
人工智能的威力
相信大家在近期都看到它們在各大領域(藝術、醫學、理工、法律、文學)大殺四方
今天要探討的主題主要是
為什麼人工智能跟學習Python息息相關?
別的語言就不行嗎?
人工智能到底是什麼?機器學習?神經網路?
這麼多新名詞哪記得了
今日目標:
看到這個標題一定有人想
這個不是廢話嗎?
大家都叫我們學習AI要先學Python
不過大家有沒有想過為什麼要先學習Python?
這個時代很多厲害高效能的語言 (C++/Go/Rust)
一定要非選擇Python不可
其實這些事情沒有絕對
也有其他語言的,如下圖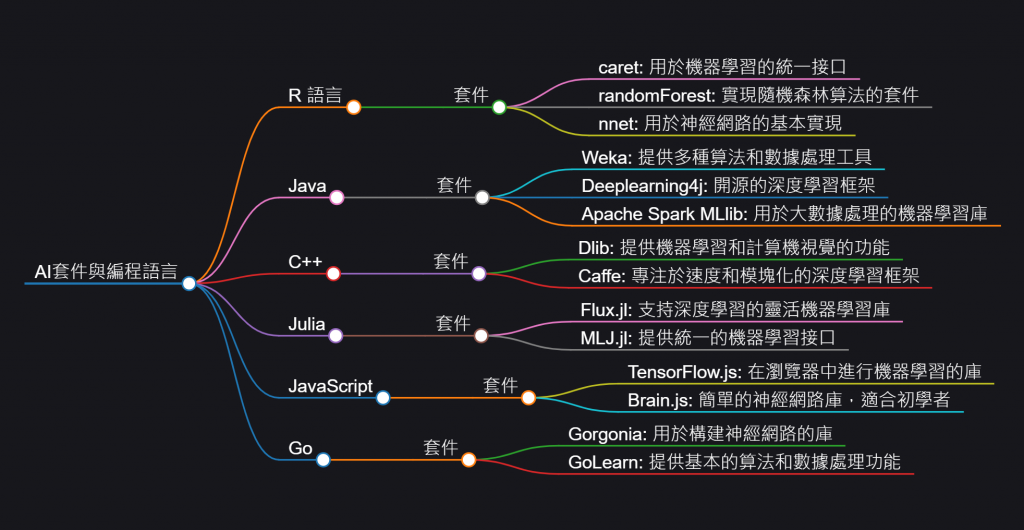
其實開發者也沒有限制要使用哪個語言
也可以選擇資料科學很熱門的R或是網頁開發者也可以選擇Tensorflow.js(實際上是去call底層API)
所以並不是學習AI就一定要學Python,而是因為Python瑞士刀剛好受到各方大老的喜愛
也就造就了許多的科學函式庫還有機器學習套件
至於它的優勢是什麼往們繼續往下探討~
透過表格我們可以精簡以下的優勢
python語言優勢表
| 優勢 | 說明 |
|---|---|
| 簡單易學、可讀性高 | Python 語法簡潔,讓開發者專注於解決問題而非語言細節。 |
| 豐富的庫與工具 | 擁有強大的 AI 和機器學習庫,如 TensorFlow、PyTorch、Scikit-learn 等。 |
| 跨平台支持與靈活性 | 支持多操作系統,並且易於與其他語言和技術整合。 |
| 龐大的社群與資源 | 有活躍的開發者社群,提供大量教程、範例與技術支持。 |
| 與數據科學的高度契合 | 強大的數據處理工具如 Pandas 和 NumPy 使數據科學與機器學習相輔相成。 |
| 豐富的可視化工具 | Matplotlib、Seaborn 等庫幫助展示數據和模型結果,讓 AI 項目更具直觀性。 |
| 開源文化與社群支持 | 許多流行的 AI 框架是開源的,促進創新和知識共享。 |
| 快速原型設計與實驗性質 | 適合進行快速原型設計,能迅速測試算法並迭代模型。 |
大公司的選擇˙
其中也有不少大公司使用Python的機器學習來應用在公司的企業邏輯
| 應用場景 | 說明 |
|---|---|
| 推薦系統 | 用於電商和流媒體平台,根據用戶行為進行個性化推薦。 |
| 自然語言處理(NLP) | 用於語音助手、語音識別、文本分析和語言翻譯。 |
| 計算機視覺 | 用於自動駕駛、醫療影像分析、安防監控等圖像處理任務。 |
| 金融風險管理 | 用於金融市場的風險預測、自動交易系統等。 |
| 醫療健康 | 應用於疾病診斷、基因分析等,幫助精確醫療診斷。 |
其實小弟認為~Python這麼火紅也許跟Google也有占很大的因素
當代紅片全球的幾個熱門框架都可以透過Python來操作呼叫背後的API進行邏輯運算
總結來說,Python 的優勢在於其語法簡潔、庫豐富、應用靈活,並且擁有龐大的開源社群支持。這些特點讓它成為 AI 和機器學習領域中的領導語言,無論是快速原型開發還是生產級別的部署,Python 都能勝任。
這也是為什麼前面我會推薦使用Fast API?
