
上次我們介紹了「ControlCom 影像合成模型」在實作時發現在我們的測試中還是有許多不合理的部分。像是我們僅僅單純是將一瓶原萃合成在一個簡單的平面上,但是在包裝的還原上非常差,可以看到下圖。
因此我們的方向目前想要去更改重新訓練一個我們自己的模型,所以又開始了文獻探討的工作,這邊因為我們對於 ControlCom 的架構其實評價還不錯,因此開始查找相關論文看到了這篇 IMPRINT 或許對於我們的目標是個不錯的參考~
這篇論文主要是由 Adobe 的研究團隊於2024年3月15日發表,該模型為一個基於 Diffusion 模型生成模型,特點在於它的 Two Stage 學習框架,具體是怎麼做的呢?我們先來看他的架構圖。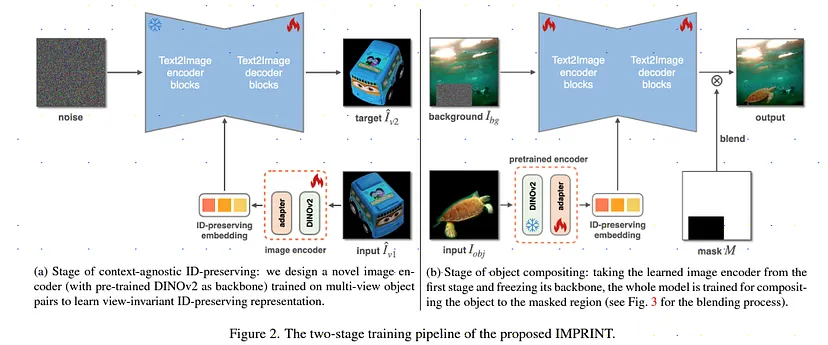
左邊的話是 Stage 1 它的作用在於利用不同角度的輸入圖來對訓練資料做增強,這樣子的好處是可以更有效地捕捉物體的特徵,並為後續的合成階段奠定基礎。而右邊的 Stage 2 主要是圖像合成的部分,將整個圖像合成至整個圖像。
方法的部分我們持續針對上方提到的 Stage 1 以及 Stage 2 去進行深入的探討。
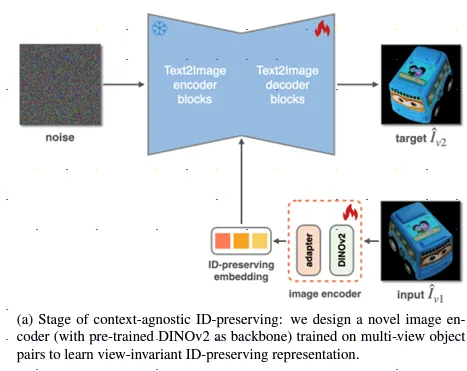
作者們的靈感來源源自於目前的許多研究都有支持幾何和諧傾向於展現複製粘貼,另外在物體特徵的保留與圖像合成之間存在著一個根本的權衡,物體會在顏色、光影以及形狀上有所改變以更好的融入背景。而同時,物體的原始姿勢、色調和照明效果則會被模型記住並定義其外觀。
雖然多重視角可以在保留物體特徵上有重要的表現但是這樣子的資料集通常成本高昂並且資料品質不夠好(Ex.沒有背景...)因此作者們透過 Stage 1 給定一個物品兩個視角以及它們的遮罩。
Image Encoder模型:此模型是使用由 Meta 開發之 DINOv2 模型, DINOv2 可以從圖像中提取高品質的特徵界,另外在 Text to Image 模型 T2I 中間有個內容適配器,這個適配器參考了 ObjectStitch 論文中的方法。
這裡針對 ObjectStitch 論文中內容適配器的資訊做一個簡單的介紹,在論文中作者提到
「為了防止關鍵身份信息的丟失,我們使用圖像編碼器而非文本編碼器,來從輸入的物體圖像生成嵌入。然而,圖像嵌入無法有效地被擴散模型利用」
這邊的原因有兩點:
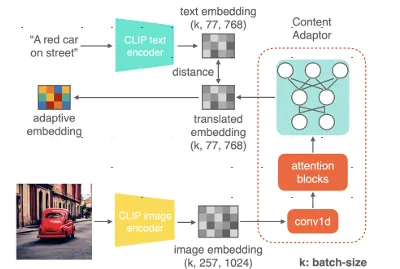
Image Decoder模型:圖像的解碼器來自於 Stable Diffusion 模型中的conditional denoising autoencoder,並且它們在訓練過程中對解碼器進行了微調(fine tune)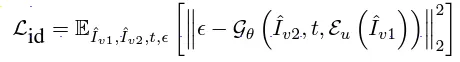
這邊的損失函數目標在於最小化原始圖像以及生成圖像之間的差異,特別是針對原始物品的相關細節,可以看到[框框]中使用了預測的預測的噪音與解碼器(Decoder)生成的噪音之間來定義損失。在這個過程中,圖像編碼器 Eu 和解碼器塊 Gθ 會同時被優化,以確保模型在保持原始物品細節的同時,能夠從不同視角提取一致的表現。
