網路服務的狀態監控除了供工程師使用外,適當透漏給使用者知道狀況也是補救客戶滿意度的一種常見作法。通常會獨立建立一個 Status Page 供使用者確認狀況,例如 OpenAI 的 Status Page 與 GitHub 的 Status Page。如果要搭建自己的 Status Page,則可以使用 Gatus。Gatus 是一款開源的服務狀態監控工具,可以透過 HTTP、ICMP、TCP 與 DNS 查詢確認服務是否運作正常。提供監控的目標、方法與條件給 Gatus 後,Gatus 就會定時發送 Request 並檢查,並提供 Status Page 供視覺化查看。
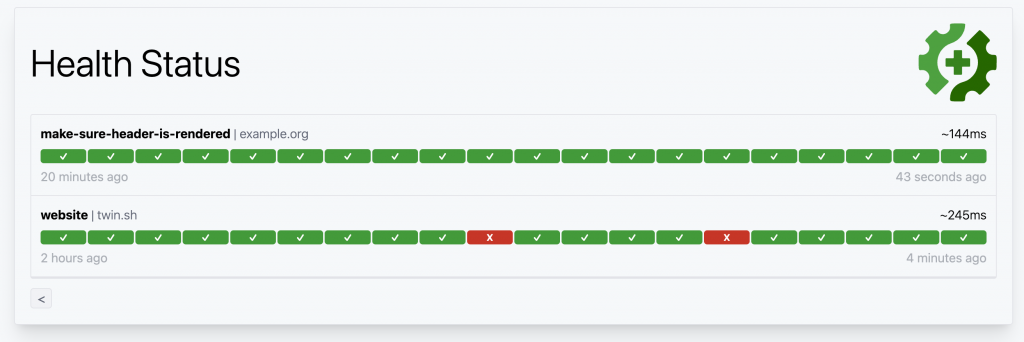
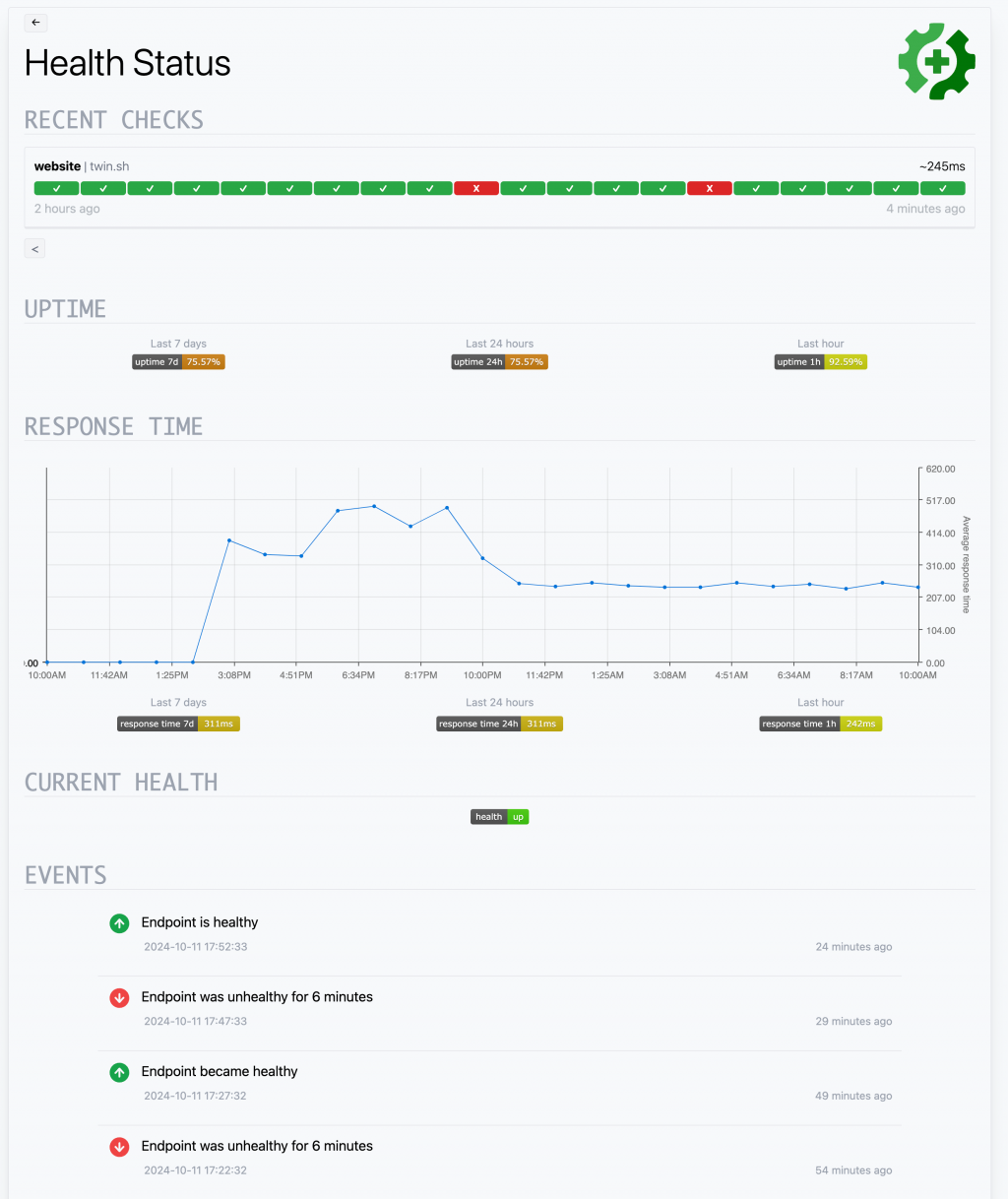
雖然 Gatus 提供了精美的 UI,但如果想要同時與其他指標進行對照比較,就無法僅依靠它的功能。因此,我們可以嘗試將 Gatus 採集到的資訊透過 Grafana 顯示,將監控數據整合到同一平台中。
當嘗試將新的資料源顯示在 Grafana 時,第一個動作是搜尋它本身是否有提供 Metrics 的功能。運氣很好,Gatus 直接提供了 Prometheus 格式的 Metrics,只需要在 YAML Config 中設定 metrics: true,就可以在 /metrics endpoint 上取得。
