Kafka Connect是官方提供的資料搬運工具,本文以一個類似本專案的場景,說明將Kafka Topic的資料匯入MongoDB的設定及執行流程。
本篇文章補充介紹Kafka提供的實用工具: Kafka Connect。
當初在調整架構時,本來有想過使用Kafka Connect,先將AWS Lambda帶來的使用者訊息無腦倒進 MongoDB,再由BotServer取出後做其他處理。但這樣的架構會導致未經處理的資料,和經過語意判斷後處理過的資料都擺在資料庫內。既然資料庫是永久保存的,我們就希望他維持單純,只儲存處理過且需要保存的資料就好。
因為上述原因,最後沒有使用Kafka Connect。但因為已經Survey一陣子,過程中也發現,它確實在某些場景中是一個好用的工具,所以在Kafka系列文的最後介紹一下這個官方提供的資料整合工具。
Kafka Connect是一套官方提供的工具程式,用於整合Kafka與其他外部系統的資料。簡單來說,它可以將 Kafka Topic的資料匯出到外部系統(例如:Postgres、MongoDB 等),或將外部系統的資料匯入Kafka Topic。而且根據官方說明,它適合用於大規模資料的傳輸,所以在一些不適合用 API 傳輸資料的場景下,Kafka Connect 是很好的替代方案。
實作上的好處如下:
這可能是最大的好處,因為Kafka Connect可以幫忙把資料用指定的格式,寫入或從外部系統讀出,而這些常見的外部系統,例如Postgres,MongoDB的Connector都有官方開發好的套件,以外掛的形式提供開發者使用。
例如: 當我們要把寫到某個Topic的資料傳輸到MongoDB時,只要設定正確,我們不用寫任何一行程式開發Consumer,直接使用Mongodb Connector,就可以達到目的。
Kafka Connect的主程式(worker)是和Kafka Server不同的程式。你可以在docker container的/bin目錄中找到connect-distributed.sh,這就是Kafka Connect的主程式。
跟其他在該目錄下的.sh檔案一樣,是官方提供的獨立程式,不會影響Kafka Server本身的運作,適合要把外部系統快速的跟已經運作中的Kafka介接的場景。
除了本專案的場景需要寫入MongoDB,官方也提供Postgres, MySQL等各家廠牌已經寫好的輸入/匯出工具。這些工具會以外掛的形式被Kafka Connect使用。
文件說明豐富,從觀念講解到設定方式,官方都有很詳盡的文件可以看。
Kafka Connect支援Distributed mode模式,可以用更好的效率寫入 / 匯出資料
宏觀來說是這樣運作的: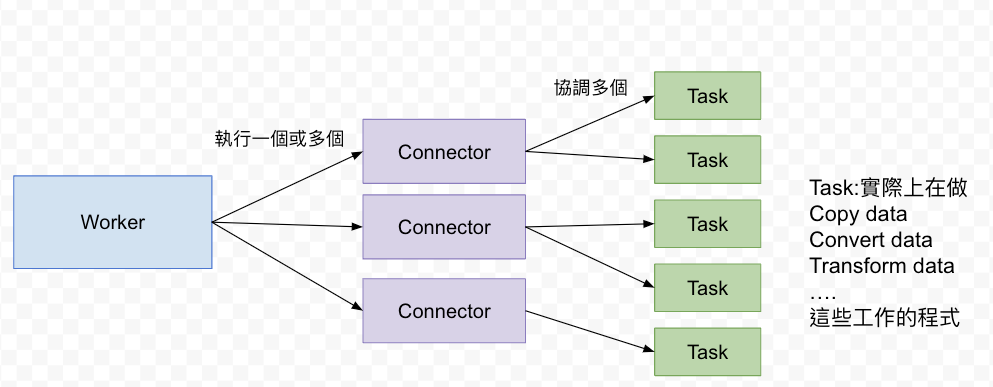
即Kafka Connect的主程式,在Kafka Server路徑的/bin裡面,啟動時需要設定正確的config (.properties)。
正確啟動後,除了程式本身外,還會準備一個Kafka Connect自己的Rest API Server。透過呼叫這些API,可以達到新增Connector,刪除Connector,以及檢視目前已存在的Connector等操作。
Kafka connect支援Distributed / Standalone兩種執行模式,差別在於Distributed mode會把Kafka connect的程式分散在Kafka集群的多個node上(如果有的話),而Standalone mode就是運行一個單一的connect程式。
由於Distributed mode支援較好的容錯(一個node的worker死了還有別的能用)和擴展性,官方建議在Production環境以Distributed mode執行。