這個模型的特點在於可以保留物體的細節並且不需要 3d 的資訊,所以不用像是用我們之前的作法是依靠相機拍攝等外部資訊。並且模型的重點放在保持物品的還原度而不是幾何的一致性。
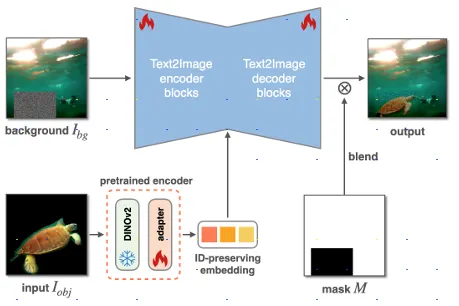
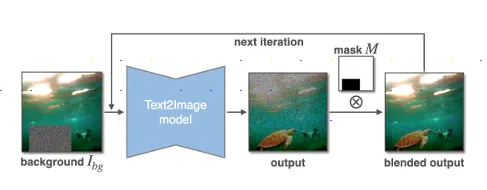
上方這張圖為 Stage 2 的流程,此模型最主要的功能在於將圖片合成進背景圖,但經過作者的實驗若是忽略視角合成直接將編碼器和生成器在在同一個框架下共同訓練會造成兩者品質的下降,因此選擇凍結了模型的主要部分(DINOv2)也就是說 encoder 的權重不會改變,從而保持在 Stage 1 學到的能力以及穩定性。並且它們收集了一個全新的訓練集。
這邊的新的訓練集作者提到此資料集包含了豐富的背景,這樣的方法可以讓模型去學習豐富的光影以及幾何變化。而這資料集主要是來自 Pixabay 或是影像分割數據集(YoutubeVOS、VIPSeg 和 PPR10K)以及以物體為中心的數據集(MVImgNet和 Objaverse)這些數據集在我們的自監督訓練中被應用於不同的訓練階段,並結合了各種處理流程。
生成器模型:這裡使用T2I模型作為生成器的主幹。而模型的 Input 為背景圖以及要合成的粗略遮罩用來標記物體的位置,以及保持物體身份信息的代碼,由圖像編碼器生成,用於指示被遮罩的物體圖像 。並將物體代碼注入到生成器的交叉注意力層中,這有助於模型在生成圖像時更好地保持物體的身份特徵(如形狀、姿態等)。而模型的目標函數如下: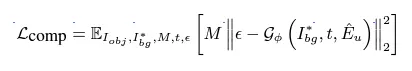
其中可以看到此目標為最小化生成圖像與目標圖像之間的差異,而 ϵ 代表隨機噪聲, M 是遮罩,用來標記需要關注的區域。這個過程中,生成器 Gϕ 和適配器會根據損失函數進行優化。
在背景融合的部分,為了使得背景接合處平滑採用了背景融合策略。這意味著在物體與背景交界處進行特殊處理,以避免明顯的邊界或不連續性,從而提升合成效果。以及透過形狀引導的可控合成 (Shape-guided Controllable Compositing)的方式通過繪製粗略的遮罩來控制生成物體的姿態和視角,使生成過程更靈活、實際。
模型也引入了四種不同精度的遮罩,其中最粗略的是邊界框。這樣的設計模擬了真實場景中用戶的需求,尤其是當需要更精確地控制物體位置和形狀時。


可以看到相較於其他的模型, IMPRINT 模型融合得更加地自然,只是最可惜的是此模型沒有進行開源因此我們用不到,不過此架構方法對於我們在最圖像合成是非常有價值的!
ObjectStitch: Object Compositing with Diffusion Model
IMPRINT: Generative Object Compositing by Learning Identity-Preserving Representation