因為我希望Python處理資料或是人工智能運算的這項microservice
可以專注處理邏輯而非學習一堆框架語法
也就是我在FastAPI章節說的兼具性能、RESTful API、非同步運行、社群支持 CP值高高XDD
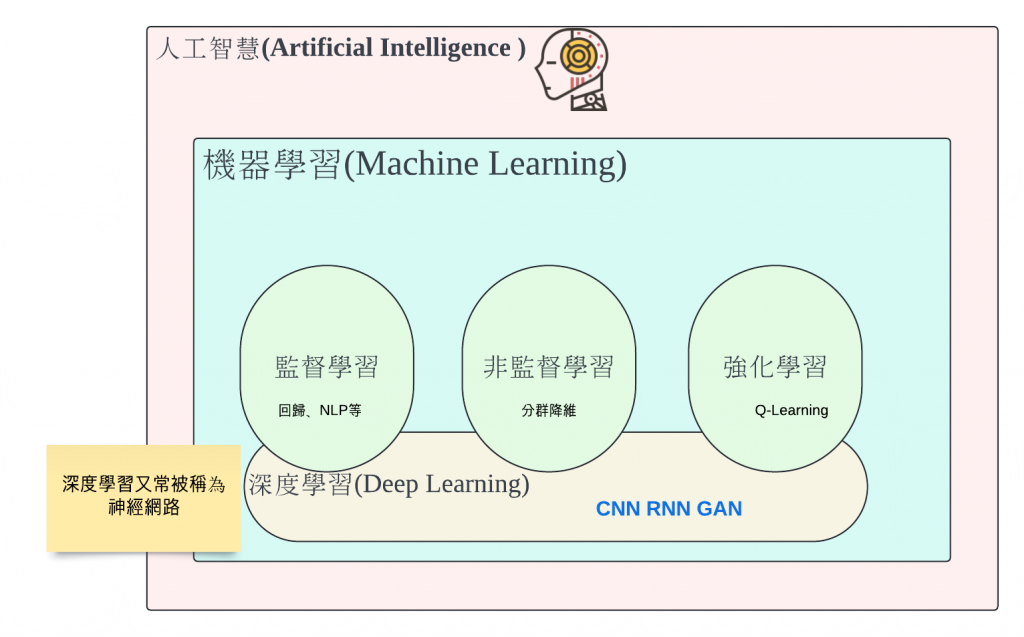
人工智能(Artificial Intelligence,簡稱 AI)是指由人類創造的系統或機器,能夠模擬和執行通常需要人類智慧的任務。這些任務包括學習、推理、問題解決、理解自然語言、識別圖像和聲音等。人工智能的目標是使機器能夠像人類一樣思考和行動,並在某些情況下超越人類的能力
從這張圖我們可以看到這些專有名詞的集合
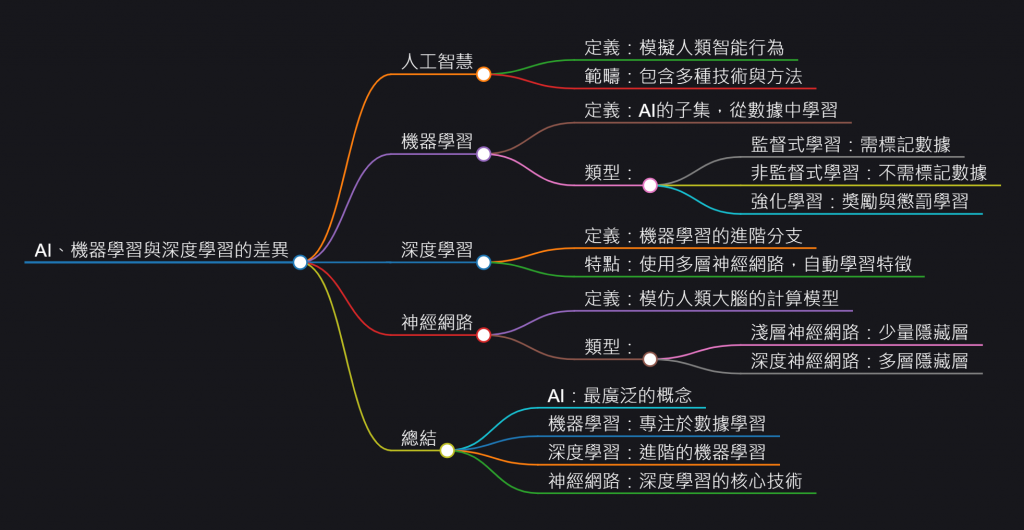
既然我們是電腦工程師
我們的目標當然就是直接探討機器學習跟深度學習
理論會在這個篇章說明
實作會以機器學習為主,至於深度學習會在明天壓軸登場~!!