# HELP gatus_results_certificate_expiration_seconds Number of seconds until the certificate expires
# TYPE gatus_results_certificate_expiration_seconds gauge
gatus_results_certificate_expiration_seconds{group="",key="_make-sure-header-is-rendered",name="make-sure-header-is-rendered",type="HTTP"} 1.2297872783924121e+07
gatus_results_certificate_expiration_seconds{group="",key="_website",name="website",type="HTTP"} 2.690889188865997e+06
# HELP gatus_results_code_total Total number of results by code
# TYPE gatus_results_code_total counter
gatus_results_code_total{code="200",group="",key="_make-sure-header-is-rendered",name="make-sure-header-is-rendered",type="HTTP"} 5
gatus_results_code_total{code="200",group="",key="_website",name="website",type="HTTP"} 1
設定好 Metrics 後,就可以將它加入 Prometheus 的爬取清單中,讓 Prometheus 定時進行數據採集,最後在 Grafana 中進行查詢與顯示。
scrape_configs:
- job_name: 'gatus'
# metrics_path: '/metrics' # gatus 的 Metrics Path 跟預設一樣可以不設定
static_configs:
- targets: ['gatus:8080']
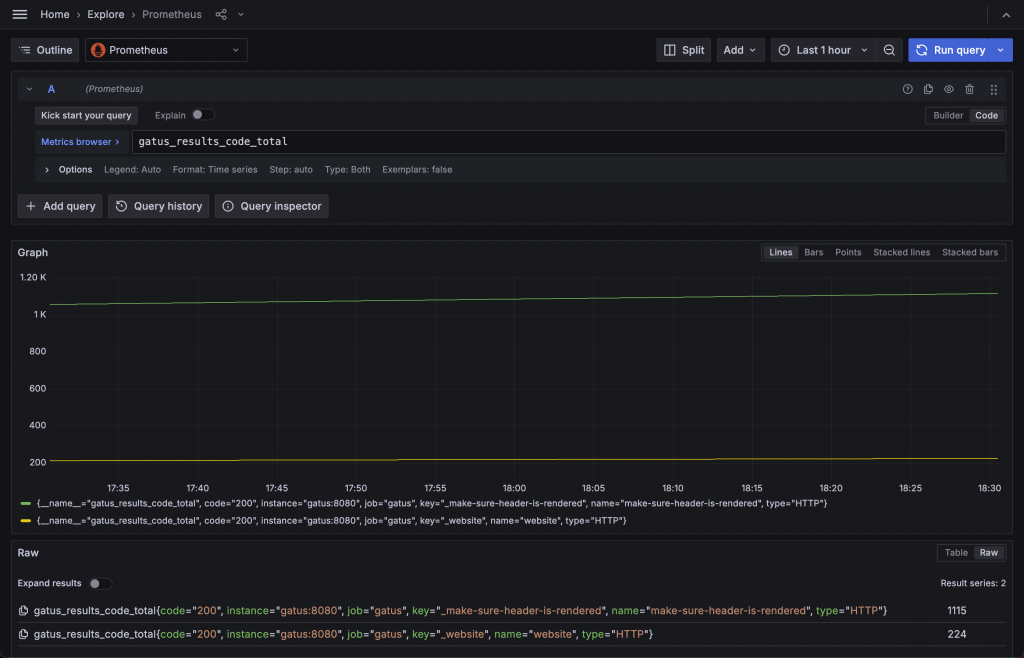
Steve Jobs 在 The Lost Interview 中回答怎麼知道產品方向是否正確時,引用了畢卡索的一句話:「Good artists copy, great artists steal.」傑出的藝術家模仿,偉大的藝術家盜竊。透過觀摩,可以讓我們不偏離正道。所以我們就直接來參考 Gatus 內建的 Status Page,看有哪些元素可以用來視覺化!
