此章節解說部分常用的語法。
"h32rb17" 的每個字元和其對應的索引如下:
字元: h 3 2 r b 1 7
索引: 0 1 2 3 4 5 6
字元: h 3 2 r b 1 7
索引: -7 -6 -5 -4 -3 -2 -1
device_id = "h32rb17"
print(device_id[0]) # 輸出 h
print(device_id[0:3]) # 輸出 h32
str():將輸入轉換為字串。
string_id = str(19329302) # 將整數轉換為字串
len():傳回字串中的元素數量。
device_id_length = len("h32rb17")
if device_id_length == 7:
print("The device ID has 7 characters.")
.upper():將字串中的所有字母轉換為大寫字母。
print("Information Technology".upper()) # 輸出 INFORMATION TECHNOLOGY
.lower():將字串中的所有字母轉換為小寫字母。
print("Information Technology".lower()) # 輸出 information technology
.index():尋找字串中第一次出現的字元或子字串,並傳回其索引。
print("h32rb17".index("r")) # 輸出 3
.index() 尋找子字串:可以用來尋找子字串的第一次出現位置。
tshah_index = "tsnow, tshah, bmoreno - updated".index("tshah")
print(tshah_index) # 輸出 7
str():將輸入轉換為字串。len():返回字串的長度。.upper():將字串中的所有字母轉為大寫。.lower():將字串中的所有字母轉為小寫。.index():尋找字串或子字串的第一次出現並傳回其索引。[] 包裹,並且項目之間用逗號 , 分隔。
my_list = ["A", "B", "C", "D", "E"]
0 開始計算,負索引從 -1 開始。
my_list = ["A", "B", "C", "D", "E"]
print(my_list[1]) # 輸出 "B"
my_list[1] 表示列表中的第二個元素。print(my_list[0:3]) # 輸出 ["A", "B", "C"]
+ 可以將兩個列表合併為一個新的列表。
my_list1 = ["A", "B", "C"]
my_list2 = [1, 2, 3]
combined_list = my_list1 + my_list2
print(combined_list) # 輸出 ["A", "B", "C", 1, 2, 3]
my_list = ["A", "B", "C"]
my_list[1] = 7 # 將第二個元素 "B" 改為 7
print(my_list) # 輸出 ["A", 7, "C"]
insert()insert() 方法:將新元素插入到指定位置,該方法的第一個參數為索引,第二個參數為要插入的元素。
my_list = ["A", "B", "C"]
my_list.insert(1, 7) # 在索引 1 處插入數字 7
print(my_list) # 輸出 ["A", 7, "B", "C"]
remove()remove() 方法:刪除列表中第一次出現的特定元素。
my_list = ["A", "B", "C", "D"]
my_list.remove("D") # 刪除元素 "D"
print(my_list) # 輸出 ["A", "B", "C"]
remove() 直接根據值刪除,而不是索引。malicious_ips = ["192.168.1.1", "10.0.0.2"]
malicious_ips.append("172.16.0.3") # 新增一個新的 IP
print(malicious_ips) # 輸出 ["192.168.1.1", "10.0.0.2", "172.16.0.3"]
"198.567",我們可以通過字串切片來提取前三位數字。
address = "198.567"
print(address[0:3]) # 輸出 "198"
address[0:3] 提取索引 0 到 2 的字元,索引 3 是切片的結束位置,但不包括在內。append() 方法:將提取的前三位數字新增到一個新列表中。
append() 方法的作用是將元素新增到列表末尾。ip_list = ["198.567", "123.456", "156.789"]
network_list = []
for address in ip_list:
network_list.append(address[0:3])
print(network_list) # 輸出 ['198', '123', '156']
network_list = []:這個列表用來存儲每個 IP 位址提取出的前三位數字。for 迴圈遍歷列表for address in ip_list::這行程式碼告訴 Python 我們要開始一個循環,並逐一處理 ip_list 中的每個 IP 位址。
address 會暫時存儲當前的 IP 位址。network_list.append(address[0:3]):使用字串切片來提取 IP 位址的前三位數字,並使用 append() 將其新增到 network_list 中。print(network_list):輸出包含每個 IP 位址前三位數字的新列表。append() 方法 是將元素新增到列表末尾的重要工具。remove() 方法remove() 方法:從列表中刪除第一次出現的指定元素。注意,該方法僅刪除元素的第一個實例。
username_list = ["elarson", "bmoreno", "wjaffrey", "tshah", "sgilmore"]
print("Before removing an element:", username_list)
username_list.remove("elarson") # 刪除 "elarson"
print("After removing an element:", username_list)
在刪除元素之前: ['elarson', 'bmoreno', 'wjaffrey', 'tshah', 'sgilmore']