Connector由Connector instance,Converter,和Transfomer(optional)組成,由Kafka connect work協調使用
Kafka Connect使用兩種類型的connectors來與外部db做資料寫入 / 匯出:
一旦指定的Topic有資料進來就會寫入外部系統一旦外部系統有資料變動就會寫入指定的Topic幾乎每種DB kafka都有提供connector實作, 只要用安裝plugin的方式即可。
Byte Array。Source Connector的Converter將外部系統的資料序列化成Byte Array後,寫入Kafka。
Sink Connector的Converter會將Kafka的Byte Array訊息反序列化成正確的格式後,用外部系統的API送至外部系統。
這邊以MongoDB為例,僅說明Sink Connector需要的Converter設定,關於Source Connector可以在MongoDB的官方說明頁面,將Tab切換到Source,就可以看到相關說明。
設定可以用修改Properties設定檔的方式,也可以用Kafka Connect提供的Rest API,在新增Connector時指定。本文使用Rest API的方式,因為較為方便,且不用重新啟動Kafka Connect。
相關API設定可以往下搜尋使用Kafka Connect REST API來新增Connector instance
簡單來說,需要指定存入Kafka的訊息中,key和value各自要使用什麼Converter進行序列化,並且要定義資料的Schema (Optional,可以忽略),以確保資料的格式和結構正確:
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false //如果不把這個關掉, 在producer寫入資料時,就需要加入” schema”這個欄位, 來告訴Converter 目標MongoDB Collection的Schema是什麼
整體而言,將資料匯入Kafka (Source Connnector),以及將資料匯出到外部系統 (Sink Connnector) 的流程如下圖: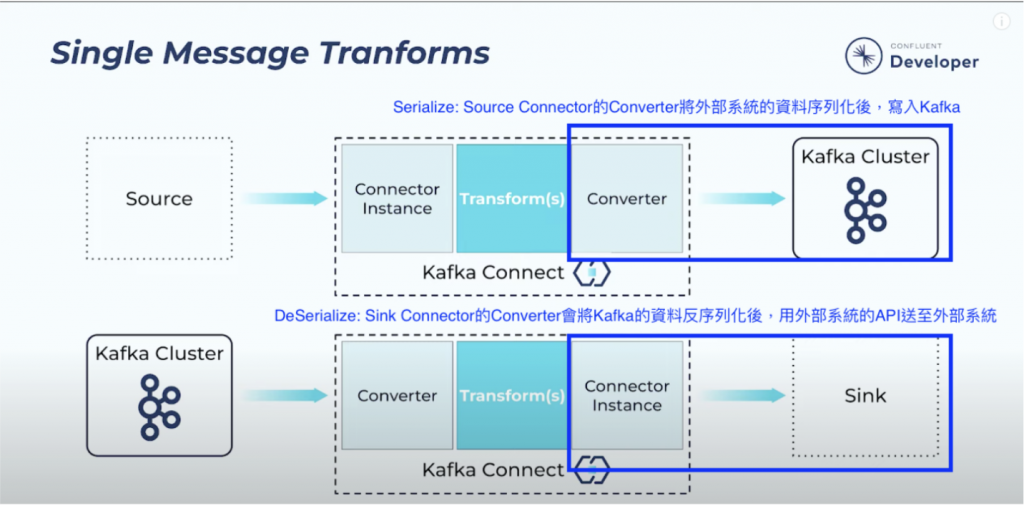
截圖修改自官方Youtube
這邊以將資料匯出至MongoDB為例,介紹Sink Connector的操作步驟:
1.下載Connector jar檔到正確路徑
jar: Java compiler以後的檔案, 這邊的內容是各廠牌DB的Connector實作
Mongo有提供connector jar檔的載點:
https://www.mongodb.com/docs/kafka-connector/current/introduction/install/#download-a-connector-jar-file
1.8.1的載點
https://search.maven.org/artifact/org.mongodb.kafka/mongo-kafka-connect/1.8.1/jar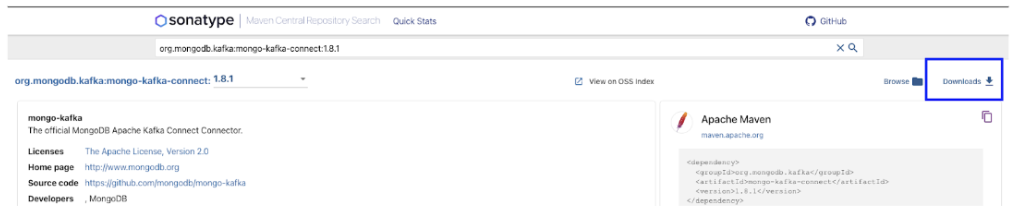
檔名後綴的意義
all是完整的, 包含connector本身還有所有dependencies, 這邊都使用all
把下載後的檔案放到kafka可以讀取的路徑,例如: ./kafka/tmp
2.設定Kafka Connect Config
需要在設定檔裡面設定plugin.path指定Connector jar檔的路徑
由於我們是使用分散式模式,所以設定的是connect-distributed.properties
