我們已經從資料的前處理階段(LINE Platform Webhook 處理),一路走到了暫存資料(Kafka)及最終的儲存資料(MongoDB)。作為這個系列文章的最後一部分,將把焦點放在專案的最終階段: 利用OpenAI來進行語意判斷,並提取需要儲存和回應的資訊。本篇會介紹OpenAI的基本觀念,以及我們專案中所使用的Chat Completion功能。最後,還會介紹我們使用的Java library。
內容包含:
OpenAI是一家專注於開發人工智慧技術的公司,其技術範疇涵蓋自然語言處理、圖像生成等領域。這些技術以模型(Model)的形式被廣泛應用於各種服務中。
GPT 系列模型的實作。GPT是一種自然語言處理模型,能夠理解人類語言,並根據需求生成大綱、滿足語意或格式要求的文件,甚至模擬不同角色的回應(例如客服人員或某領域專家)。Simple, Specific, Short,簡單來說,越短越好,即便用單字組成,不管文法的描述,他也能生成程式,例如這種promt: functino get db sum data,Copilot真的能生出一段計算加總的Function。有範例就加分
我們設定的條件或角色,去做接下來的回應,也就是把一段對話繼續聊下去。messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
你是一個助理,現在我想問你...。包裝給AI的指令(Prompt)以外,也包含角色設定(Role),前置條件(上文),以及格式處理,例如我們可以在Prompt中預設User會輸入訓練記錄或者飲食兩種情境,並要求GPT分別做不同的處理。一個基本範例如下:
curl https://api.openai.com/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ${你的API Token}' \
-d '{
"prompt":"如果以下段落在描述訓練,列出動作名稱,訓練組數,次數,以及重量,如果在描述飲食,列出食物名稱,還有這些食物的營養成分。中間要空行:深蹲115kg3組5下硬舉120kg5組3下洋芋片 蛋餅 鮮奶茶 鹹酥雞",
"max_tokens": 1,
"model": "text-davinci-003",
"max_tokens": 500
}'
註: GPT會把文字拆成token(字段,可以簡單想成單字的概念)處理
參數: max_token 是設定open AI最多可回應的token數目
Response如下:
Magic:
{
"id": "cmpl-6hcacsycbSA3c4GU3b9LIQBlWLo64",
"object": "text_completion",
"created": 1675854462,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\n深蹲 115kg 3組 5下 硬舉 120kg 5組 3下 \n\n洋芋片:卡路里 439 kcal 、碳水化合物 68.3克、蛋白質 6.6克、脂肪 18.8克; \n\n蛋餅:卡路里 151 kcal 、碳水化合物 15克、蛋白質 8克、脂肪 8克; \n\n鮮奶茶:卡路里 63 kcal 、碳水化合物 12.3克、蛋白質 3.3克、脂肪 0.7克; \n\n鹹酥雞:卡路里451 kcal 、碳水化合物31克、蛋白質21克、脂肪27克。",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 193,
"completion_tokens": 297,
"total_tokens": 490
}
}
curl https://api.openai.com/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ${你的API Token}' \
-d '{
"prompt":"如果以下段落在描述訓練,列出動作名稱,訓練組數,次數,以及重量,如果在描述飲食,列出食物名稱,還有這些食物的營養成分。中間要空行並整理成JSON格式:深蹲115kg3組5下硬舉120kg5組3下洋芋片 蛋餅 鮮奶茶 鹹酥雞",
"max_tokens": 1,