首先是最外層的 Index 頁面,一格一格的健康狀態,看起來就是 Status History 或是 State Timeline 的呈現方式。我們來看看 Metrics 中有沒有類似的資料可供使用吧。
這類健康狀態資訊可能有多種狀態,通常會以 Prometheus 的 Label 與 Label Value 表達。雖然 Grafana 的 Explore 功能提供了很好的 UI 來幫助查詢,但若 Prometheus 也同時收集其他服務的 Metrics,在上面探索這些指標時可能會被干擾。因此,我們可以直接在 Gatus 的 Metrics 頁面使用文字搜尋功能來查找。
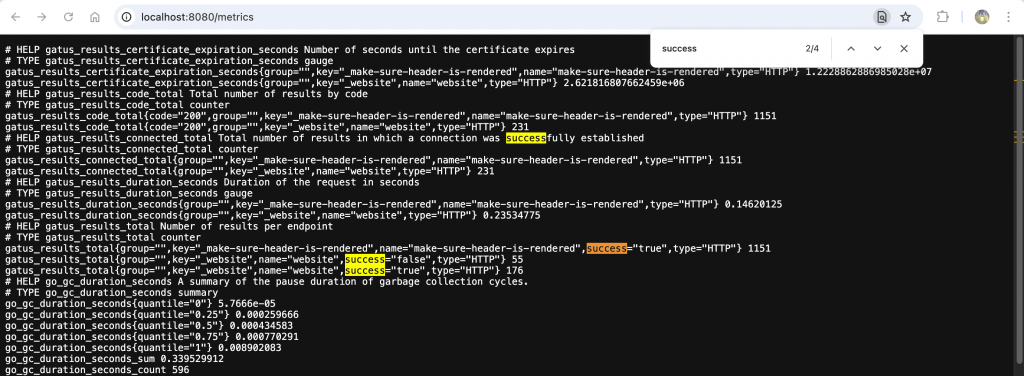
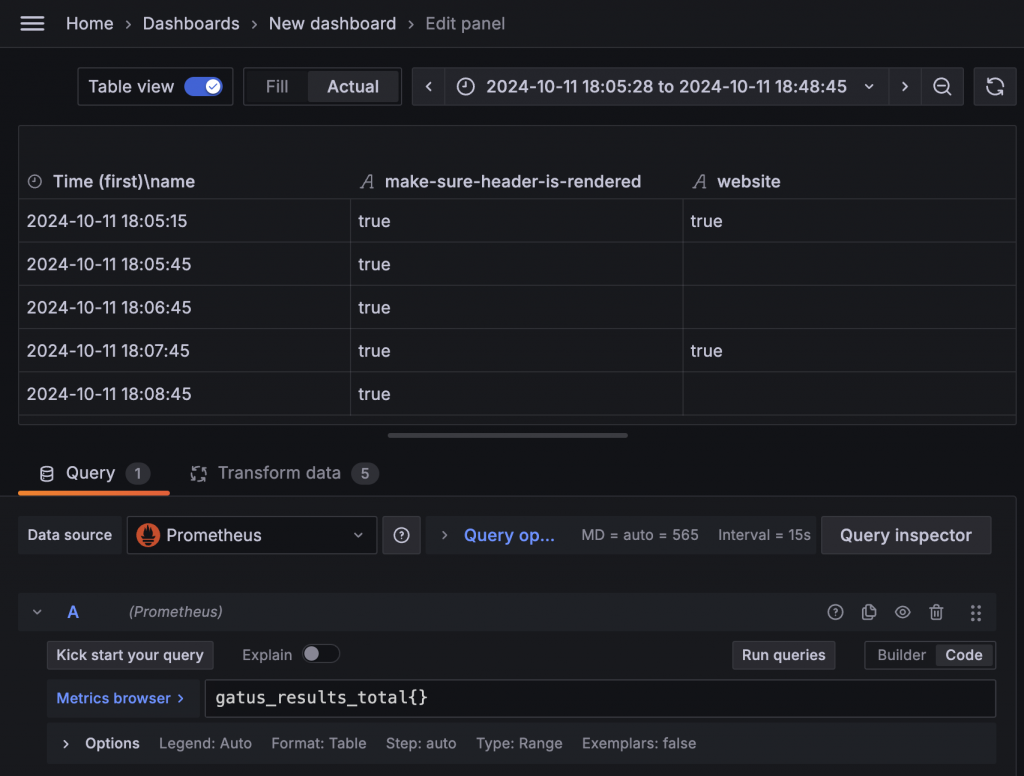
在 gatus_results_total 指標中,有一個 Label 叫做 success,內容有 true 與 false,另外還有 name 表示是哪個服務。這看起來就是我們想要的健康狀態。接著我們可以進入 Grafana 的 Explore,看看這個指標隨著時間的變化。
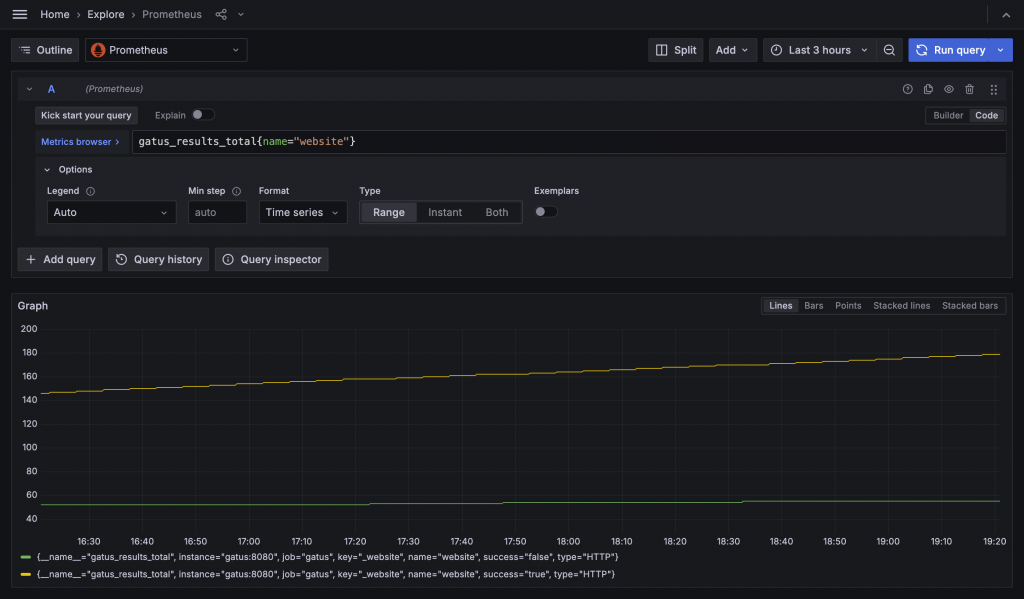
