昨天
我們介紹介紹了python的Class的建立方法
今天我們會詳細介紹,物件導向的特性(用python實作)
1.封裝Encapsulation.
2.繼承Inheritance.
3.多型Polymorphism.
| 特性 | 優點 | 缺點 | 使用場景 |
|---|---|---|---|
| 封裝 | 提高安全性、可維護性和模組化 | 封裝過多會增加程式的複雜性 | 資料隱藏、保護敏感資訊 |
| 繼承 | 代碼重用、高效維護 | 繼承結構複雜時難以理解,子類與父類耦合緊密 | 建立層次化的物件模型 |
| 多型 | 增強靈活性和可擴展性,提供抽象層次 | 使用過多會增加程式的調試難度和執行時間 | 需要不同類別有相同介面但不同行為時 |
介紹完特性之後會帶範例讓大家更理解物件導向的使用場景。
畢竟我是圖片控,我會盡量用流程或架構的圖讓大家理解Class
封裝(Encapsulation)是物件導向程式設計中的一個核心概念。它的主要目的是將資料(屬性)和行為(方法)封裝在一起,並且對外部程式隱藏物件的內部實現細節,只提供外部所需的介面。這樣可以增強程式的安全性和可維護性。
封裝的另一個好處是可以限制對物件內部屬性的直接訪問,並透過設置特定的 getter 和 setter 方法來控制屬性的讀取和修改,這樣可以確保物件內部狀態的正確性。
1.今天我是一間公司老闆,我需要定義employee class
2.那們員工就會有salary屬性
3.薪水在公司裏面是機密資料所以需要定義私有屬性跟方法
4.透過前面的特性來實作getter(取得薪水) setter(設定薪水) 來操作
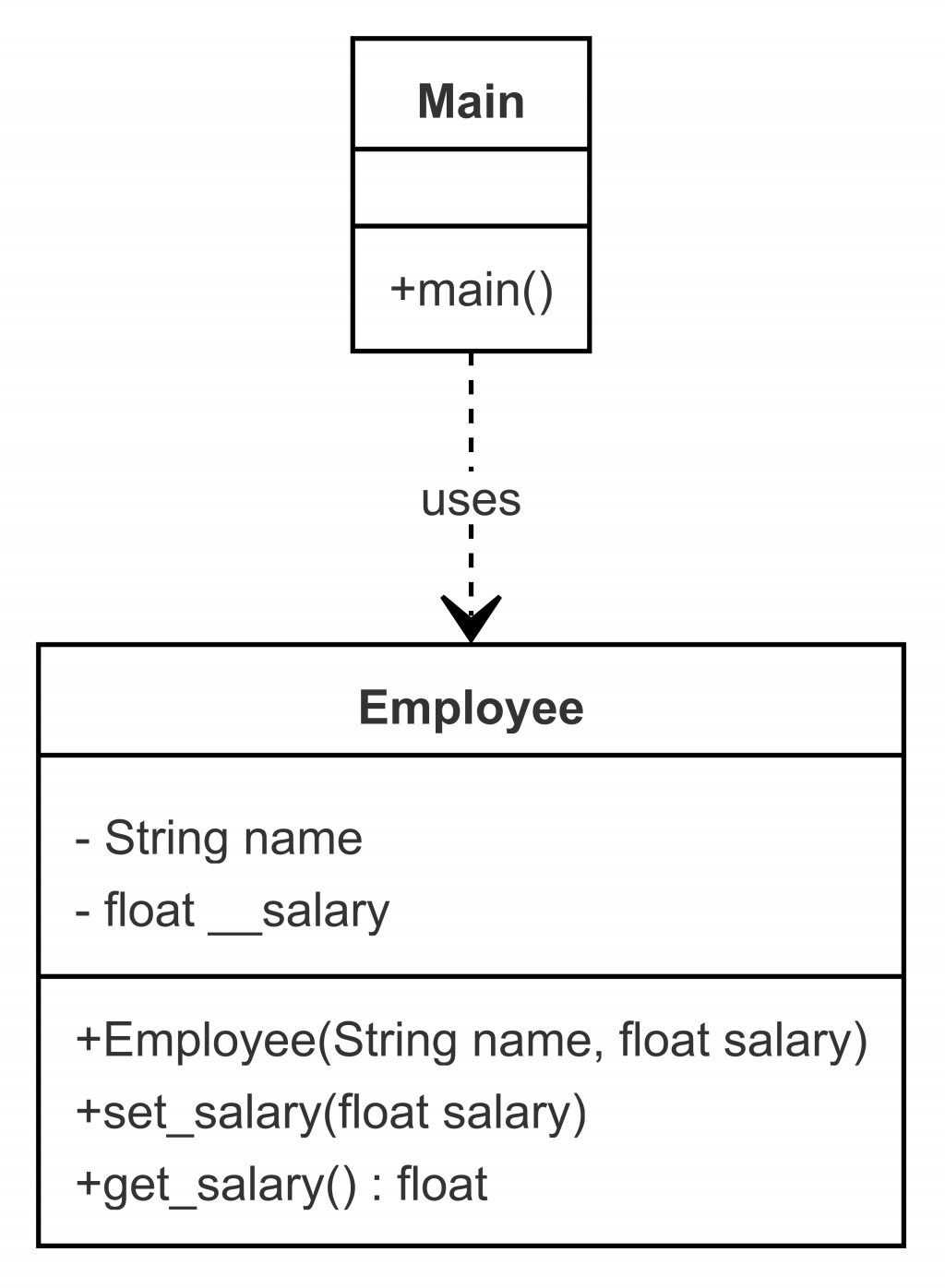
class Employee:
def __init__(self, name, salary):
self.name = name
self._salary = salary # 使用私有屬性保存薪水數值
# 使用 property 修飾詞來定義 getter 方法
@property
def salary(self):
return self._salary
# 使用 setter 修飾詞來定義 setter 方法
@salary.setter
def salary(self, value):
if value < 0:
raise ValueError("薪水不能為負數") # 設定薪水時檢查合理性
self._salary = value # 如果合理,則更新薪水
def display_info(self):
print(f"員工: {self.name}, 薪水: {self.salary}")
# 使用範例
emp = Employee("Alice", 5000) # 初始化一位員工 Alice,薪水為 5000