監督學習、非監督學習與強化學習的差別與應用場景
定義
監督學習是基於已標記數據來進行模型訓練的學習方法。在這種方法中,模型學習到輸入數據和目標標籤之間的對應關係,並嘗試對未來的輸入數據做出預測。
特點
應用場景
常用算法
定義
非監督學習是使用無標籤數據進行訓練的學習方法。目的是從數據中發現隱含的結構或模式,並對數據進行聚類或降維處理。
特點
應用場景
常用算法
定義
強化學習是基於智能體在環境中的行為學習。智能體通過與環境互動,接收到來自環境的反饋(獎勵或懲罰),從而學習最佳策略以最大化長期回報。
特點
應用場景
常用算法
| 學習方法 | 定義 | 應用場景 |
|---|---|---|
| 監督學習 | 基於已標記數據進行模型訓練,以學習輸入和標籤之間的映射關係。 | 圖像分類、垃圾郵件檢測、價格預測等。 |
| 非監督學習 | 使用無標籤數據,目的是從數據中發現結構或模式。 | 聚類分析、異常檢測、數據降維等。 |
| 強化學習 | 基於智能體與環境的互動學習,通過獎勵和懲罰來學習最佳策略。 | 遊戲 AI、自動駕駛、機器人控制等。 |
其實深度學習就是透過機器學習的方法做整合應用,並且透過模擬人類神經把各種方法混和應用。
深度學習(Deep Learning)可以看作是機器學習的子集,並且它可以應用於監督學習、非監督學習和強化學習這三種方法中。深度學習的核心是使用多層神經網絡來自動學習特徵,並在各種學習任務中獲得卓越的表現。
以下是深度學習與這三種學習方法的關係及其應用:
如何結合:
輸入數據和標籤之間的複雜關係。這是最常見的應用場景之一,因為標記數據的存在使得神經網絡可以進行精確的預測。常見應用:
如何結合:
常見應用:
如何結合:
常見應用:
| 方法 | 深度學習的應用 | 傳統方法的應用 |
|---|---|---|
| 監督學習 | 使用深度神經網絡來自動學習多層特徵,尤其在高維數據如圖像、語音中效果優異。 | 傳統方法如線性回歸、支持向量機,依賴於手動特徵提取。 |
| 非監督學習 | 深度學習可以通過自編碼器、GAN 等從數據中學習潛在特徵或生成新數據。 | 傳統方法如 K-means 聚類、主成分分析。 |
| 強化學習 | 深度強化學習使用神經網絡處理高維感知數據,幫助智能體在複雜環境中學習決策。 | 傳統強化學習方法如 Q-learning,無法有效處理高維數據。 |
深度學習在這三種機器學習方法中都扮演了重要角色,幫助解決了傳統方法無法輕易處理的問題,特別是在處理高維數據(如圖像、視頻、語音)方面。
深度學習與監督學習結合使得模型在分類和預測任務上表現卓越
與非監督學習結合能從數據中自動提取特徵和生成新數據
與強化學習結合則使得智能體能夠在複雜的動態環境中做出更智能的決策。
本實作會以機器學習的監督跟非監督學習個挑一種情境來帶大家實作
之所以選擇線性回歸這個方式
是最貼近我們生活跟數學最好理解的方式
今天的需求很簡單
我們可以透過前面學到的爬蟲抓取股票把TSM美股近33天的股價列出來(最近有爬一些美股)
然後預測第34天或自定義天數來看股價式多少
(這邊是學習,不構成投資建議喔~!!)