可以發現只搜尋目標服務 website 時,繪製出了兩條線,兩條線的差別在於 success label 有 true 與 false,然後會逐步升高。搭配 Gatus 的定期檢查邏輯後,可以推測出這個指標是每檢查一次就將成功與否的指標值加一。看起來這個 gatus_results_total 有機會讓我們做出狀態變化的圖表,接下來我們進到 Dashboard 中開始設計。
首先再次確認我們想要呈現的效果是 Status History 或是 State Timeline 這兩種模式。這兩種類型的資訊都是某個時間點同時只有一種狀態,並且每個服務只有一組數據。但我們的指標有 success true 與 false 各一組,且一直都有值。看來我們需要使用複雜的 Data Transform。我們可以先將 Prometheus 資料的查詢格式切換為 Table,再用 Table 格式來進一步發想。
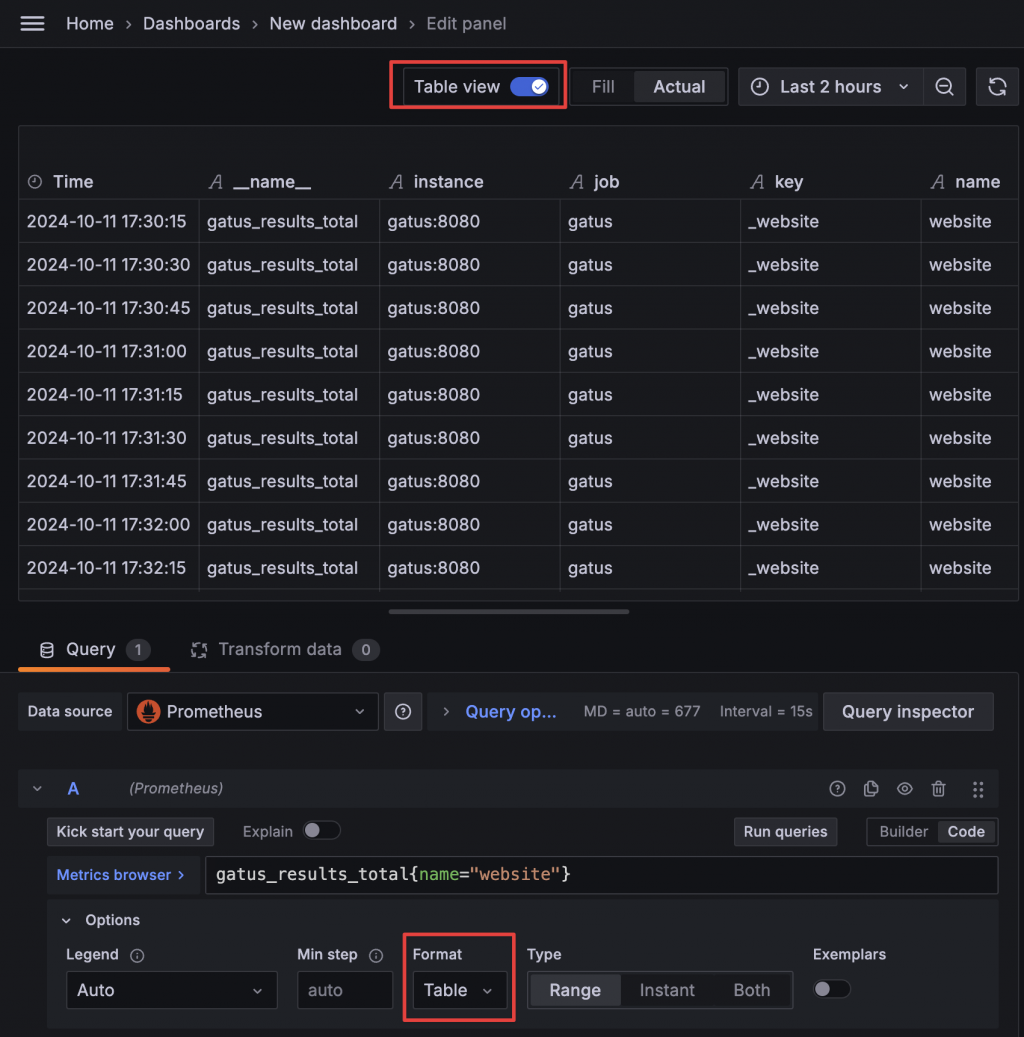
通常這時候就會進入望著數據發呆的狀況,可能還會搭配各種 Google 搜尋與詢問 CathGPT,然後發現被騙的迴圈中。再回顧一下我們想從這個指標中獲得什麼 —— 我們想知道狀態變換的時間點。當狀態變換時,原本的狀態數值不會繼續增加,而是另一個狀態的數值會增加。觀察 gatus_results_total 這個指標後可以明確看出數值停住不動的樣態。