emp.display_info() # 輸出: 員工: Alice, 薪水: 5000
emp.salary = 6000 # 使用 setter 更新薪水
emp.display_info() # 輸出: 員工: Alice, 薪水: 6000
# emp.salary = -1000 # 如果嘗試設定負值,會引發 ValueError
修改點解釋:
@property:把 salary 方法變成屬性,讓它看起來像是在直接訪問 salary,但實際上會調用 getter 方法。
@salary.setter:當您嘗試修改 salary 時,會自動調用這個 setter 方法。在這裡,我們可以做一些邏輯檢查,例如防止薪水設定為負數。
self._salary:
使用了以 _ 開頭的變數名,代表這是一個「私有屬性」。通常這只是約定俗成的規範,用來表示該變數不應該在類別外部直接訪問。
通過封裝的優點:
封裝是保證類的內部狀態不被外部代碼隨意破壞的關鍵手段。
2.範例
原本函數加上修飾詞
@decorator_name
def function_to_decorate():
# 函數內容
同等於
def function_to_decorate():
# 函數內容
function_to_decorate = decorator_name(function_to_decorate)
總結1.語法位置:修飾詞通常加在函數或方法的前面。2.功能:修飾詞可以用來添加額外功能,如日誌記錄、性能測試、授權檢查等。3.簡化代碼:使用修飾詞可以使代碼更簡潔,並提高可讀性和可維護性。
這使得 Python 的修飾詞成為一個非常強大且靈活的編程工具。 => 也有類似Java annotations的概念
定義: 簡單來說就是把父類別的屬性跟方法繼承下來使用
這邊會有幾個需求點
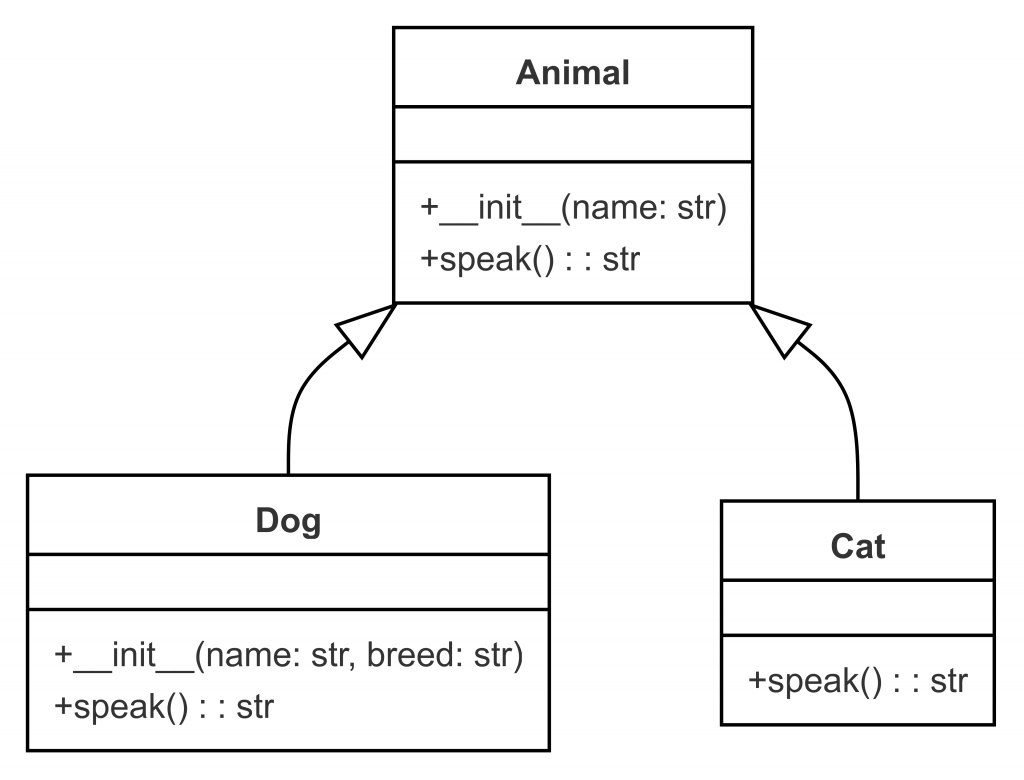
# 定義父類別 Animal
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
return "Some sound"
# 定義子類別 Dog 繼承自 Animal
class Dog(Animal):
def __init__(self, name, breed):
super().__init__(name) # 使用 super() 調用父類別的 __init__ 方法
self.breed = breed
def speak(self):
return "Woof!"
# 定義子類別 Cat 繼承自 Animal
class Cat(Animal):
def speak(self):
return "Meow!"
# 使用示例
dog = Dog("Rex", "Labrador")
cat = Cat("Whiskers")
