監控的目的在於讓我們更早知道有事件發生,並能夠針對事件採取應對措施,以避免演變成更大的危機。但不可能透過人眼 24 小時盯著 Dashboard 觀察是否有異常,所以大多數的監控工具都會搭配告警機制,透過預先設定的條件觸發通知。Grafana 的 Alerting 可以定時執行查詢語法並判斷是否達到定義的觸發條件,觸發後再根據設定發送告警到指定的目標,例如 Slack 訊息、Webhook、Email 等。
Alerting 架構如下圖,最基礎的方式是 Alert Rule 定義查詢語法、查詢頻率、觸發條件與通知設定等。當被監控的 Alert instances 達到 Alert Rule 的觸發條件後,會把相關資訊根據 Alert Rule 的設定發送給 Contact Point。
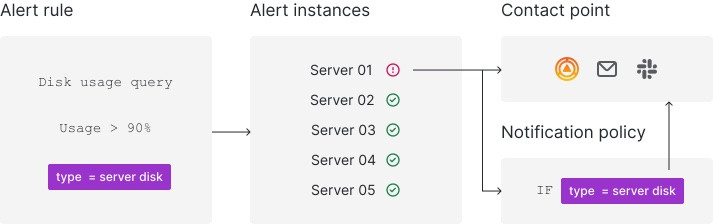
圖片來源:Grafana
Alert Rule 可以從兩個地方新增:
可以直接在 Alerting 選單內新增 Alert Rule
也可以在 Panel 編輯頁的 Alert 頁籤新增 Alert Rule
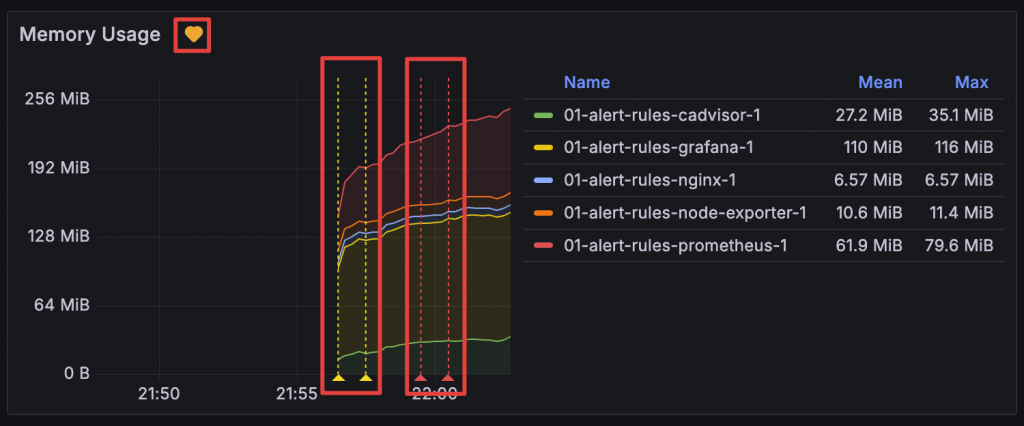
Alert 與 Panel 關聯後可以在 Panel 上看到 Alert 觸發的資訊
新增 Alert Rule 時依序有以下資訊區塊可以設定:
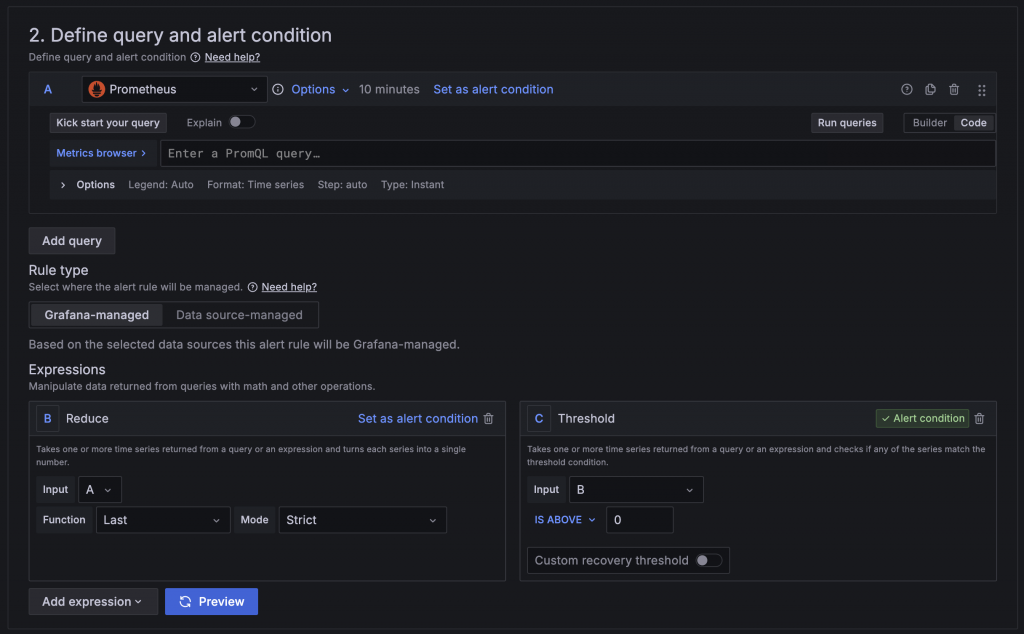
在這區設定中需要設定查詢與觸發條件,分別為:
Query:用於查詢需要判斷的指標與數值,可以設定多組,也能夠選擇不同的 Data Source。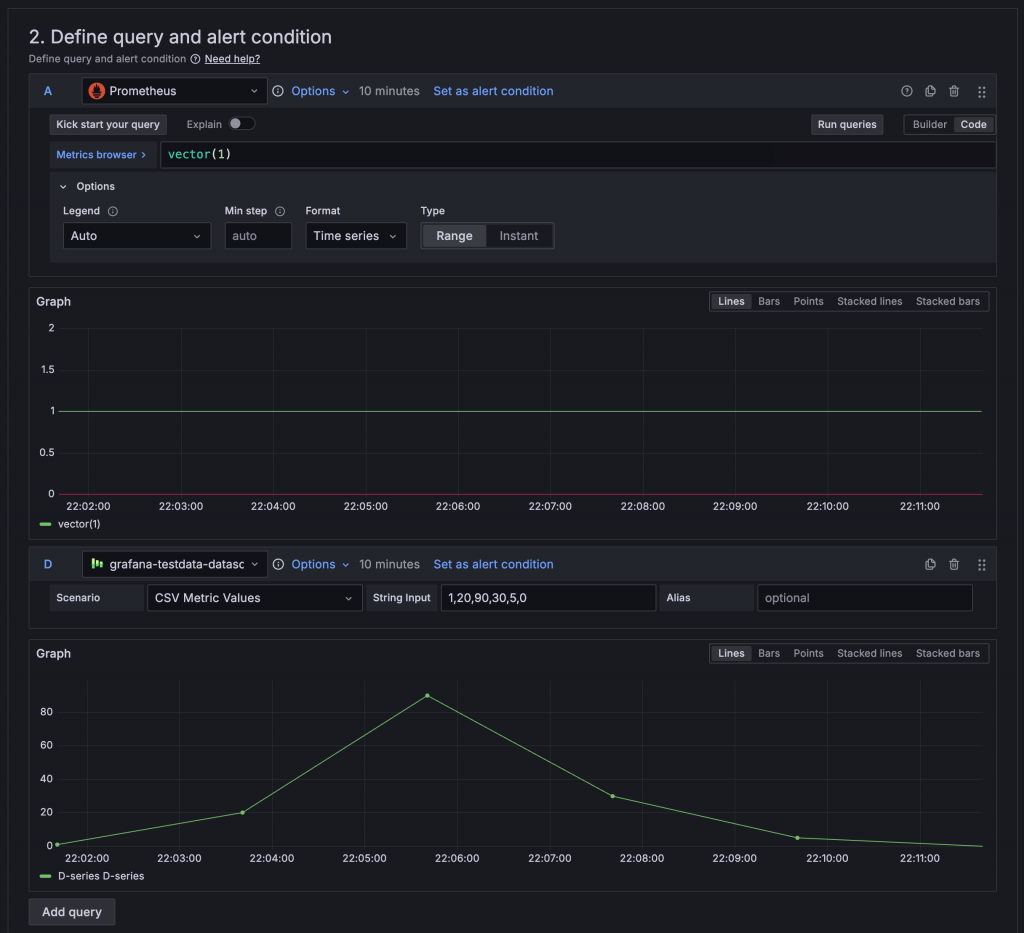