所以從這個角度去思考,在整組數據中重複的數字都是無用的數據點,只有瞬間 +1 的那個時間點才是我們要關注的。因此,我們可以把數值與 success 欄位視為一組,通過 Group By 移除重複的數據,並保留每個 Group 中的第一個時間點。
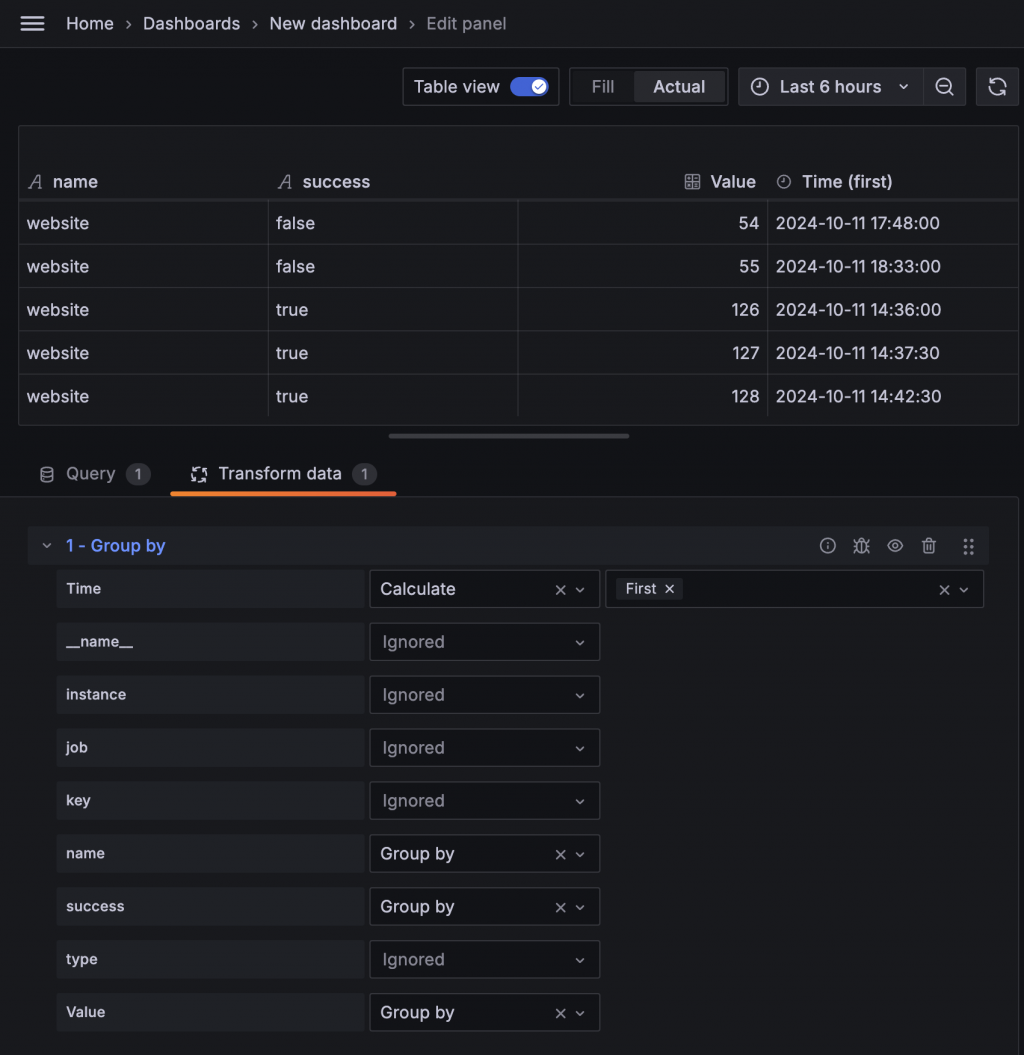
Group 之後,數據看起來已經大致符合我們的需求。接著,我們可以做一些排序、篩選欄位以及設定 Panel,讓 State Timeline 可以正常顯示。
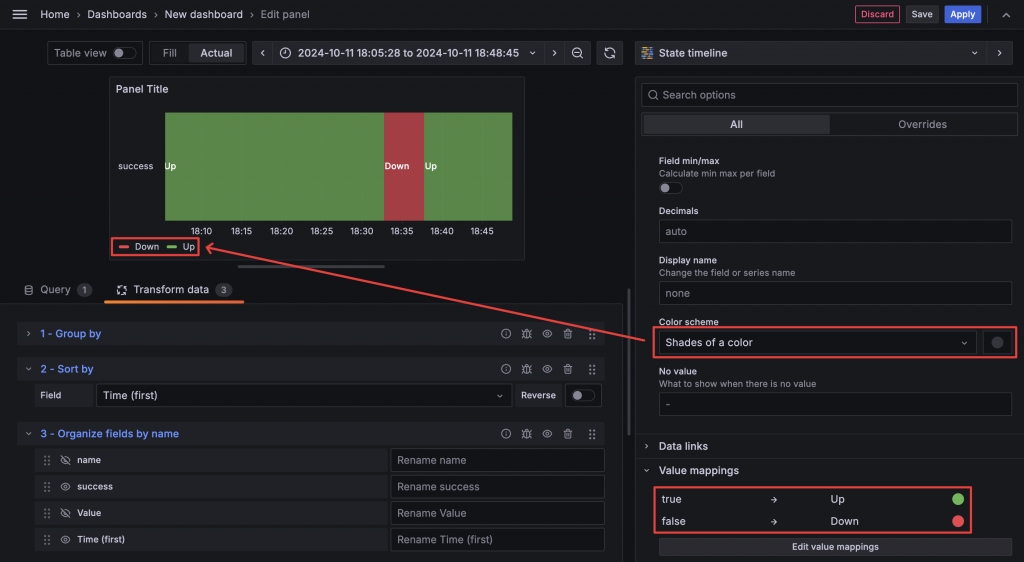
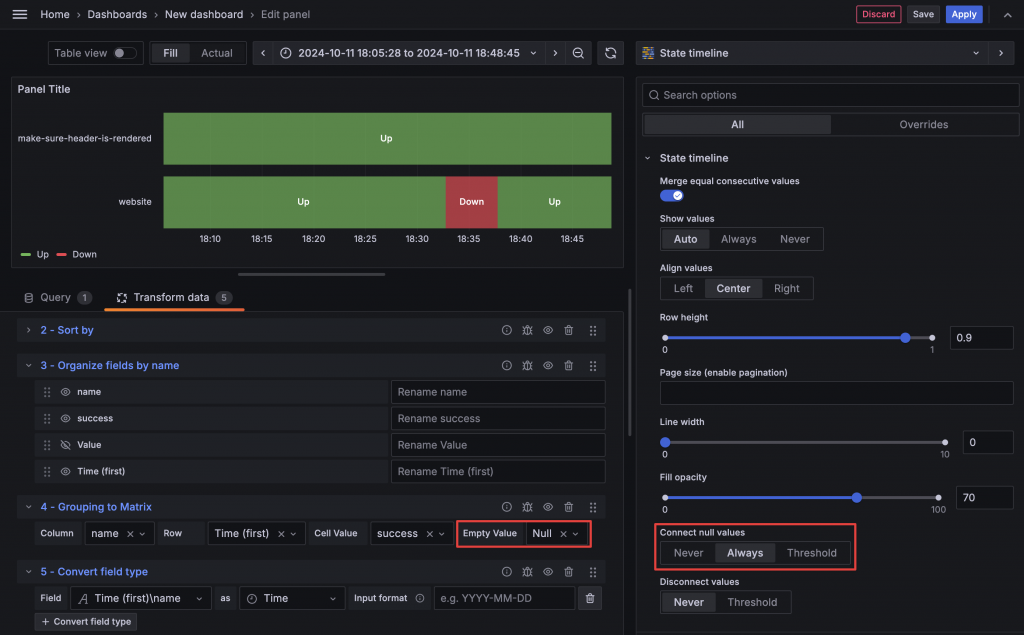
不過這裡可以看到 State Timeline 前面的名字是 success,理論上應該呈現服務的名稱比較合理。此外,設定也只能顯示一條數據。這是因為 State Timeline 使用 Column 作為該筆資料的名稱。如果要顯示多組數據,則需要額外的 Column。
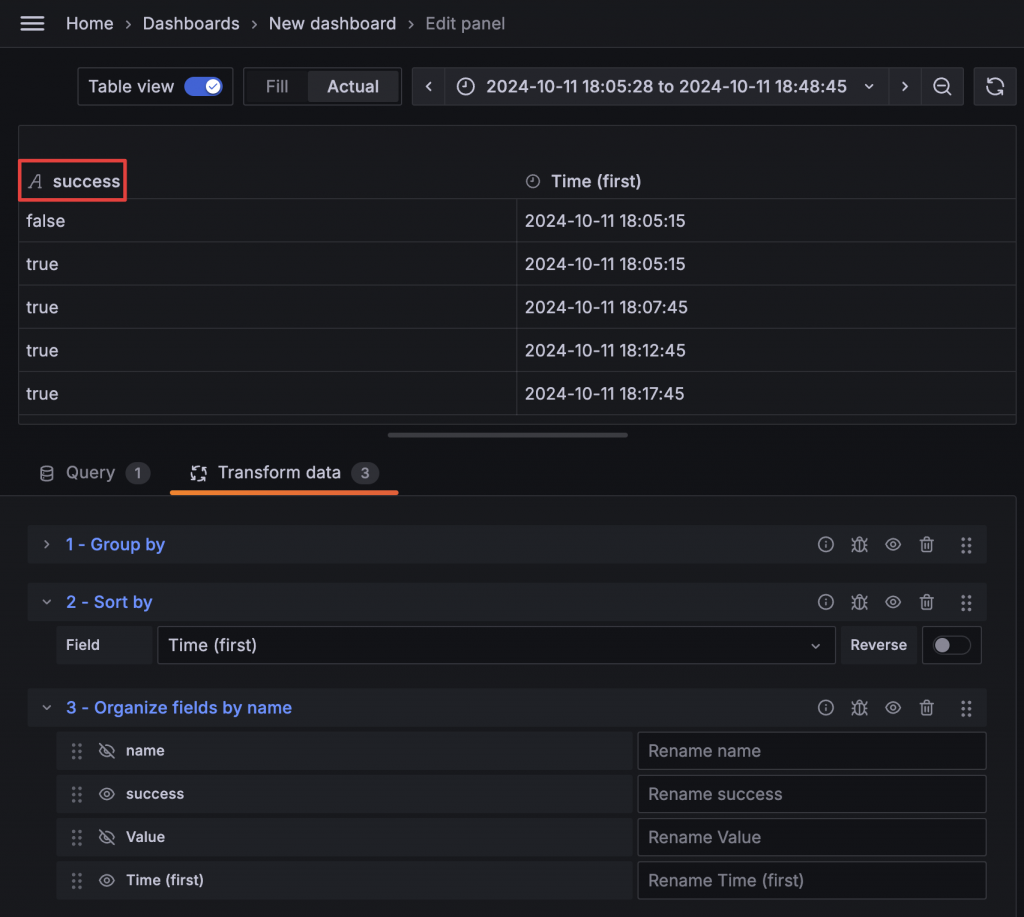
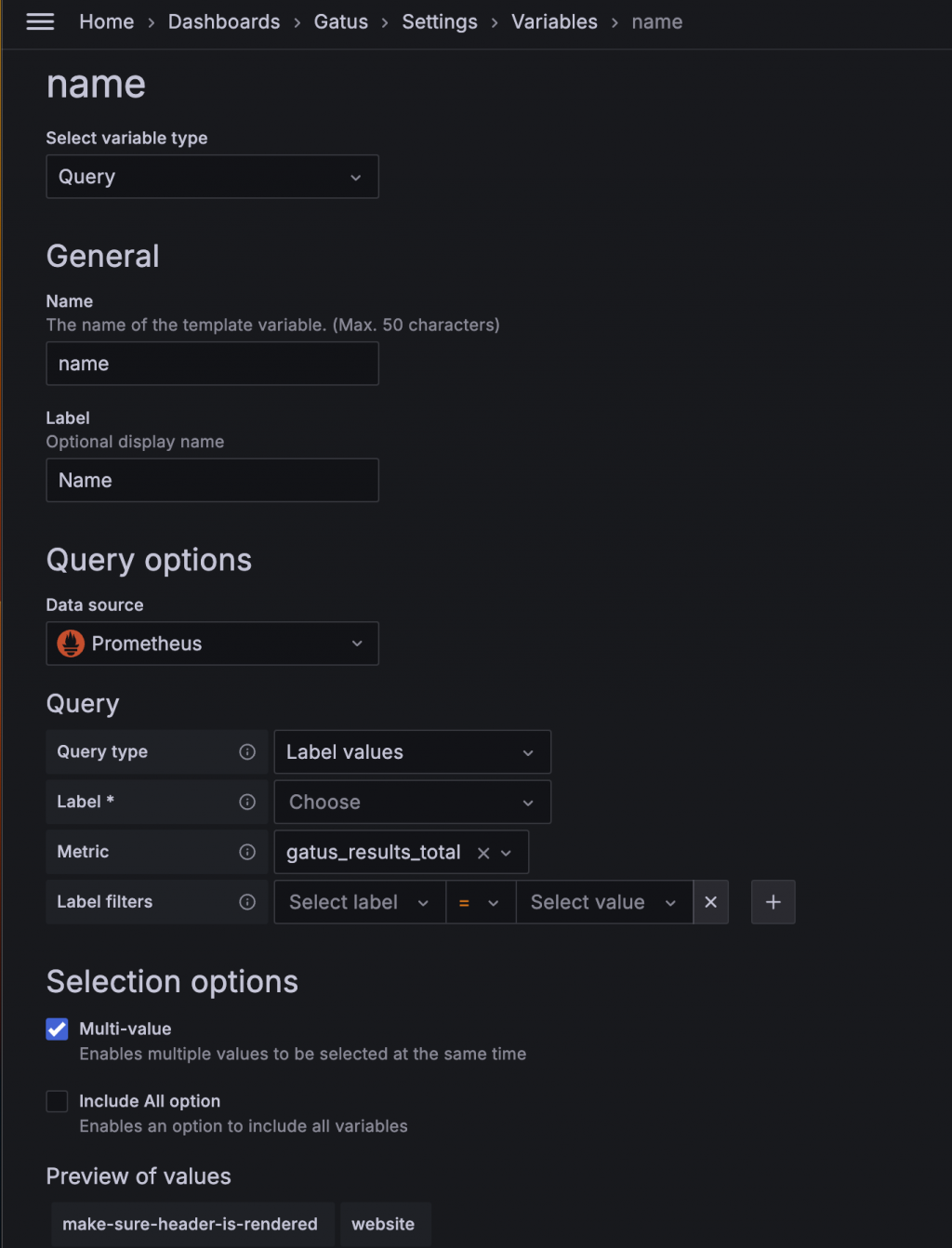