如果忘記爬蟲可以複習一下
Day21爬蟲章節
所以我們的時序圖大概是長這樣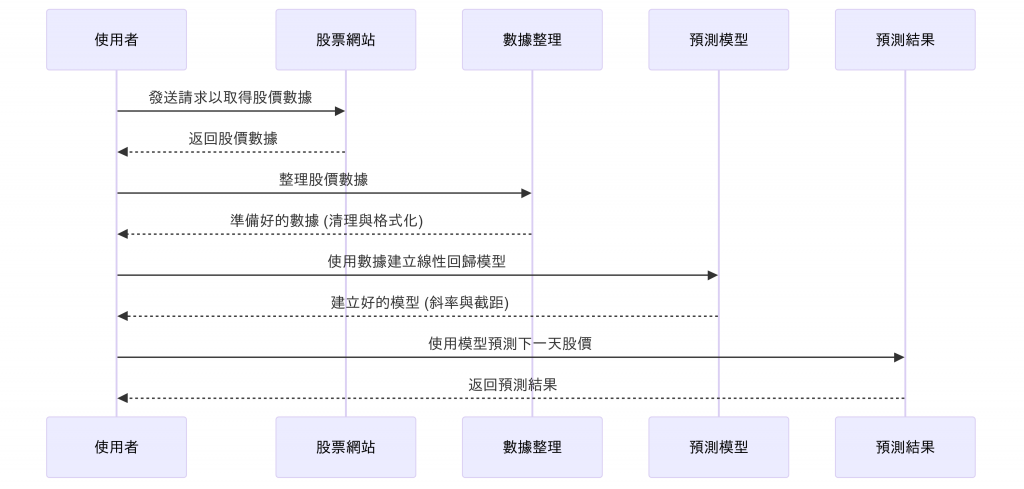
因為今天會把圖畫出來以及使用到numpy功能所以請大家先安裝
pip install numpy matplotlib
TSM stock資料
我已經整理成陣列格式了
大家可以複製過去用
closing_prices = [
190.81, 185.78, 187.14, 186.05, 188.17, 185.86, 184.50, 182.00, 180.50, 179.00,
178.00, 177.50, 176.00, 175.00, 174.50, 173.00, 172.00, 171.50, 170.00, 169.00,
168.00, 167.50, 166.00, 165.00, 164.00, 163.50, 162.00, 161.00, 160.00, 159.00,
158.00, 157.00, 156.00
]
import numpy as np
import matplotlib.pyplot as plt
# 股價資料(最新日期在最前的順序)
closing_prices = [
190.81, 185.78, 187.14, 186.05, 188.17, 185.86, 184.50, 182.00, 180.50, 179.00,
178.00, 177.50, 176.00, 175.00, 174.50, 173.00, 172.00, 171.50, 170.00, 169.00,
168.00, 167.50, 166.00, 165.00, 164.00, 163.50, 162.00, 161.00, 160.00, 159.00,
158.00, 157.00, 156.00
]
# 反轉數據,讓最早日期在前
closing_prices.reverse()
# 設置 X 軸的日期索引 (1 到 33)
days = np.arange(1, len(closing_prices) + 1)
# 畫股價點
plt.scatter(days, closing_prices, label='Stock Prices', color='blue')
plt.xlabel('Days')
plt.ylabel('Closing Prices')
plt.title('Stock Prices Over the Last 33 Days')
# 將股價標示在圖上
for i, price in enumerate(closing_prices):
plt.text(days[i], closing_prices[i], f'{price:.2f}', fontsize=8)
plt.show()