Expression:用於計算 Query 查詢結果與設定觸發條件,可以設定多組,常用的有:
在 Query 與 Expression 中設定的名稱會作為後續其他 Expression 使用的依據,在 Math 中則是使用 ${名稱} 的格式取用資料,例如將 Query A 與 Query B 的數值相加 $A + $B。設定完 Query 與 Expression 需要再選定一組作為 Alert condition,被選定的值如果為 True 或不等於 0 就會被判定為觸發。
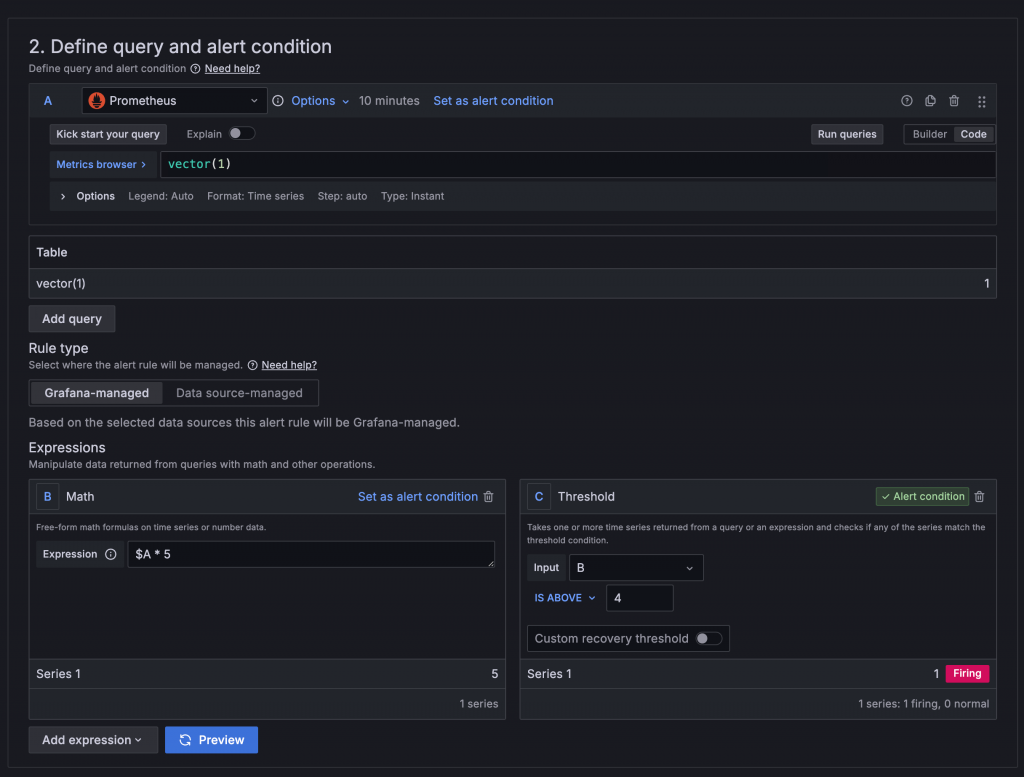
