前幾天我們分析並且測試了一個名為 ControlCom 的模型,今天再來繼續測試一個名為 AnyDoor 的開源模型!來看看目前一體化模型可以做到什麼樣的程度吧!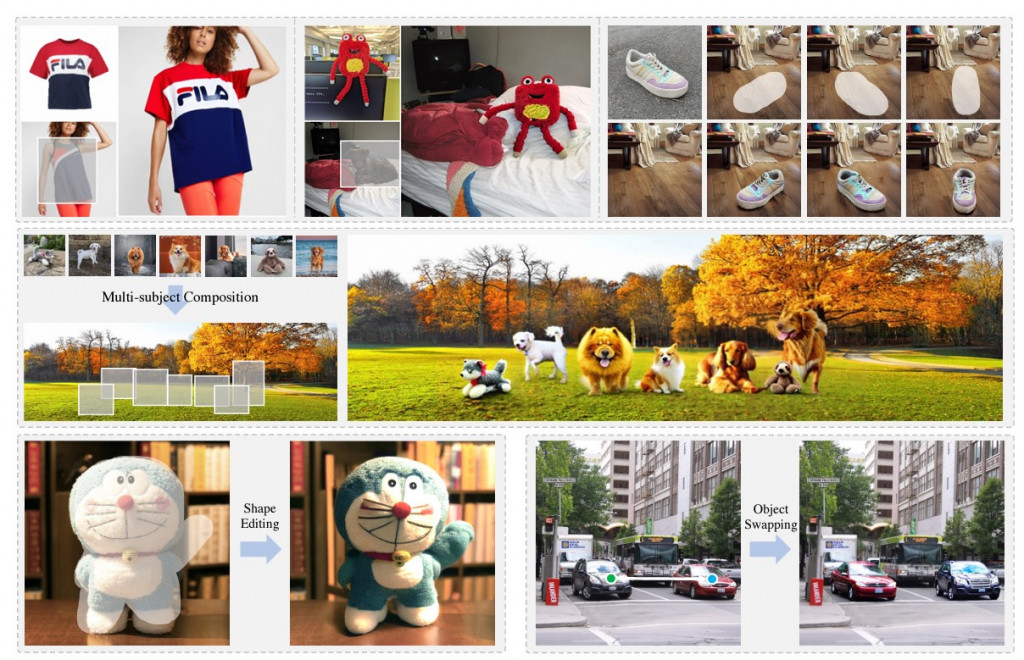
AnyDoor 是一種基於擴散(Diffusion)模型的先進圖像生成器,專為物件級圖像定制而設計。它的核心功能是將特定物件「瞬移」到使用者指定的場景中,並能夠控制其在場景中的形狀和位置。與其他需要大量訓練來適應新物件的模型不同,AnyDoor 可以在零樣本(zero-shot)的情況下實現圖像定制,這使它在真實世界應用中具有極高的靈活性和高效性,比如圖像合成、虛擬試穿和物件交換等應用。
AnyDoor 的獨特之處在於,它不僅可以將物件放入新場景,還能在保持物件身份特徵(如質感、光照、姿勢)的同時,讓物件與周圍環境無縫融合。這意味著它不僅是簡單地「剪貼」物件,而是能夠智能地調整物件以符合新場景的光線、視角和背景。
那AnyDoor是怎麼做到的呢?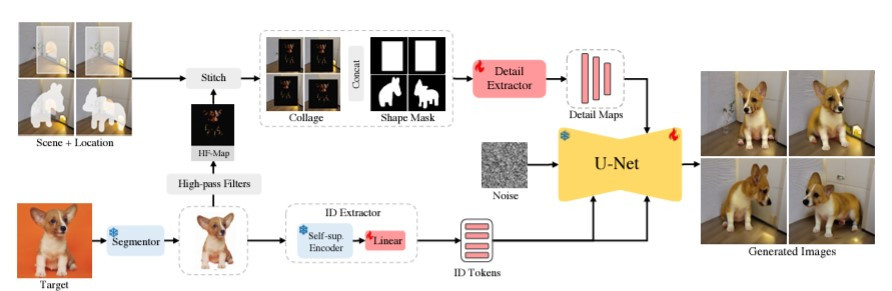
主要有四大步驟:
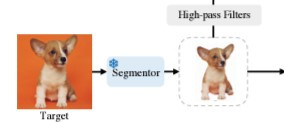
在 AnyDoor 開始生成圖像之前,它首先需要從目標物件的圖像中去除背景。這一步驟通常是透過分割模型(例如 SAM 模型)來實現的。背景移除後,物件會被置中處理,以便更好地提取物件的身份特徵。
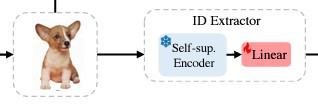
為了確保物件在新的場景中保持其獨特性,AnyDoor 會提取物件的身份特徵。這部分使用的是一個預訓練的自監督模型(DINOv2),該模型具備強大的區分性,能夠精確地保留物件的形狀、紋理、結構等身份信息。
