
重新分析一下昨天牛刀小試的例子, 我們在 addToCart() 的函式中用了 includes() 和 unshift() 兩個時間複雜度皆為 O(n) 的函式,先是走訪一次 n 個購物車的 Items 來查詢是否有重複,再做插入購物車的動作,疊加起來便是 O(n) * O(n) = O(n^2)。
const cart = ['Apple', 'Banana'];
function addToCart(newItem) {
if (!cart.includes(newItem)) {
cart.unshift(newItem);
}
}
如果每次都要 O(n) 的效率來檢查重複,就會造成總體演算法的複雜度為指數的,那麼有沒有一種方法能降低檢查重複的複雜度呢?這便是我們接下來要講的 Hash Table 了。
在討論原理之前,我們先看結論:將 Cart 的資料放到 Hash Table 中的時間複雜度為 O(1),所以整體演算法的複雜度將被降為 O(1) * O(n),也就是 O(n) 這個線性成長的複雜度。
相對於 Array 需要從頭讀一遍 Cart 的資料,Hash Table 居然看一眼就能知道有沒有重複?
沒錯,這便是 Hash Table 這個資料結構神奇的地方!人類本能的排查重複的方式本質上是 Array 的搜尋,要一個一個看過才能確定有沒有一樣的內容。
但對於 Hash Table 這種資料結構來講,卻有著獨特的搜尋優勢,那便是利用 Hash(雜湊)的特性。
那麼究竟 Hash Table 的原理為何?我們前面在聊使用者密碼的傳遞及儲存,加密及雜湊的時候便曾經提過雜湊(Hash),所謂的 Hash 是一種單向的函數,給定一組 Input,就能得到固定 Output。
在資訊安全方面,我們利用了 Input 到 Output 的隨機性,讓使用者 Hash 過後的密碼難以預測及破解,但同時還能在登入時驗證密碼是否正確;而 Hash Table 的的儲存,則用到了 Hash 產生結果的固定性。
我們可以設計一種 Hash Function,讓相同的 Input String 產生出來的 Output 是相同的 Integer,例如最簡單的做法就是取 String 的首字母順序,如果是 A 的話就對應到數字 0、B 的話就對應到 1,以此類推,所以 G 的話就會對應到 6。

*簡易的 Hash Function
由於英文字母只有 26 個,我們可以依此來建立一個長度為 26 的 Array,當有新的 String 要儲存進來的時候,我們就透過剛剛的 Hash Function 轉換出來的數字,存入 Array Index 相對應的位置。

*透過 Hash Function 將 String 存在 Array 的相應位置
因此 Apple 就存在第 0 個位置,Banana 存在第 1 個位置,Grape 存在第 6 個位置。
由於要儲存的資料,其位置是透過一個 Hash Function 所產生的,這樣的資料結構就稱作是一個 Hash Table。
這樣做的好處是什麼呢?當然是在搜尋時找到儲存位置的速度變得奇快無比。
例如我們想搜尋 Carrot 這個元素是否在此 Hash Table 內,我們就可以將 Carrot 丟入 Hash Function,找出其儲存位置為 2,便能發現裡面確實存了一個 Carrot。