print(f"{dog.name} is a {dog.breed} and says: {dog.speak()}") # 輸出: Rex is a Labrador and says: Woof!
print(f"{cat.name} says: {cat.speak()}") # 輸出: Whiskers says: Meow!
tips 拆解繼承語法
繼承的語法:在定義子類別時,父類別寫在小括號中。
class Child(Parent):
pass
在子類別的 __init__ 方法中,可以直接使用 self 關鍵字來新增屬性。
通常使用 super() 來初始化父類別的屬性,以確保父類別的初始化邏輯被執行。
class Animal:
def __init__(self, species):
self.species = species
class Dog(Animal):
def __init__(self, name, breed):
super().__init__('Dog') # 初始化父類別屬性
self.name = name
self.breed = breed
3.python繼承父屬性的方法super()
基本概念:super() 是一個內建函數,用於呼叫父類別的方法或屬性。
使用情境:當你想要在子類別中重用父類別的方法時,可以使用 super(),這樣可以避免直接使用父類別名稱,讓程式碼更靈活且易於維護。
class Parent:
def __init__(self, name):
self.name = name
class Child(Parent):
def __init__(self, name, age):
super().__init__(name) # 呼叫父類別的 __init__ 方法
self.age = age
定義: 允許不同類別的物件以相同的介面進行操作。這意味著不同類別可以定義相同的方法名稱,但具體的行為會依據物件的類別而有所不同。
白話文就是: 雖然貓咪跟狗狗都是動物,但是叫聲卻不同
直接以上面貓咪跟狗狗的舉例就是
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
return "Woof!"
class Cat(Animal):
def speak(self):
return "Meow!"
# 使用多型
def animal_sound(animal):
print(animal.speak())
# 創建物件
dog = Dog()
cat = Cat()
# 呼叫 animal_sound 函數,根據物件類別呼叫對應的 speak 方法
animal_sound(dog) # 輸出: Woof!
animal_sound(cat) # 輸出: Meow!