而 DINOv2 生成的身份特徵分為全局標記(global token)和局部標記(patch token)。全局標記捕捉物件的整體結構,而局部標記則關注細節部分。這兩類特徵會被合併以提供更加豐富的識別信息。
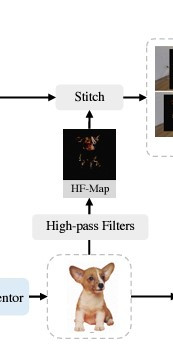
雖然上方提到的身份特徵提供了物件的整體結構,AnyDoor 還需要進一步提取物件的細節來補充生成過程中的缺失部分。這部分使用了一個稱為「高頻率圖」的技術。
AnyDoor 利用 Sobel 邊緣檢測濾波器來生成高頻率圖,這些圖像保留了物件的細微細節,例如紋理、光照和方向等資訊,並允許局部變化。這樣能夠確保物件在場景中自然融合,避免顯得突兀或不真實。
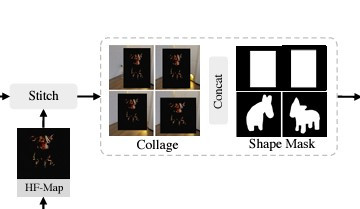
在物件放入場景前,AnyDoor 允許使用者提供簡單的形狀遮罩(mask),以控制物件的形狀和姿勢。這樣的控制能夠模擬使用者對物件的手動調整,讓物件的最終姿勢符合場景需求,從而實現更高的自定義效果。
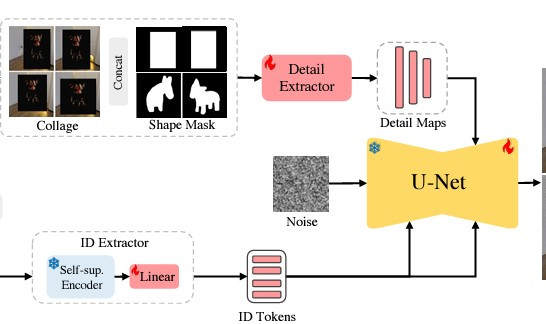
一旦身份特徵和細節特徵都被提取出來,這些特徵會被注入到預訓練的擴散模型(Stable Diffusion)中。擴散模型是一種能夠從噪聲逐步生成清晰圖像的模型,AnyDoor 利用這一模型來處理物件與場景的融合。模型從初始的噪聲開始,逐層對圖像進行去噪,直到生成最終的圖像。在每一層,身份標記和細節圖會被注入到模型中,用來指導圖像生成,使得最終生成的物件既符合場景,又保留物件的核心特徵。
在理解所有的流程後你可以在他們的網站上進行測試。
點我
要怎麼測試呢?首先你可以選擇你想要合成的背景還有物品,接著記得要塗滿你要合成的地方以及合成的物品,這樣你就可以得到一張下方的圖!
是不是感覺蠻好玩的~快去試試看吧!
https://arxiv.org/abs/2307.09481


 iThome鐵人賽
iThome鐵人賽