如果執行沒意外應該可以看到這張圖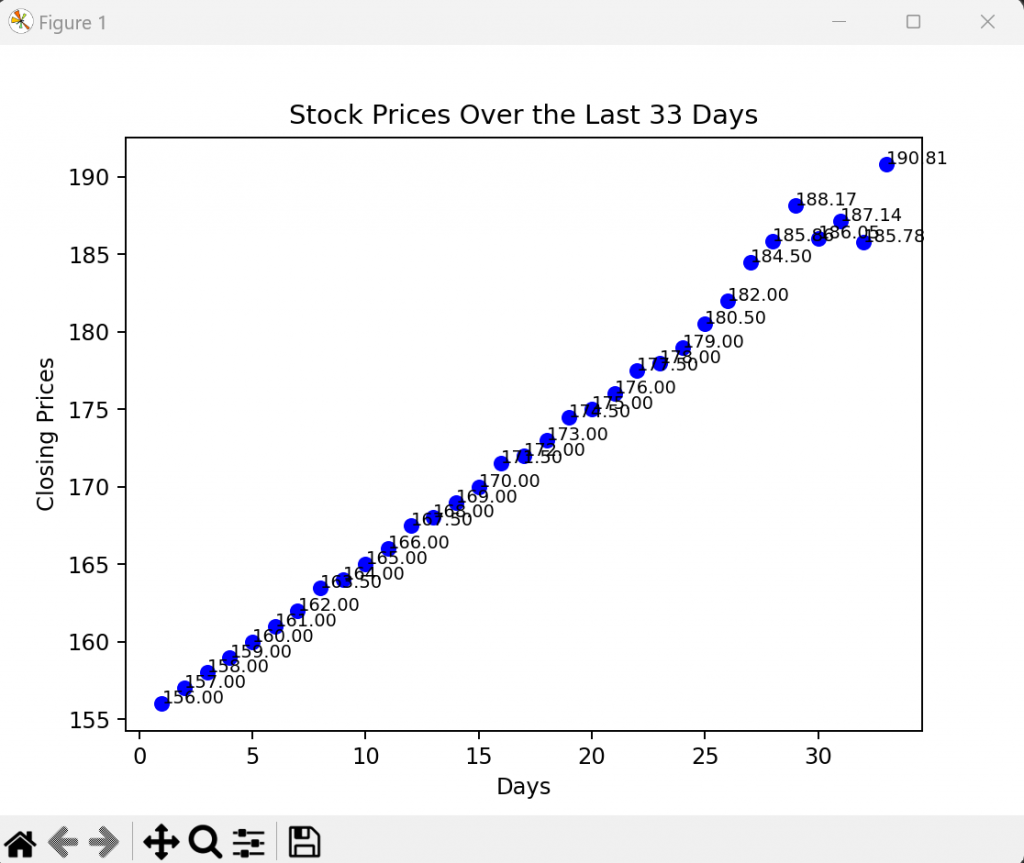
tips 程式說明
.reverse()
再給程式碼前
相信各位小夥伴已經大概知道怎麼做了
沒錯! 其實這就很像是國中學到的數學公式Y = ax + b
y= 股價
a = 斜率
x = 天數
b = 截距
那我們線性回歸的方法是這樣算的
線性回歸的方程式是通過統計學中的**最小二乘法(Least Squares Method)**來計算的,目的是找到一條最佳的直線,使得所有點到這條線的垂直距離之和最小。這個最佳直線的方程式通常表示為:
y = mx + b
最小二乘法的運算方法有興趣可以去參考相關數學書籍
這邊不做推導XDD
我們可以透過好用的python library來做運算
Python 中的實現方式
在 Python 中,我們可以使用 NumPy 的 polyfit() 函數來自動執行這些計算。polyfit(x, y, 1) 使用了上述的最小二乘法來擬合一條一階(即線性)的方程式,並返回斜率 𝑚 和截距 𝑏。
m, b = np.polyfit(days, closing_prices, 1)
numpy.polyfit() 函數中,第三個參數是指定要擬合的多項式的階數(degree)。這個參數決定了擬合曲線的複雜度和形狀:
當設置為 1 時,表示進行 一階線性回歸,即擬合一條直線y = mx + b
設置為 2 時,表示進行 二階多項式回歸,即擬拋物線y = ax^2+ bx + c
計算我們的預測函數
import numpy as np
import matplotlib.pyplot as plt
# 股價資料(最新日期在最前的順序)
closing_prices = [
190.81, 185.78, 187.14, 186.05, 188.17, 185.86, 184.50, 182.00, 180.50, 179.00,
178.00, 177.50, 176.00, 175.00, 174.50, 173.00, 172.00, 171.50, 170.00, 169.00,
168.00, 167.50, 166.00, 165.00, 164.00, 163.50, 162.00, 161.00, 160.00, 159.00,
158.00, 157.00, 156.00
]
# 反轉數據,讓最早日期在前
closing_prices.reverse()
# 設置 X 軸的日期索引 (1 到 33)
days = np.arange(1, len(closing_prices) + 1)
# 使用線性回歸計算 y = mx + b 的係數
m, b = np.polyfit(days, closing_prices, 1)
# 畫股價點和趨勢線
plt.scatter(days, closing_prices, label='Stock Prices', color='blue')