在 Query 與 Expression 的右上角有 Set as alert condition 按鈕可以設定為 Alert condition
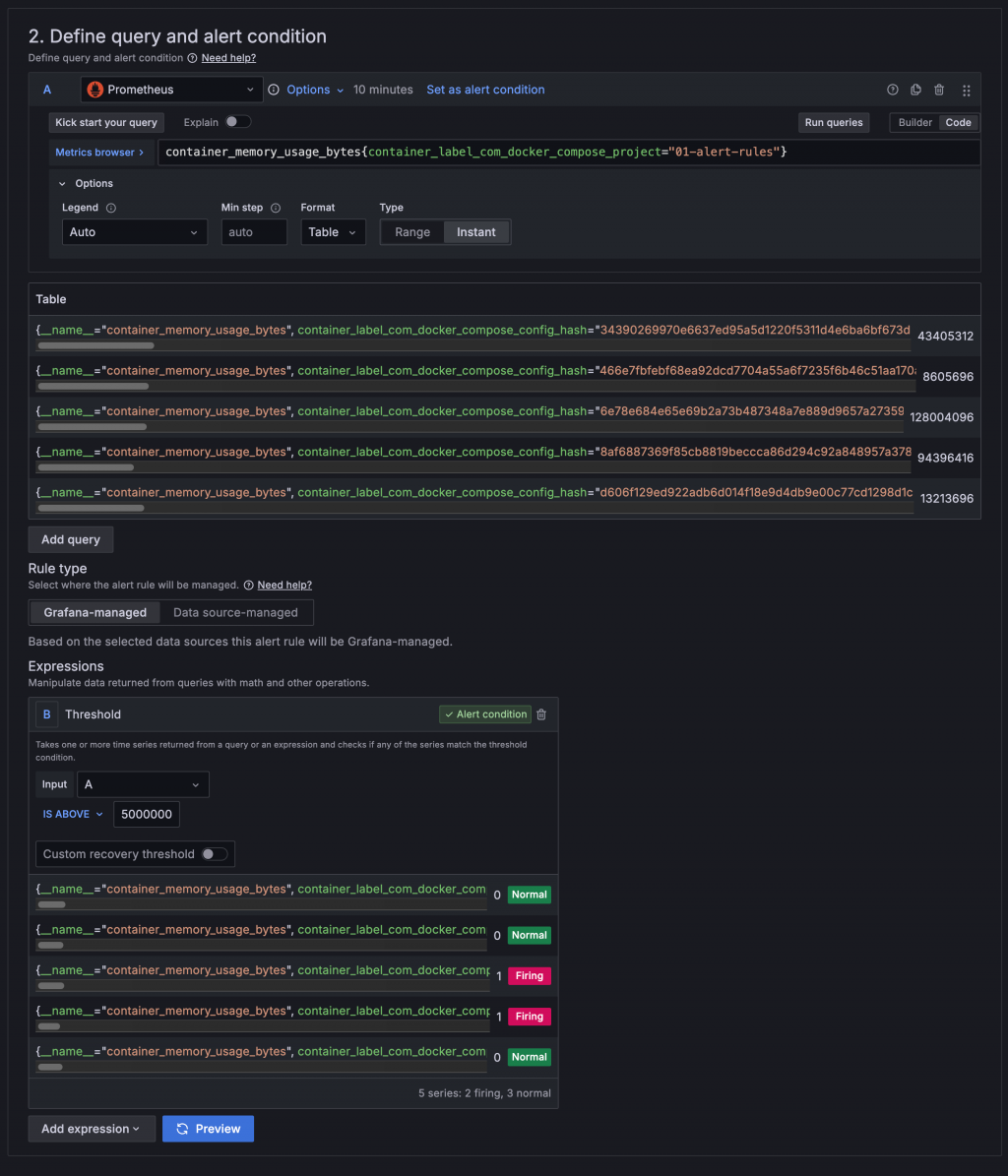
在使用 Prometheus 作為 Query 的資料來源時,如果查詢結果是多筆時間序列,Alerting 可以同時個別監控不同的目標,這些不同的目標稱為 Instance。例如 cAdvisor 的 container_memory_usage_bytes Metrics 紀錄所有 Container 的記憶體用量,使用 container_memory_usage_bytes 作為 Query 時可以同時監控所有 Container 的 Memory 用量。
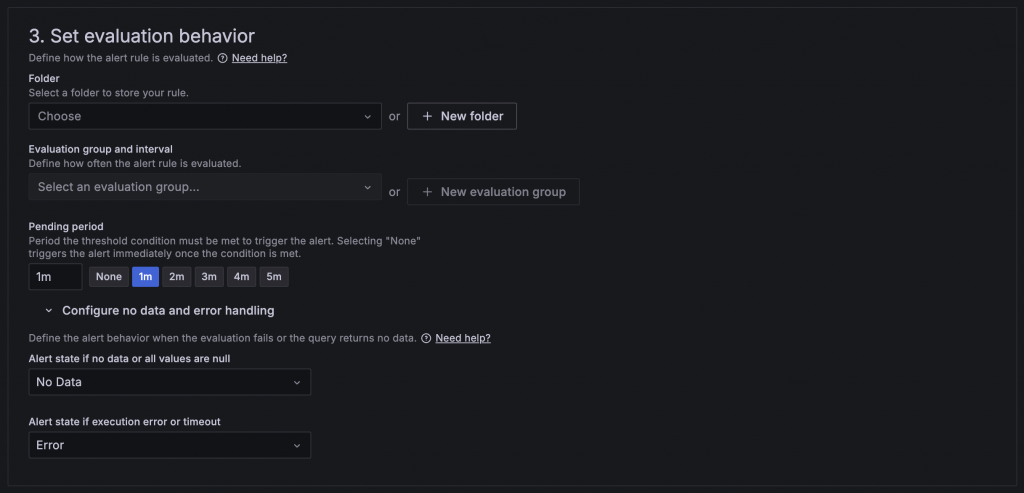