所以我們的新目標是將 Column 名稱改為 name 欄位的值。這時可以使用 Group to Matrix 來達到 Pivot 的效果。選擇 name 作為 Column,Time 作為 Row,Value 則繼續選擇 success。
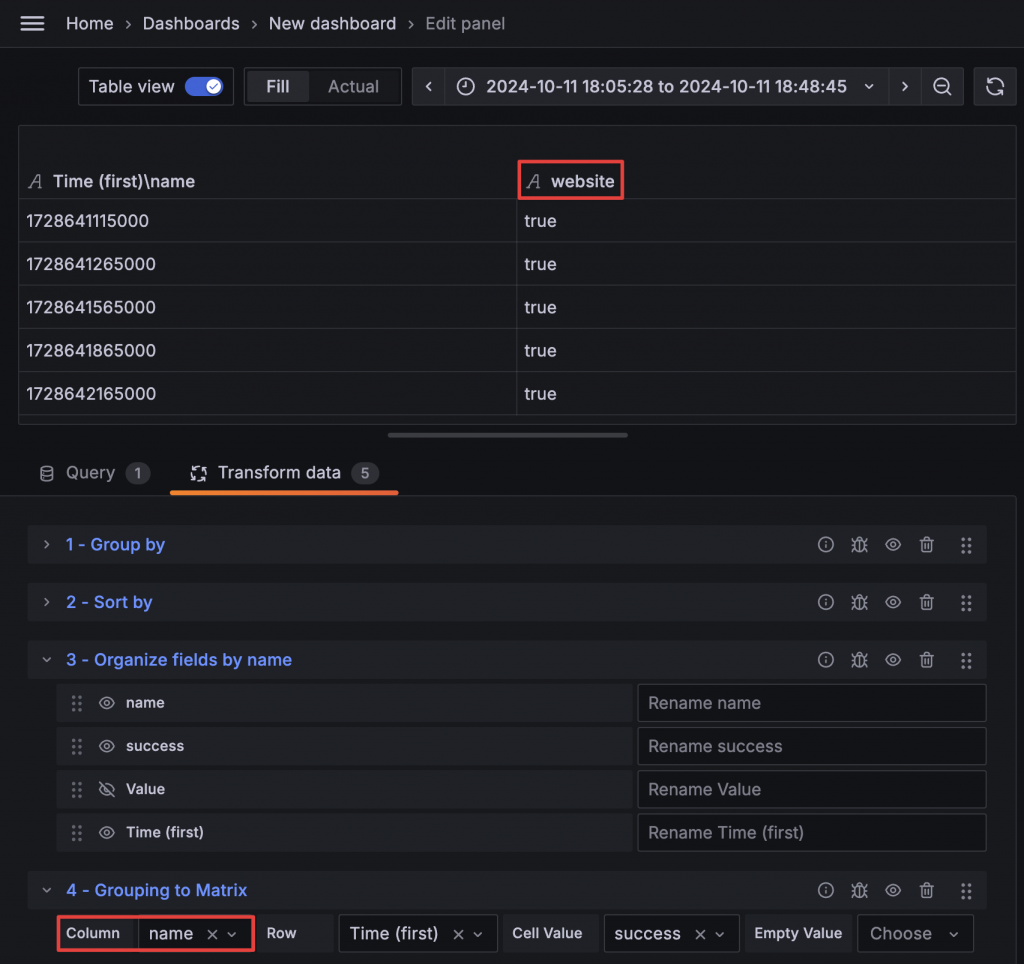
再次切回 State Timeline 後,卻遇到了我們的老朋友 Data does not have a time field。切回 Table 檢視後發現,Time 欄位居然沒有自動轉換成時間欄位。因此我們補上 Convert field type,將 Time 欄位轉換成時間格式後,就能正常顯示。此時,State Timeline 前面的名字也如願變成了 name。
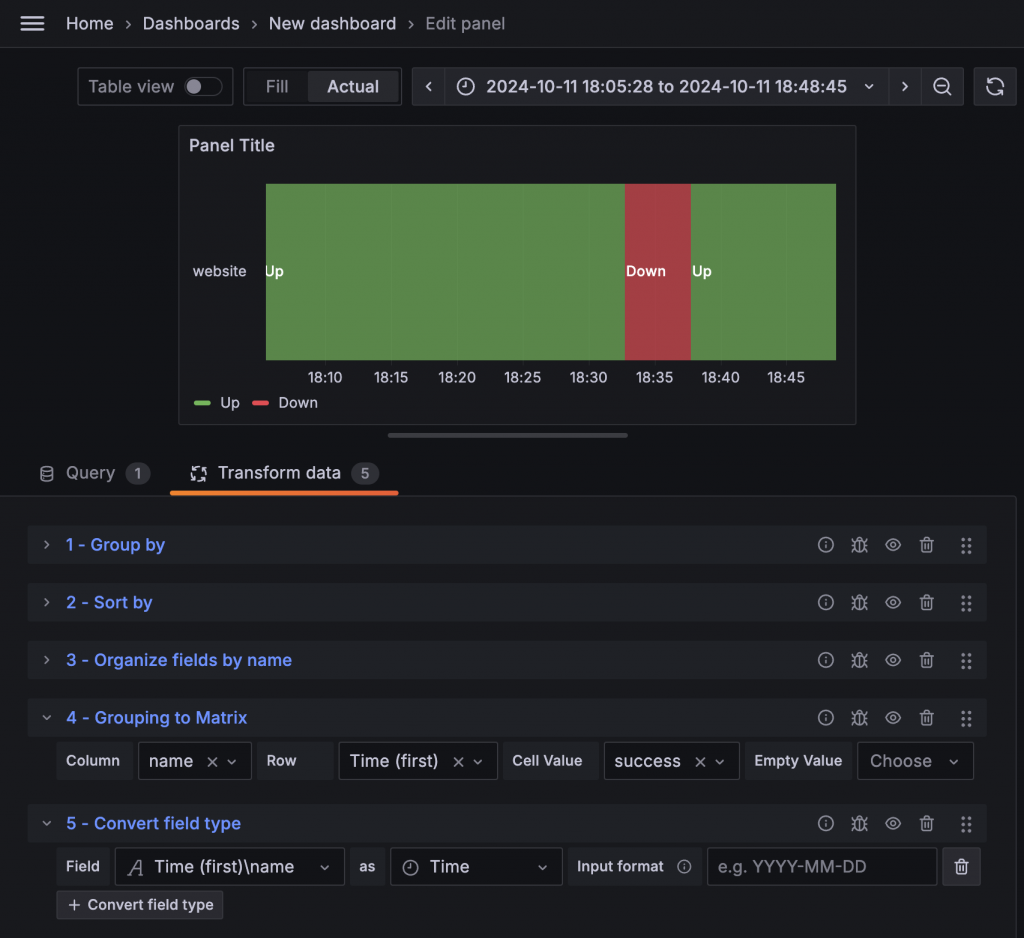
接下來,我們應該可以正常顯示多組數據了吧?調整 Query 後發現,怎麼突然出現了許多灰色的洞!
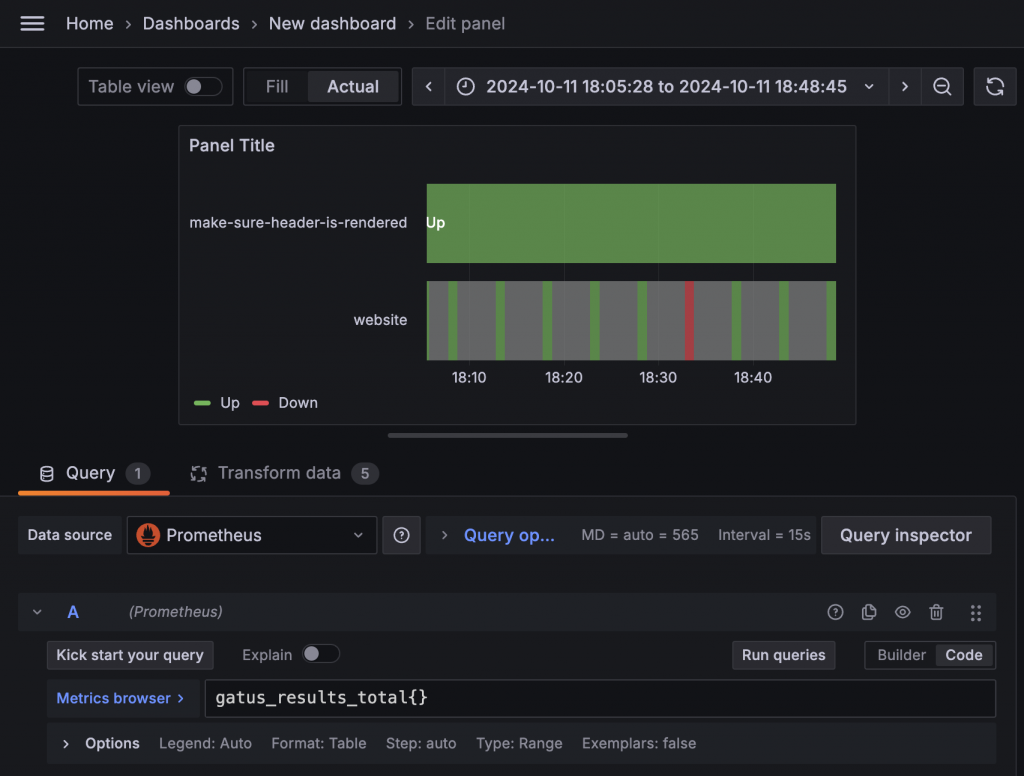
只好再度切回 Table,發現因為兩個服務的檢查週期不同,導致數值 +1 的頻率不一致。幸好,State Timeline 支援 Connect null values 的功能。只需要在 Group to Matrix 中將 Empty 的值設為 Null,就可以讓空白部分與前一個狀態相連。到這裡,我們終於成功盜竊了 Gatus 的 Health Status 視覺化。