plt.plot(days, m * days + b, label='Linear Regression', color='orange') # 畫出線性回歸線
plt.xlabel('Days')
plt.ylabel('Closing Prices')
plt.title('Stock Prices with Linear Regression')
# 顯示線性方程式
plt.text(5, max(closing_prices), f'y = {m:.2f}x + {b:.2f}', fontsize=12, color='red')
plt.legend()
plt.show()
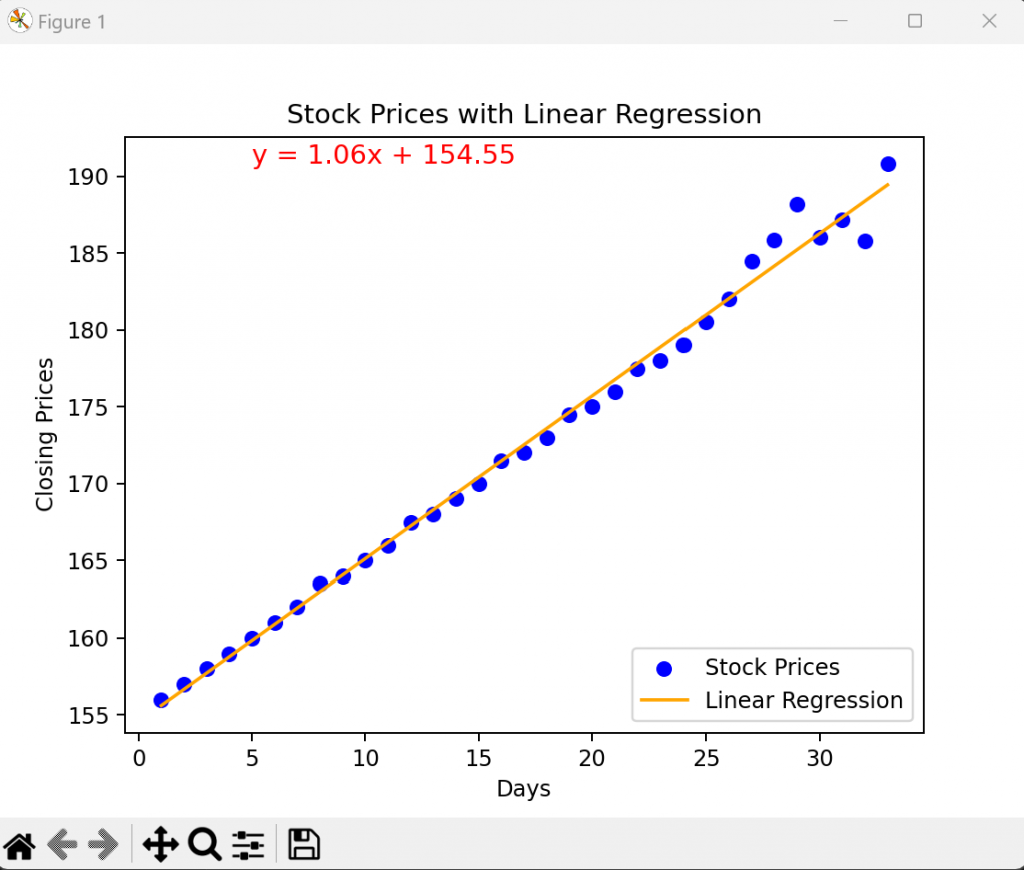
我們可以得到這是我們的回歸方程式y = 1.06x +154.55
import numpy as np
# 股價資料(最新日期在最前的順序)
closing_prices = [
190.81, 185.78, 187.14, 186.05, 188.17, 185.86, 184.50, 182.00, 180.50, 179.00,
178.00, 177.50, 176.00, 175.00, 174.50, 173.00, 172.00, 171.50, 170.00, 169.00,
168.00, 167.50, 166.00, 165.00, 164.00, 163.50, 162.00, 161.00, 160.00, 159.00,
158.00, 157.00, 156.00
]
# 反轉數據,讓最早日期在前
closing_prices.reverse()
# 設置 X 軸的日期索引 (1 到 33)
days = np.arange(1, len(closing_prices) + 1)
# 使用線性回歸計算 y = mx + b 的係數
m, b = np.polyfit(days, closing_prices, 1)
# 預測下一天的股價
next_day = len(closing_prices) + 1
predicted_price = m * next_day + b
print(f"預測第 {next_day} 天的股價: {predicted_price:.2f}")
大家可以自行操作
next_day = len(closing_prices) + 1
修改後面的+1即可,
+1就是第34天
預測第 34 天的股價: 190.50
+0就是第34天
預測第 43 天的股價: 200.02
這樣我們就學會最簡單的預測模型了
但是大家也知道股票不是這麼簡單的
有可能會因為外資、國家政策、貸款、通膨、公司策略等因素影響
這種就可以透過深度學習調整權重去配合自己的股票預測模型喔!!
