作為本系列的最後一篇文章,本文將整理專案中已完成的項目,以及未來想到的改善方向。
涵蓋範圍包括:
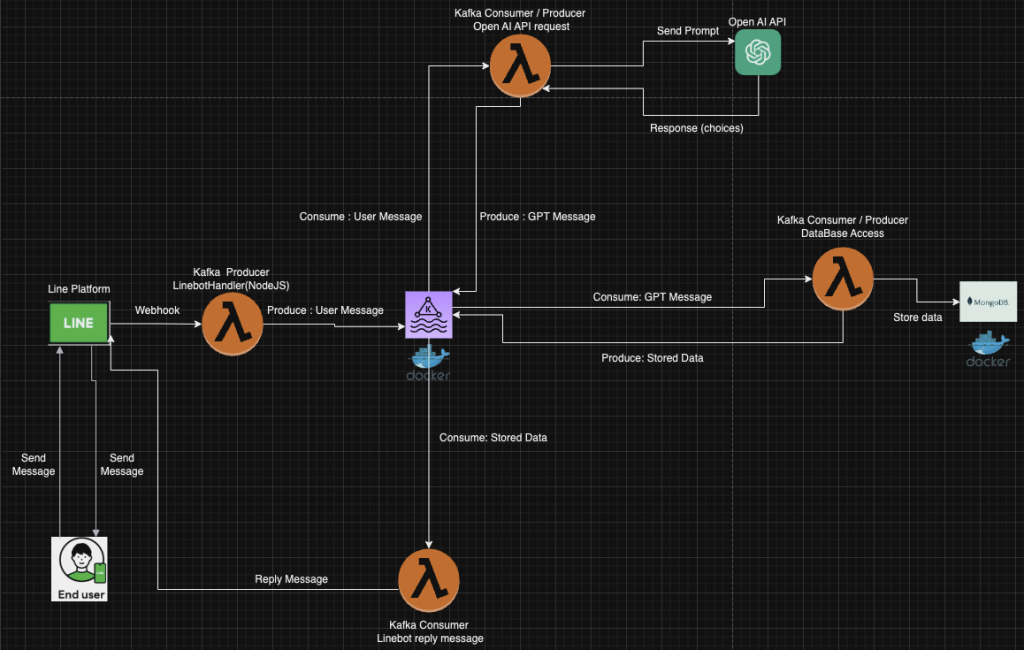
KafkaListener(Kafka Consumer)在訂閱的Topic收到新的LINE User資訊後,提取Reply Token及使用者訊息,並且交給openAiApiService做後續處理。openAiApiService會將User輸入的訊息,連同我們設定好的System Message、Token,Endpoint等資訊做成Prompt,並且透過API將Prompt送給Open AI ChatGPT。lineMessagingClient回覆LINE Platform程式碼如下:
@KafkaListener(id = "${spring.kafka.consumer.id}", topics = "${spring.kafka.consumer.topic}", containerFactory = "userDataListenerContainerFactory")
public void UserDataListener(UserData userData) {
try {
// 提取Reply Token
String replyToken = userData.getReplyToken();
String userId = userData.getUserId();
// 提取使用者訊息
String text = userData.getText();
// 透過API將Prompt送給Open AI ChatGPT
String openAiResponse = openAiApiService.sendMessage(null, text);
// 記錄到MongoDB
boolean storeStatus = saveTrainingDataToMongodb(openAiResponse, userId);
String replyMessage = "Your message is: " + text + "\nResponse: " + openAiResponse + "\n storeStatus: " + storeStatus;
// 回覆LINE Platform
lineMessagingClient.replyMessage(new ReplyMessage(replyToken, new TextMessage(replyMessage))).get()
.getMessage();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
functionName="${function:=LinebotHandlerNode}"
zip -r $functionName.zip index.js utils .env node_modules
aws lambda update-function-code --function-name $functionName --zip-file fileb://$functionName.zip
mvn clean package
scp target/nextpage-line-bot-server-0.0.1-SNAPSHOT.jar ec2-user@AWS EC2位址:/home/ec2-user
2.在EC2中使用下面指令,在背景執行Bot Server
sudo nohup java -jar -Xmx100m nextpage-line-bot-server-0.0.1-SNAPSHOT.jar 2 > /dev/null > line-bot.error &
3.可以用tail -f line-bot.error檢視是否有錯誤訊息。
version: "2"
services:
mongodb:
image: mongo:6.0.4
container_name: mongodb
restart: unless-stopped
environment:
- MONGO_INITDB_ROOT_USERNAME=root
- MONGO_INITDB_ROOT_PASSWORD=root密碼
- MONGO_INITDB_DATABASE=資料庫名稱
volumes:
- ./mongodb/initdb.d/:/docker-entrypoint-initdb.d/
- MONGO_VOLUMES:/data/db
ports:
- 27017:27017
zookeeper:
image: zookeeper:3.4
mem_limit: 104857600
container_name: zookeeper
restart: unless-stopped
ports:
# exposing for debug reason
- 2181:2181
volumes:
- "./zookeeper/data:/data"
- "./zookeeper/datalog:/datalog"
- "./zookeeper/zoo.cfg:/conf/zoo.cfg"
kafka:
image: 'bitnami/kafka:2.1.1'
hostname: localhost
container_name: kafka
restart: unless-stopped
ports:
# 方便從host call Kafka Connect 的Rest API (8083 port)
- '8083:8083'
- '9092:9092'
# expose the external port for external clients
- '9093:9093'
environment:
# Kafka defaults to the following jvm memory parameters which mean that kafka will allocate 1GB at startup and use a maximum of 1GB of memory
- KAFKA_HEAP_OPTS=-Xmx512m -Xms256m
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
# set listeners and advertised listeners for external (9093) and internal(9092)
- KAFKA_LISTENERS=INTERNAL://0.0.0.0:9092,EXTERNAL://0.0.0.0:9093
- KAFKA_ADVERTISED_LISTENERS=INTERNAL://localhost:9092,EXTERNAL://AWS EC2位置:9093
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL
#- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1
volumes:
- KAFKA_VOLUMES:/bitnami/kafka
depends_on:
- zookeeper
volumes:
MONGO_VOLUMES:
KAFKA_VOLUMES:
在手機版LINE上簡單測試如下:
1.深蹲的訓練記錄
2.飲食紀錄
可參考相當臨時的Demo影片
都讓OpenAI用同一份JSON Schema做回覆。 只要定好容許Null的欄位(例如: 訓練記錄中並不需要protein或者fat這類營養素的欄位),這樣或許就可以使用Structured Outputs來取代Prompt中為了指定Json Schema加入的大量說明。無論是在團隊還是個人專案中,我一直很羨慕那些能夠快速想出點子並馬上付諸實現的人。相比之下,我沒有那麼厲害的大腦。
這次鐵人賽的內容,其實是過去3年左右的零散時間,在摸索技術時留下來的筆記,即便如此,做出來的東西也沒有非常驚艷,寫文章時也常常發現不足的地方並盡量補足。
然而,這個過程確實有一種把某個大事逐漸完成的踏實感。有時翻看過去的筆記,會回想起自己當時的確有花時間和力氣研究某個內容而得到的成就感,當然也有不知道自己當時在幹嘛的無力感。總之和重量訓練一樣,就是個和自己對話的過程。
非常感謝鐵人賽給我這個機會完成這件事情。雖然不是什麼很潮的東西,但我希望這系列文章能夠對那些對技術感興趣的人,或者正在被Dead Line壓的快沒時間睡覺的人,提供一點幫助。
以下是我的聯絡方式,如果對專案有問題或者有想要交流或討論的地方,歡迎聯絡。
Henry
E-mail: breezesky627@gmail.com
Medium: https://medium.com/@cancerpio