"model": "text-davinci-003",
"max_tokens": 500
}'
{
"id": "cmpl-6hcdrQVOI0tjvkL75QKEVlhjveAj4",
"object": "text_completion",
"created": 1675854663,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\n{\"訓練\": [{\"動作名稱\": \"深蹲\", \"訓練組數\": 3, \"次數\": 5, \"重量\": 115},{\"動作名稱\": \"硬舉\", \"訓練組數\": 5, \"次數\": 3, \"重量\": 120}],\n\"飲食\": [{\"食物名稱\": \"洋芋片\", \"營養成分\": \"\"}, {\"食物名稱\": \"蛋餅\", \"營養成分\": \"\"}, {\"食物名稱\": \"鮮奶茶\", \"營養成分\": \"\"}, {\"食物名稱\": \"鹹酥雞\", \"營養成分\": \"\"}]}",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 206,
"completion_tokens": 254,
"total_tokens": 460
}
}
可以看到,text的內容真的是可用的JSON格式。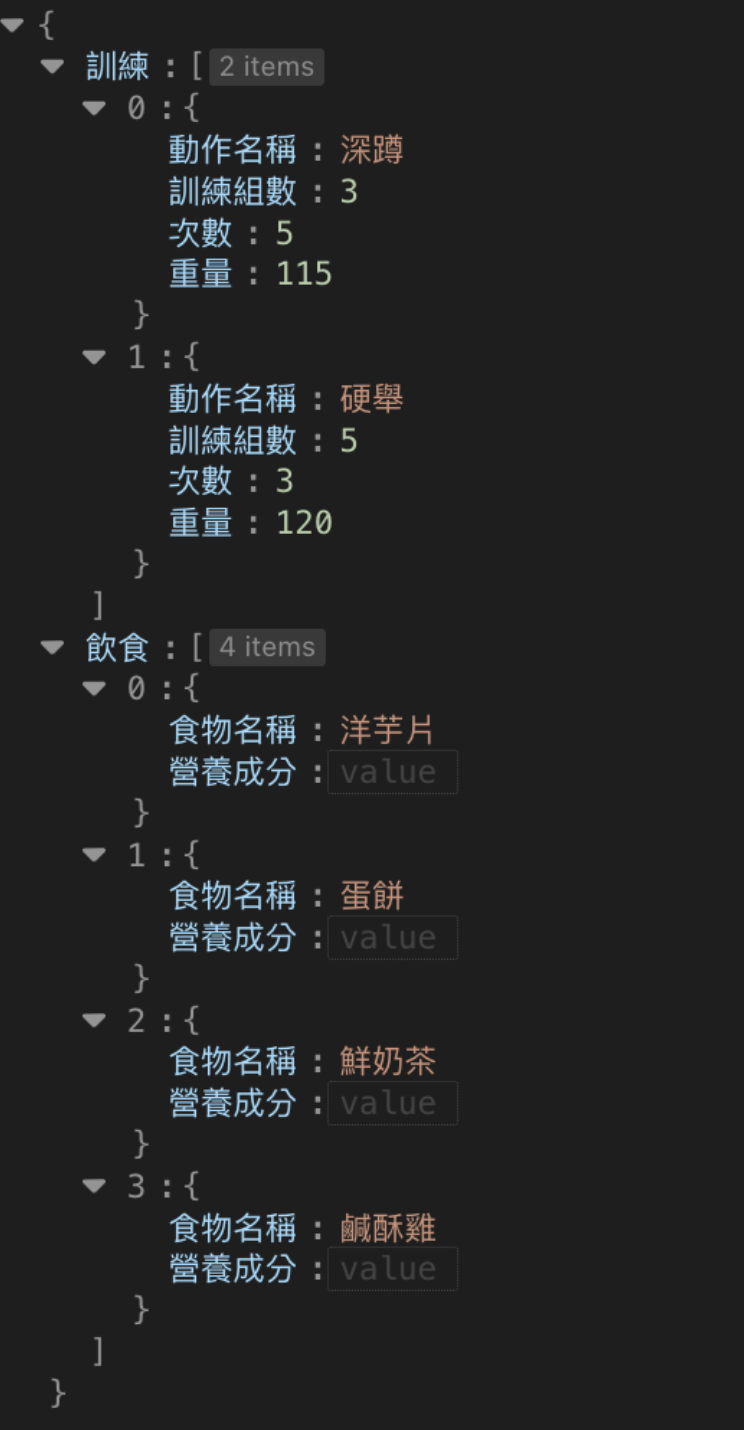
圖:在JSON驗證網站上整理後的回應
光是把這些資訊從訊息中提取,並且對應到正確的欄位,程式就有了依照結構保存資料的依據,就可以大幅減少User在UI上所做的重複點擊數。
圖: 如我們在專案緣起提到的,上述資訊在App的UI上還是需要不少點擊和消耗眼力的過程
官網有提供程式可呼叫的API,你可以透過不同程式語言實作的Library,也可以透過官網提供的Curl範例,例如所有Chat Completion相關的API清單可以看這裡。
圖: 官方提供的API Reference及相關資訊
以下介紹官網介紹的Java Library:
OpenAiService service = new OpenAiService("your_token");
CompletionRequest completionRequest = CompletionRequest.builder()
.prompt("Somebody once told me the world is gonna roll me")
.model("babbage-002"")
.echo(true)
.build();
service.createCompletion(completionRequest).getChoices().forEach(System.out::println);
OpenAiService service = new OpenAiService(token, ofSeconds(50));
rate limit上限,這有可能是程式寫錯造成Request數超過單位時間內的限制,或者別的原因。curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${你的API Token}" \
-d '{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
}'
Response如下:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"param": null,
"code": null
}
}
"message": "You exceeded your current quota, please check your plan and billing details.")。Chat Completion,來包裝前提(Preface)、角色(Role)和實際的指令(Prompt),讓AI根據不同的情境提供我們所需的內容。這也正是專案的核心目標: 為應用程式提供一個自然語言介面的實作方式。https://platform.openai.com/docs/models


 iThome鐵人賽
iThome鐵人賽