非監督學習的數據處理:
不需要標籤:非監督學習的主要特點是使用未標記的數據進行訓練。這意味著數據集中的樣本不需要事先進行標記(例如,沒有性別、類別等標籤)。
數據分割:儘管非監督學習不需要標籤,但在實踐中,通常仍會將數據集分成訓練集和驗證集(或測試集),以評估模型的性能。這樣的分割可以幫助確保模型的泛化能力,並防止過擬合。具體分割比例可根據需要而定,常見的比例是70%訓練集和30%測試集。
聚類和降維:非監督學習算法,如 K-means 聚類、層次聚類、主成分分析(PCA)等,通常用來發現數據中的結構、模式或群組。這些算法可以幫助識別相似性,並將數據分組,而不需要事先的標籤。
需要使用所需安裝的套件
pip install scikit-learn
我們的目標是透過KNN方式分類男生還是女生
所以要先安裝scikit來使用這種算法使用
KNN(K-Nearest Neighbors)是一種簡單且有效的機器學習算法,常用於分類和回歸任務。以下是 KNN 的基本概念和作法:
選擇 K 值:選擇一個整數 K,這是用來決定考慮多少個最近鄰樣本。K 的選擇會影響模型的性能。
計算距離:對於要進行分類或預測的樣本,計算它與訓練集中的每個樣本之間的距離。
找出 K 個最近鄰:根據計算的距離,找出 K 個最近的樣本。
進行分類或預測:
評估模型:使用交叉驗證或其他技術來評估模型的準確性,並根據需要調整 K 值或其他參數。
優點:
缺點:
KNN 是一種基於實例的學習方法,適用於很多實際應用場景,如手寫數字識別、推薦系統和醫療診斷等。
簡單說就是坐標系中最接近距離的做法
非監督學習確實可以將數據分為訓練集和測試集,但這樣的分割不涉及標籤。其主要目的是評估模型的性能或發現數據中的潛在模式。
資料集
| 編號 | 性別 | 身高 (cm) | 體重 (kg) |
|---|---|---|---|
| 1 | 男生 | 180 | 75 |
| 2 | 男生 | 175 | 78 |
| 3 | 男生 | 190 | 85 |
| 4 | 男生 | 178 | 80 |
| 5 | 男生 | 185 | 90 |
| 6 | 女生 | 160 | 55 |
| 7 | 女生 | 158 | 52 |
| 8 | 女生 | 165 | 60 |
| 9 | 女生 | 170 | 65 |
| 10 | 女生 | 162 | 58 |
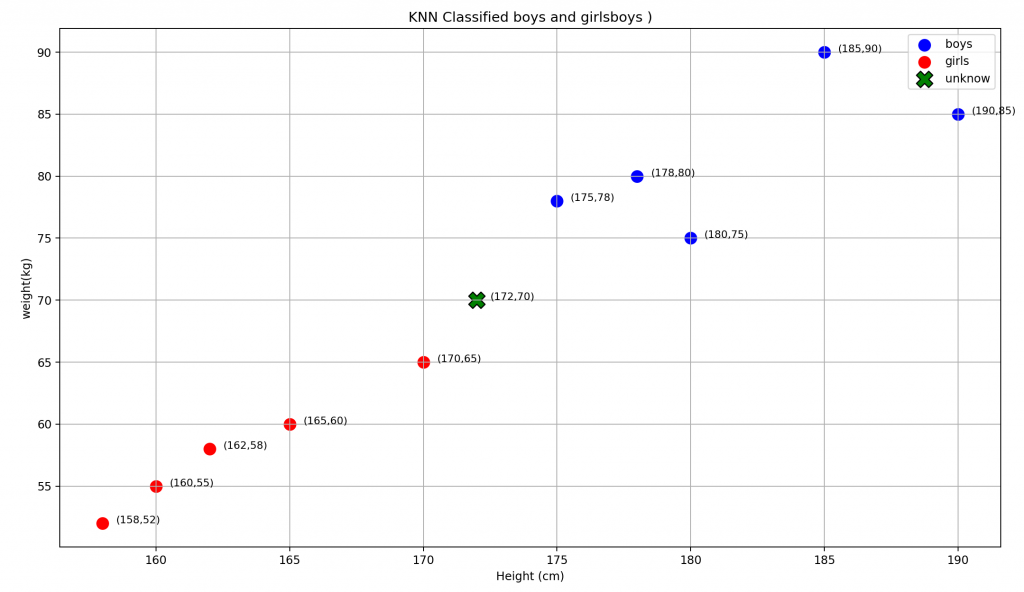
預測這位是男生還是女生[172, 70]
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 男生與女生的數據(身高, 體重)
X = np.array([
[180, 75], # 男生
[175, 78], # 男生
[190, 85], # 男生
[178, 80], # 男生
[185, 90], # 男生
[160, 55], # 女生
[158, 52], # 女生