docker exec -it local_kafka
vi /opt/bitnami/kafka/config/connect-distributed.properties
...
plugin.path=/bitnami/kafka/tmp/mongo-kafka-connect-1.8.1-all.jar

connect-distributed.sh
docker exec -it local_kafka /opt/bitnami/kafka/bin/connect-distributed.sh /opt/bitnami/kafka/config/connect-distributed.properties
curl -X POST -H "Content-Type: application/json" --data '
{"name": "mongo-sink",
"config": {
"connector.class":"com.mongodb.kafka.connect.MongoSinkConnector",
"topics":"quickstart_mongo",
"connection.uri":"mongodb://local_mongo:27017",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"database":"local",
"collection":"test_collection"
}
}
' http://0.0.0.0:8083/connectors -w "\n"
這邊我們在JSON中的 topics: 指定quickstart_mongo作為我們監聽的Topic,目的是當Producer寫入訊息到quickstart_mongo時,透過Connector自動將資料輸出到指定的MongoDB(連線方式如connection.uri所設定)
5.使用kafka的console程式: kafka-topics.sh,來檢視目前已建立的topic
docker exec -it local_kafka /opt/bitnami/kafka/bin/kafka-topics.sh --zookeeper zookeeper:2181 --list
回應的topic清單應該包含剛剛建立Sink connector指定的quickstart_mongo
kafka-console-producer.sh 充當producer,寫入簡單的測試訊息docker exec -it kafka /opt/bitnami/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic quickstart_mongo
出現 > 代表可輸入要寫進去topic的內容, 預設是json格式
ex: >{"testing":"aaaaaaaaaaaa"}
如果上述設定正確,就可以看到MongoDB的資料被寫入producer傳送的訊息。
以上就是Kafka Connector的簡介,以及一個簡單的MongoDB Sink Connector操作示例,希望對有相關需求的人有所幫助。
https://www.mongodb.com/docs/kafka-connector/current/introduction/converters/#overview
https://www.mongodb.com/docs/kafka-connector/current/tutorials/sink-connector/
https://docs.confluent.io/platform/current/connect/index.html