這邊就是實作了物件導向多型的概念
貓咪跟狗狗的叫聲都不同~
總結:
1.小專案:不一定需要使用類別,可以用簡單的函數解決問題。
2.大專案:類別設計是很常見且必要的,幫助你更好地組織和管理代碼。
3.OOP 的設計原則在實際應用中能讓程式碼更具可讀性、可維護性、以及擴展性。
在網頁程式開發中,如果你只需要從前端接收數據並插入到資料庫,理論上你可以不使用類別(class)來處理。你可以直接通過 SQL 語法或資料庫操作來插入資料。
比如說我只操作CRUD塞資料進資料庫
step1接收來自前端的數據
product_name = request.form['name']
product_price = request.form['price']
step2直接執行資料庫插入操作
cursor.execute("INSERT INTO products (name, price) VALUES (%s, %s)", (product_name, product_price))
conn.commit()
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Product(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(80), nullable=False)
price = db.Column(db.Float, nullable=False)
def __init__(self, name, price):
self.name = name
self.price = price
# 插入數據
new_product = Product(name="Laptop", price=999.99)
db.session.add(new_product)
db.session.commit()
優點:1.可維護性:ORM 自動處理資料庫操作,省去寫大量 SQL 語句的麻煩。當資料庫結構變化時(如修改表結構),你只需修改類別定義,ORM 會自動適應變更。2.安全性:ORM 能自動處理 SQL 注入問題,減少手動處理 SQL 的風險。3.跨資料庫兼容:不同資料庫系統有不同的 SQL 語法,但使用 ORM 可以讓程式碼在不同的資料庫間移植時不需要改變 SQL 語句。
以今天要新增一個product範例的話:
| 何時應該使用 Class? | 解釋 |
|---|---|
| 業務邏輯複雜 | 商品除了 name 和 price 外,還有更多屬性(如分類、庫存、促銷等),這些屬性之間有邏輯關聯。類別幫助封裝這些屬性和行為。 |
| 數據操作頻繁 | 當需要頻繁進行數據操作(查詢、更新、刪除等),ORM 工具能簡化這些操作,不必每次重寫 SQL 語句。 |
| 擴展性 | 在未來項目擴展時,類別更容易支持新增功能、增加屬性,維持程式碼結構清晰性。 |
| 模組化設計與重用 | 如果系統需要模組化設計(如電商的「訂單」、「用戶」、「商品」等模組),類別能更好地進行封裝和重用,降低耦合度。 |
| 減少重複代碼 | 封裝屬性和行為可以減少重複的業務邏輯處理,提高程式碼可維護性。例如:產品折扣和庫存更新等功能可通過類別方法多次使用。 |
| 對象與實體關聯處理 | 例如商品、用戶、訂單等都可以看作實體(Entity),通過類別來處理實體間的關係和互動,類別封裝能讓這些處理更直觀。 |
| 減少錯誤與邏輯清晰 | 將邏輯封裝進類別後,其他開發者可以通過呼叫類別方法來操作數據,減少直接修改數據庫的錯誤機會,也讓邏輯更集中在一個地方。 |
| 測試與持續集成方便 | 類別化的設計更易於編寫單元測試,確保每個方法運行正常,對於需要自動化測試和持續集成的專案來說,是個優勢。 |
| 何時可以不使用 Class? | 解釋 |
|---|---|
| 操作單一且簡單 | 如果只是從前端接收數據並插入資料庫,且沒有複雜邏輯,直接使用 SQL 更為直接和高效。 |
| 小型專案或輕量級應用 | 對於小型或簡單的應用,類別和 ORM 會增加額外的複雜性,直接使用 SQL 反而更簡單合適。 |
| 臨時性資料處理 | 如果某些資料處理邏輯只會執行一次或很少的次數,使用函數式編程可能會比封裝成類別更簡潔,避免過度設計。 |
| 無複雜邏輯或重複操作 | 當業務邏輯非常簡單,不需要封裝邏輯,也不會經常操作,直接使用 SQL 或函數可以快速完成需求,無需引入類別。 |
| 快速開發的原型 | 當在進行快速開發原型或小型專案時,類別的設計與結構可能會延緩開發進度,直接操作資料庫與函數處理會更快。 |
| 結論 | 解釋 |
|---|---|
| 不使用 class | 適用於簡單的網頁應用,直接接收數據並插入資料庫,不需要複雜邏輯操作時,直接使用 SQL。 |
| 使用 class 和 ORM | 適用於逐漸變複雜的系統,使用類別來定義數據結構,配合 ORM 操作資料庫,讓程式更具可維護性與擴展性。 |
| 使用 class 和模組化設計 | 當系統逐漸擴展,需求越來越多時,模組化的類別設計可更好地組織和封裝邏輯,為未來維護與擴展提供更好的基礎。 |
大家可以思考來設計屬於自己的最佳程式喔!!
雖然平常都提倡化繁為簡
但有時候開發團隊或是專案越來越大時
還是會以許多封裝或是拆分功能細節控制這樣的觀念去思考~
是不是覺得工程師很搞剛呢XDD