在這區設定中需要設定 Alert 的 Query 怎麼執行與怎樣被判斷為觸發,依序需要設定:
None 時會馬上發出告警。Alert 的狀態變化如下圖所示:在沒有達到 Alert condition 時,狀態為綠色 Normal;達到 Alert condition 後,會根據 Pending period 設定判斷是否停留在黃色 Pending,若在 Pending 期間恢復正常則會回到 Normal,否則超過 Pending period 則進入紅色 Alerting,狀況解除後會回歸 Normal。
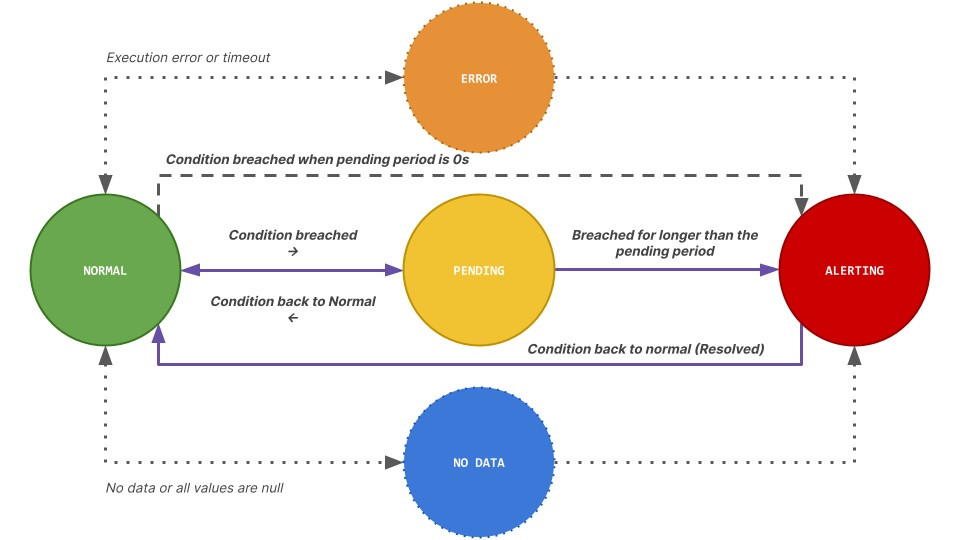
圖片來源:Grafana
在這區設定中可以設定 Alert 的 Label,以及當告警被觸發時要用哪種方式通知,有兩種方式:
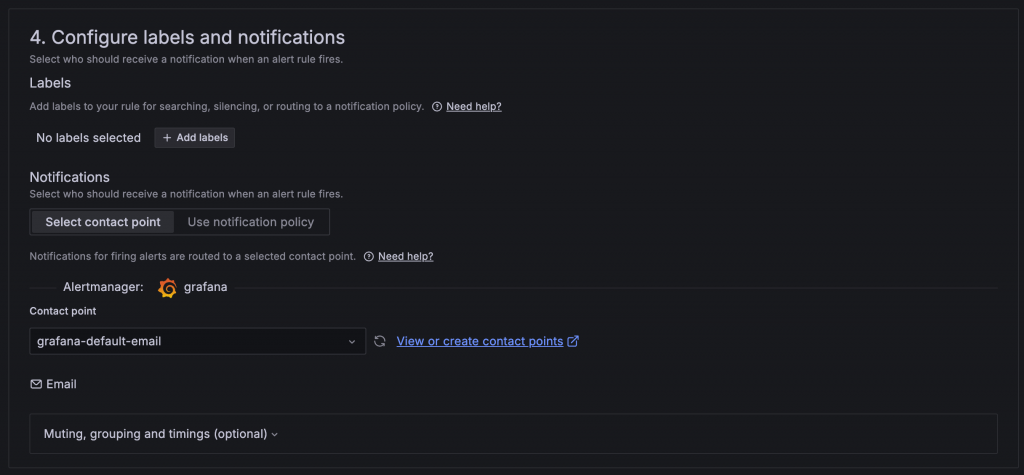
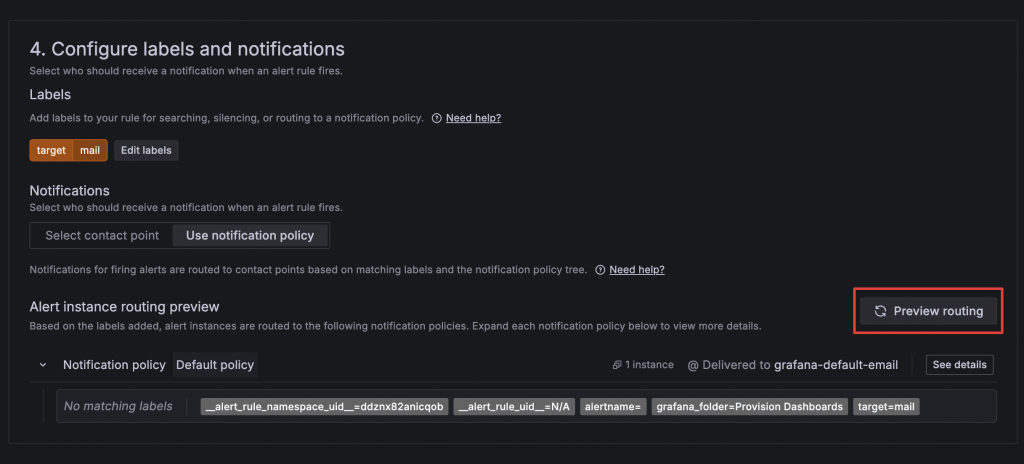
設定 Label 後可以點擊 Preview routing,檢查對應到哪個 Policy
如果在發送告警時有針對該 Alert 有其他內容想描述,可以透過 Annotation 功能,內容會包含在告警的訊息中。
在本章中,我們簡單介紹了 Alerting 的概念,包括 Alert Rule 的設定、檢查的邏輯,以及如何根據觸發條件發送通知。接下來的章節中,我們將實際設定 Alert、Contact Point 和 Notification Policy,深入體驗 Alerting 的效果,從而更好地掌握如何應用這些功能來優化系統的監控與管理。