[165, 60], # 女生
[170, 65], # 女生
[162, 58], # 女生
])
# 對應的標籤(1 = 男生, 0 = 女生)
y = np.array([1, 1, 1, 1, 1, 0, 0, 0, 0, 0])
# 要分類的第六筆資料(未知身高, 體重)
new_data = np.array([[172, 70]])
# 建立 KNN 模型,K=3
knn = KNeighborsClassifier(n_neighbors=3)
# 訓練模型
knn.fit(X, y)
# 預測新數據的性別
prediction = knn.predict(new_data)
# 輸出預測結果
if prediction == 1:
print("預測結果: 男生")
else:
print("預測結果: 女生")
我們得到的結果應該是
預測結果: 男生
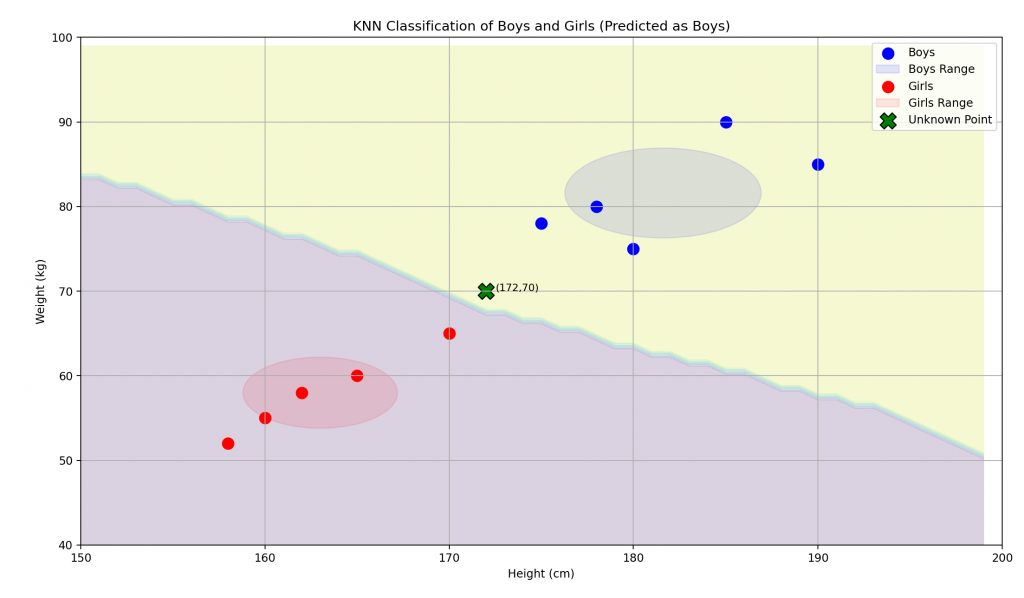
如果我們把範圍長出來
可以呈現成這樣的圖
今天踏入了機器學習的大門
這個路途非常由遠而且沒有盡頭
只能依照個人的需求來選擇適合的模型方式
找出最想要的資料結果
另外有幾點可以給大家參考
注意事項
| 注意事項 | 說明 |
|---|---|
| 數據質量 | 確保數據準確、完整且無缺失值,因為數據質量影響模型表現。 |
| 數據量 | 大量的數據可以幫助模型更好地學習,但數據過少可能導致過擬合。 |
| 特徵選擇 | 選擇合適的特徵以提升模型的預測能力,去除不相關或冗餘的特徵。 |
| 超參數調整 | 使用交叉驗證和網格搜索等技術來優化模型的超參數。 |
| 過擬合與欠擬合 | 監控模型表現,避免過擬合(模型在訓練集上表現良好但在測試集上表現差)或欠擬合(模型無法捕捉數據中的趨勢)。 |
| 模型評估 | 使用多種評估指標(如準確率、精確度、召回率等)來全面評估模型性能。 |
| 持續學習 | 機器學習是個持續進步的領域,要保持對新技術和最佳實踐的學習。 |
學習網站參考
| 網站 | 說明 |
|---|---|
| Coursera | 提供大量的機器學習和數據科學課程,包括知名大學的專業證書。 |
| edX | 免費和付費的高等教育課程,涵蓋機器學習、深度學習等主題。 |
| Kaggle | 提供機器學習競賽、數據集和學習資源,是一個活躍的數據科學社區。 |
| Fast.ai | 提供免費的深度學習課程,注重實踐與應用。 |
| Towards Data Science | 包含大量機器學習和數據科學的文章和教程,適合各種水平的學習者。 |
| Machine Learning Mastery | 提供詳細的機器學習指南、教程和實用範例,幫助學習者理解基本概念。 |
| deeplearning | AI大師吳恩達教授提供的網站,新手特別推薦可以從這邊開始學習 |
另外在台灣也有幾名知名教授的youtube課程可以學習: 李宏毅教授、陳縕儂教授
都是非常厲害的老師喔!!