刪除元素後: ['bmoreno', 'wjaffrey', 'tshah', 'sgilmore']
重要提示:如果列表中有多個相同的元素,remove() 方法僅會刪除第一次出現的那個元素,而不會刪除所有的實例。
append() 方法append() 方法:將新元素添加到列表的末尾。此方法對列表進行原地修改,不影響已有元素的順序。
username_list = ["bmoreno", "wjaffrey", "tshah", "sgilmore"]
print("Before appending an element:", username_list)
username_list.append("btang") # 將 "btang" 加入列表末尾
print("After appending an element:", username_list)
在追加元素之前: ['bmoreno', 'wjaffrey', 'tshah', 'sgilmore']
追加元素後: ['bmoreno', 'wjaffrey', 'tshah', 'sgilmore', 'btang']
應用場景:append() 方法經常與 for 迴圈結合使用來填充空列表。
for 迴圈填充列表
numbers_list = []
print("Before appending a sequence of numbers:", numbers_list)
for i in range(10):
numbers_list.append(i) # 將 0 到 9 加入列表
print("After appending a sequence of numbers:", numbers_list)
在附加數字序列之前: []
加入數字序列後: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
index() 方法index() 方法:傳回列表中第一次出現的指定元素的索引。
username_list = ["bmoreno", "wjaffrey", "tshah", "sgilmore", "btang"]
username_index = username_list.index("tshah") # 查找 "tshah" 的索引
print(username_index) # 輸出 2
2
注意:如果列表中有重複的元素,index() 方法只會返回該元素第一次出現的位置。
remove() 方法:刪除列表中的第一次出現的指定元素。append() 方法:在列表的末尾添加新元素。index() 方法:返回指定元素的第一次出現的索引。.index() 方法同樣存在於字串和列表中,但它們是針對不同的資料類型而定義的。這些列表操作是處理資料集合的基本方法,尤其在安全分析等領域,列表操作可以幫助管理和處理大批量的數據。
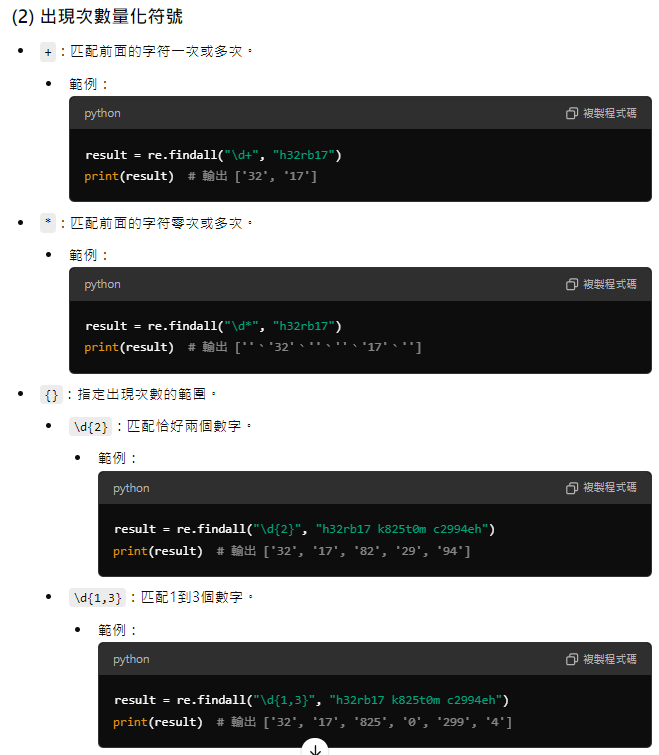
+)+):匹配前面的字元一次或多次出現。
a+ 匹配一個或多個連續的 "a"。import re
device_ids = "a aa aaa aaaa"
matches = re.findall(r"a+", device_ids)
print(matches) # 輸出 ['a', 'aa', 'aaa', 'aaaa']
\w:匹配任何字母、數字或底線字符(但不包括符號)。
\w 可以匹配 "1", "k", "i" 等字元。text = "abc123!@#"
matches = re.findall(r"\w+", text)
print(matches) # 輸出 ['abc123']
\w+:匹配任意長度的字母數字字串。這是常見的正規表示式組合,能夠匹配變長的字母數字序列。
text = "192 abc123 security"
matches = re.findall(r"\w+", text)
print(matches) # 輸出 ['192', 'abc123', 'security']
@ 符號 + 網域名 + . 符號 + 領域(如 com, net 等)。\w+:匹配字母數字字符序列(用於匹配電子郵件的前半部分和網域名部分)。@:匹配 @ 符號。\.:匹配 . 符號,因為 . 在正規表示式中有特殊含義,因此需要加反斜線來進行轉義。\w+@\w+\.\w+
範例:提取日誌中的電子郵件地址。
import re
email_log = """
user1@email1.com
user2@email2.net
notAnEmail@random
"""
email_pattern = r"\w+@\w+\.\w+"
emails = re.findall(email_pattern, email_log)
print(emails) # 輸出 ['user1@email1.com', 'user2@email2.net']
Python 中的 re 模組提供了正規表示式的支持。最常用的方法是 re.findall(),它會傳回所有符合正規表示式的匹配結果。
範例
import re
text = "Here are some emails: user1@example.com, user2@domain.org"
pattern = r"\w+@\w+\.\w+"
matches = re.findall(pattern, text)
print(matches) # 輸出 ['user1@example.com', 'user2@domain.org']
re 模組要搜尋的字串。
範例:
import re
result = re.findall("ts", "tsnow, tshah, bmoreno")
print(result) # 輸出 ['ts', 'ts']
\d:匹配任何單一數字 (0-9)。
\s:匹配任何單一空格字符(包括空格、tab等)。
.:匹配任何字符(包括符號)。
範例:
import re
device_id = "h32rb17"
result = re.findall("\w", device_id)
print(result) # 輸出 ['h', '3', '2', 'r', 'b', '1', '7']
使用 \d 搜尋字串中的所有數字:
result = re.findall("\d", device_id)
print(result) # 輸出 ['3', '2', '1', '7']