*透過 Hash Function 快速找到儲存位置
從原本要走訪整個 Array 一個一個元素來做比對,到透過 Input 丟入一個 Hash Function 直接找到位置,讓搜尋效率從線性 O(n) 到了常數 O(1),有了數量級上的提升。
但這樣的做法是否還有些缺陷?我們單從英文首字母來判斷位置,那如果遇到相同首字母的單字,例如 Carrot 和 Cherry 都是 C 開頭的怎麼辦?
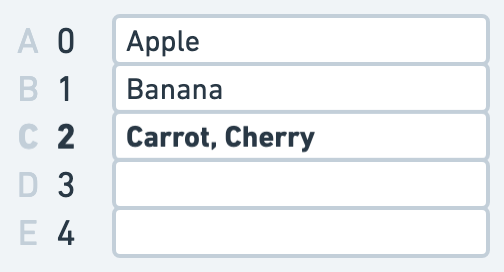
*Hash Table 中的碰撞
解決的方法可以是把相同首字母放在一起,例如 Carrot 和 Cherry 都指向 2 這個位置,那麼 2 這個位置就會存放兩個單字。實作上可以在 2 用叫做 Chaining 的方式用 Linked List 連起來,看到 C 開頭的單字就先到位置 2 看一看,把這個位置裡面的所有單字再掃過一遍。
然而,這樣的方法有個致命的缺陷,畢竟我們衡量時間複雜度是看「最壞的情況」,因此當所有單字都是相同首字母的話就不妙了。
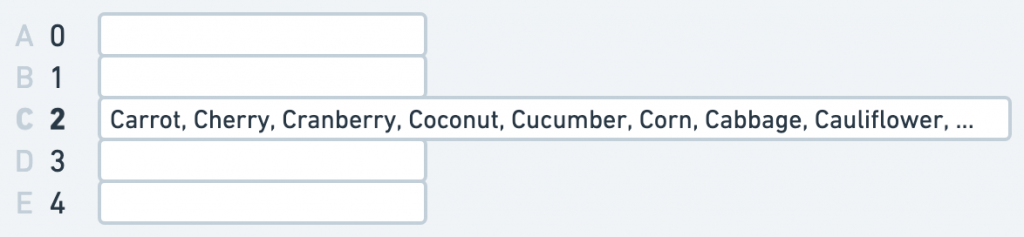
*所有首字母都是 C,在 Hash Table 內的情形
例如所有的單字都是 C 開頭,全部儲存在位置 2 當中,這樣的情況就相當於退化成了正常的 Array,搜尋時間複雜度依舊是 O(n),因為我們就算透過 Hash Function 找到了位置 2,依舊得在這個位置上走訪所有的單字,才能確保某個 C 開頭的單字是否已經在這張 Table 裡面。
為了解決這樣的致命缺陷,我們應該改進我們的 Hash Function,現在的做法有可能會讓單字儲存在某幾格位置當中,因為英文字首字母出現的頻率並不「均勻」。
例如 Q, X, Z 在所有英文單字的首字母中,出現的頻率敬陪末座,加起來大約只有 0.3% 而已,顯然 Q(16), X(23), Z(25) 這三格在我們的 Hash Table 內會用的比較少,而 A, E, H 這些常見的首字母會用的比較多。
因此,怎麼設計出一個 Hash Function 能讓所有 Input 分佈在 Table 內更加「均勻」就是相當重要的事情!
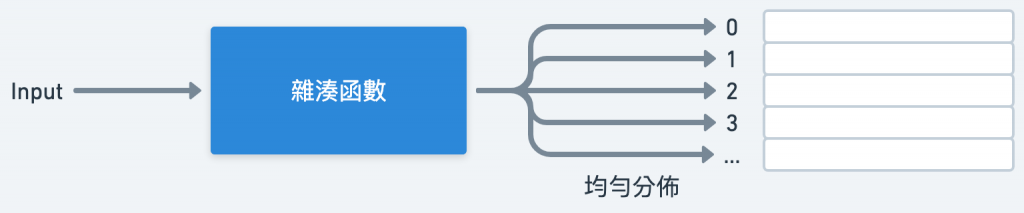
*理想的 Hash Function
例如我們不單單取首字母了,而是取前兩個字母;或是整個單字的 ASCII 加總或求乘積再取餘數;又或者再多做幾輪類似的運算等等。
總而言之,讓其分佈均勻是 Hash Table 上的 Hash Function 的重要設計目的,除此之外也要兼顧效率,不能為了讓其均勻分佈就做了極大量的運算。
理解了 Hash Table 的基本原理後,回到我們實務面上會用到的情況:搜尋、去重。
我們開頭提的範例,購物車新增不重複的元素,便是一個常見例子。我們如果要在一個 Array 中搜尋某元素是否存在的話,最簡單的方法便是一個 for 迴圈走訪一次。
許多內建的 function 尤其方便,例如 JavaScript 的 includes()、Python 的 item in list、Java 的 contains() 等等。
但是當我們很常呼叫這個 Array 的搜尋 Function,特別是在另外一個迴圈中使用時,就很容易忽略這邊時間複雜度的疊加。
在開發上有非常非常多的資料處理都會需要做搜尋、做去重的事情,此時就是 Hash Table 登場的好時機了,在 JavaScript 中可以用 {} 這樣的 Object 或 Set;Python 中有 Dictionary;Java 有 HashMap 等等,都是 Hash Table 在這些程式語言中的實作。
善用 Hash Table、理解哪些 Build-in functions 會造成不必要的效率降低,必定能讓開發出來的產品品質更好。

 iThome鐵人賽
iThome鐵人賽