游分析的。
優點
缺點
Airflow 2.4 引入了一個新的方法來處理跨 DAG 相依性,稱為資料集(Dataset)機制。它的運作方式是在 DAG 任務之間共享資料集,並且在資料集被更新時,自動觸發相依於該資料集的 DAG。這個方法是基於 data pipeline 中資料變化的概念來建立相依性,而不再仰賴 DAG 任務或 DAG 執行狀態。
根據我們對資料上下游關聯的理解,引入 Dataset 的概念可以將 DAG 的相依設計改寫成這樣:
from airflow import DAG
from airflow.datasets import Dataset
from airflow.providers.google.cloud.operators.bigquery import (
BigQueryInsertJobOperator
)
silver_orders = Dataset("bigquery:///project/silver/orders")
silver_users = Dataset("bigquery://project/silver/users")
with DAG(
dag_id="orders_elt",
) as dag:
bronze_to_silver_orders = BigQueryInsertJobOperator(
task_id="bronze_to_silver_orders",
outlets=[silver_orders],
)
with DAG(
dag_id="users_elt",
) as dag:
bronze_to_silver_users = BigQueryInsertJobOperator(
task_id="bronze_to_silver_users",
outlets=[silver_users],
)
with DAG(
dag_id="rfm_analysis",
schedule=[silver_orders, silver_users],
) as dag:
rfm_analysis = BigQueryInsertJobOperator(
task_id="rfm_analysis",
)
優點
缺點
Airflow 有多種方法來處理跨 DAG 間的相依性設計。
在運用 Airflow 作為任務編排器 (Orchestrator) 建構 data pipeline 時,別忘了最重要的目標是確保「資料正確性」。

