到今天會是在資料工程領域的最後一篇文,我想來分享一些我們在初期打造資料基礎建設,又想要更早體驗、試驗價值的一些土砲型解決方案,回頭看會覺得很好笑很陽春,但每個決策、每個解決方案都有他當下的時空背景和限制,這是我想和你們分享的真實體會。
前面的分享有提到我們在最一開始選擇用 BigQuery 的原因,有蠻大一部分是 AWS 好貴,預開機器要 USD $1800 / 月,身為一個四年小新創還在摸索 PMF的階段,根本花不起,作為一個為老闆分憂解勞的打工仔,剛好遇到當年GCP 大會,介紹GCP BigQuery 是by 查詢量收費USD$5/TB,是個天大的好消息!
順著這個邏輯,有個尷尬的問題發生了,我們的 MySQL 是在 AWS上,要怎麼把資料從 AWS 流過來 BigQuery呢?
當時也有很多『收費』的服務,但說真的我沒辦法很好的說服主管還要增加投資(我當時大概只是個工作不到兩年的小白QQ),於是乎我想自己來匯出 MySQL 的資料看看。
這步驟也不難,就是跑 mysqldump 這樣的指令,去把我需要的資料表,按照我要的條件每天匯出,有些表比較小我就是整包倒出來,有些表是記錄表,考量到columnar database 的設計,我就匯出每天的資料,incremental 的匯入到 BigQuery,並做好 time partition來節省查詢成本。
匯出不難,匯入這段就很痛苦了,MySQL匯出後,基本上是一包 csv ,但資料裡面包含的內容,可能會導致匯入 BigQuery 的時候解析失敗,所以需要持續去排除『字串』的內容問題,但用R, Python 處理大量的文字資料其實非常慢,於是我想起了大學修過的一門課 UNIX系統程式設計…
Sed 是一個 bash 裡強大的文字處理工具,語法非常…極度的簡潔,可以說是很好寫,也可以說不太好寫。有另一個好兄弟是 awk ,語法會更平易近人一些,基本上就是C的語法,只是可以在 bash 中快速執行,並且也擁有很高效的文字處理速度!因為覺得實在太好用,就快速跟大家分享一下 Sed:
sed 指令/pattern/replacement/flags
- 指令:我們就講最常見的 “s”,代表 substitute,取代符合 pattern的內容
- pattern:就是寫正規表達式,或是你想取代的字串
- replacement:就是符合pattern的字串,你想取代的目標內容
- flags:用來做一些條件,例如 "g" 代表取代所有符合pattern的內容
(通常會加上g,因為sed只會跑第一列,加上g後就可以處理整份csv)
假設有一個名為 employees.csv 的 CSV 檔案,內容如下:
ID,Name,Department,Salary
1,John Doe,Sales,50000
2,Jane Smith,Marketing,55000
3,Bob Johnson,Sales,45000
4,Alice Williams,HR,60000
5,Chris Evans,IT,70000
6,Nancy Brown,Marketing,52000
7,David Wilson,Sales,48000
8,Laura Davis,IT,73000
9,Michael Miller,HR,61000
10,Emily Taylor,IT,72000
你可以打開你的terminal 試試看:
sed 's/Sales/Business Development/g' employees.csv > employees_updated.csv
解釋:
• sed 's/Sales/Business Development/g' employees.csv:將 employees.csv
中所有的 Sales 替換為 Business Development。
• > employees_updated.csv:將結果輸出到新的檔案 employees_updated.csv。
ID,Name,Department,Salary
1,John Doe,Business Development,50000
2,Jane Smith,Marketing,55000
3,Bob Johnson,Business Development,45000
4,Alice Williams,HR,60000
5,Chris Evans,IT,70000
6,Nancy Brown,Marketing,52000
7,David Wilson,Business Development,48000
8,Laura Davis,IT,73000
9,Michael Miller,HR,61000
10,Emily Taylor,IT,72000
最一開始我們在找尋BI 工具的時候,最直覺就是 Google DataStudio(現在叫 Looker Studio),因為他最直接完全不需要架設伺服器,也可以連接 BigQuery 的資料表,甚至可以和舊版的GA連接,在那時候GA匯出資料是需要費用的,算是非常好用,但我心中一直有個解不開的疑惑:請問Google 出個資料夾功能有這麼難嗎?到現在名字都改成looker了,還沒有資料夾...
這裡我不打算講太多啦,邏輯就是透過 Google Appscript 建立自己的資料連接器,如下圖。
其實不是非常困難,困難的是Google 的文件非常難讀,寫的範例通常也沒辦法一次跑成功,所以那陣子就是四處通靈不同版本的文件,每個都說可以跑,其實都不能跑,東拼西湊才終於拼出一個可以執行的版本,厲害的是也沒有什麼效能問題XD 還是serverless ,真的是土炮的極限了!
真的有興趣可以搜尋** DataStudio Appscript connector**
在產品內,後端會打這是哪個班級的參數過來,DA透過 Google AppScript 去
讓 DataStudio 的儀表板可以吃參數,動態把參數塞進儀表板的篩選器,讓用戶進
來可以看到他該看到的數據儀表板。
今天是資料工程的最後一篇文,分享了兩個蠻初期的拓荒故事,幸運的是後來很快就證明做OLAP,以及資料服務帶來的價值,所以團隊擴編,也把這些可怕的東西逐漸淘汰了。
聽起來很痛苦很荒謬,不過我蠻樂在其中的,我想分享這兩個小故事的關鍵是在推行一個完全不存在的事情,會遇到包含技術困難、主管還不理解而不支持、沒錢、人力有限等等困難,現實總是有很多限制,但怎麼突破限制就是你的價值所在了,我蠻喜歡一個產品持續迭代的圖:
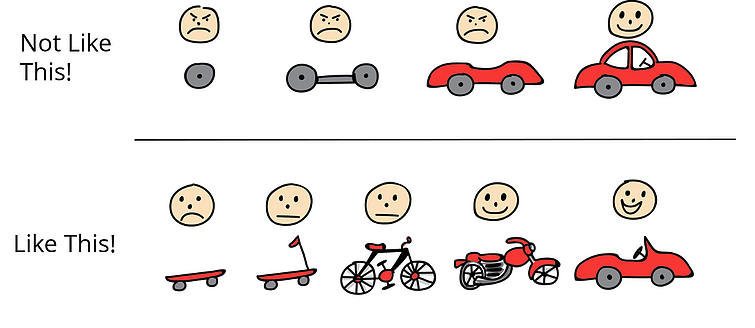
圖片來源:https://fcbb.org/mvp-concept-understand-the-mindset-of-successful-start-ups/
不管方法好壞,在一開始最重要的是PoC,一個end-to-end 的解決方案,而不是一開始就想打造一個很完美很厲害的汽車,你要解決的是『移動』的問題,而不是要解決『無法打造汽車』的問題。
接下來我們即將進入資料分析的篇章~