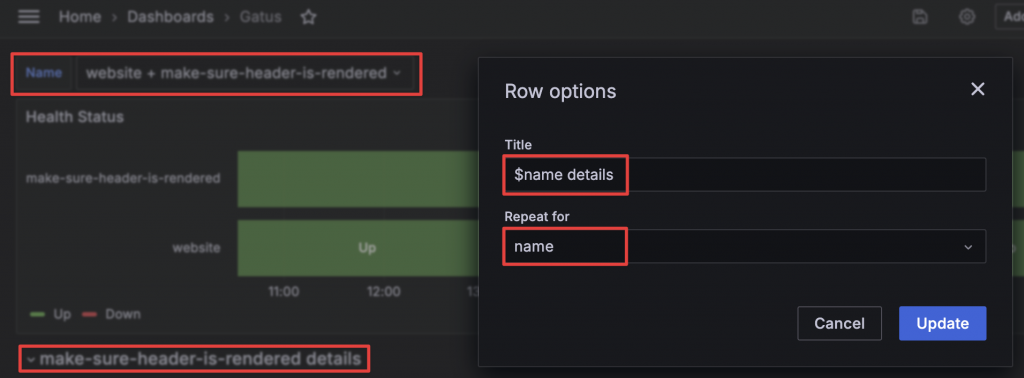
Gatus 除了基礎的 Health Status 外,也提供每個服務的細節資訊,包含過去 7 天、24 小時、1 小時的 Up Time 和 Response Time。初步構想是透過 name 變數和 Row Repeat 功能,讓每個服務有自己的一列細節資訊,接著繼續進行我們的「盜竊」。
Up Time 的計算其實就是前面 Health Status 在指定時間段內的 Up 比率。所以我們可以複製前面的 Health Status,繼續往下計算,並選擇 Status 顯示單一數字即可。排除掉一些後續的特殊處理,目前只需要處理單一服務的資料,該資料只包含 true 和 false,接下來只要統計 true 的數量除以總數即可。
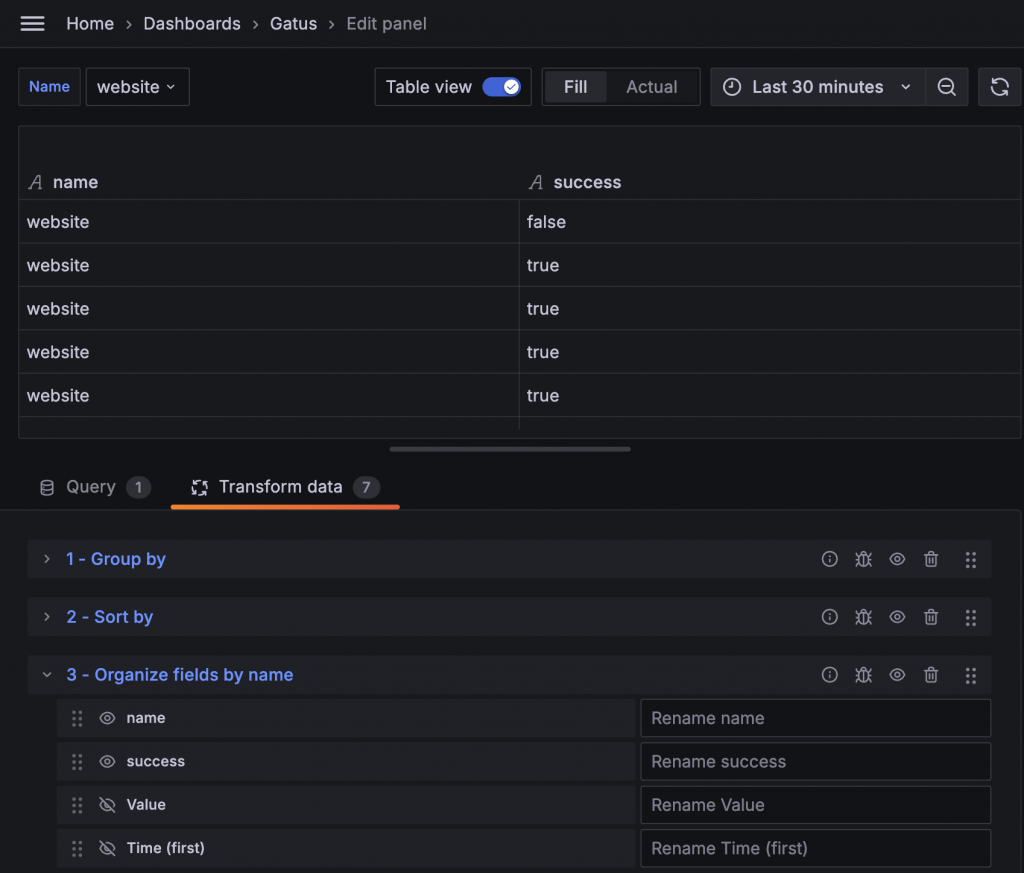
再次使用 Group By,但這次將計算方式選擇為 Count,就可以算出 true 和 false 的數量。
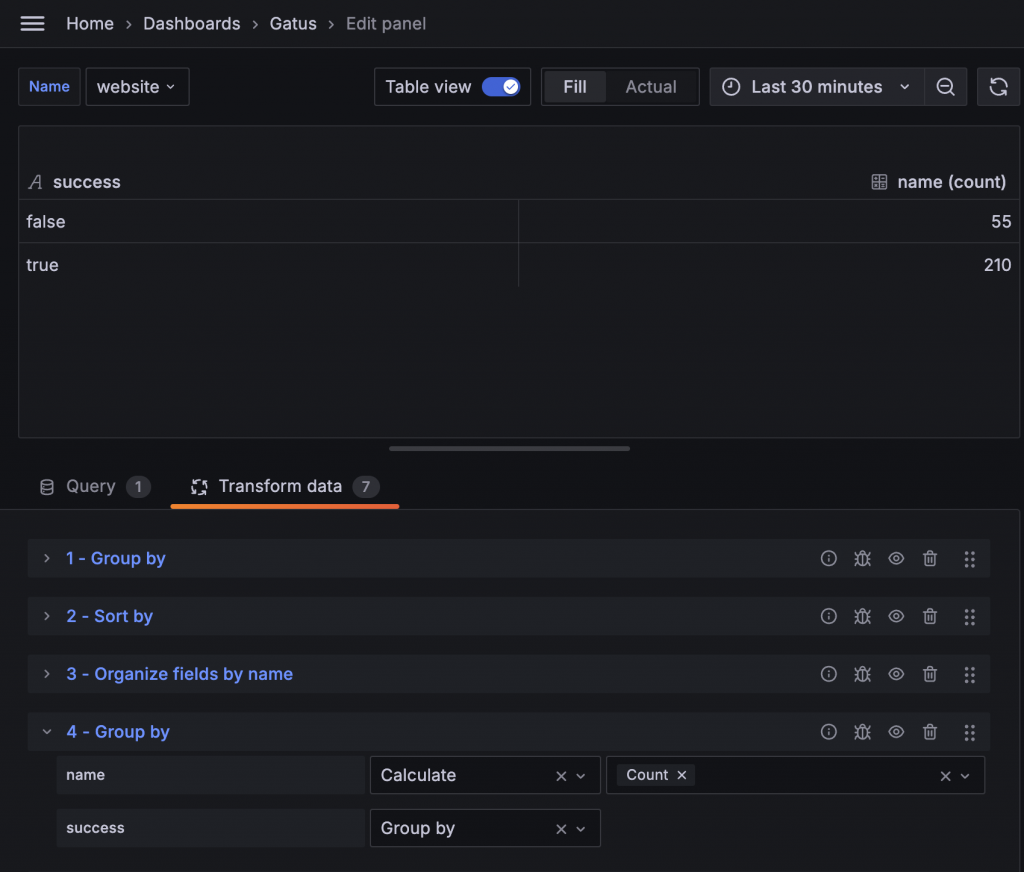
利用 Rows to fields 可以將兩列數據轉換成兩個欄位,再搭配 Add field from calculation 計算總和。
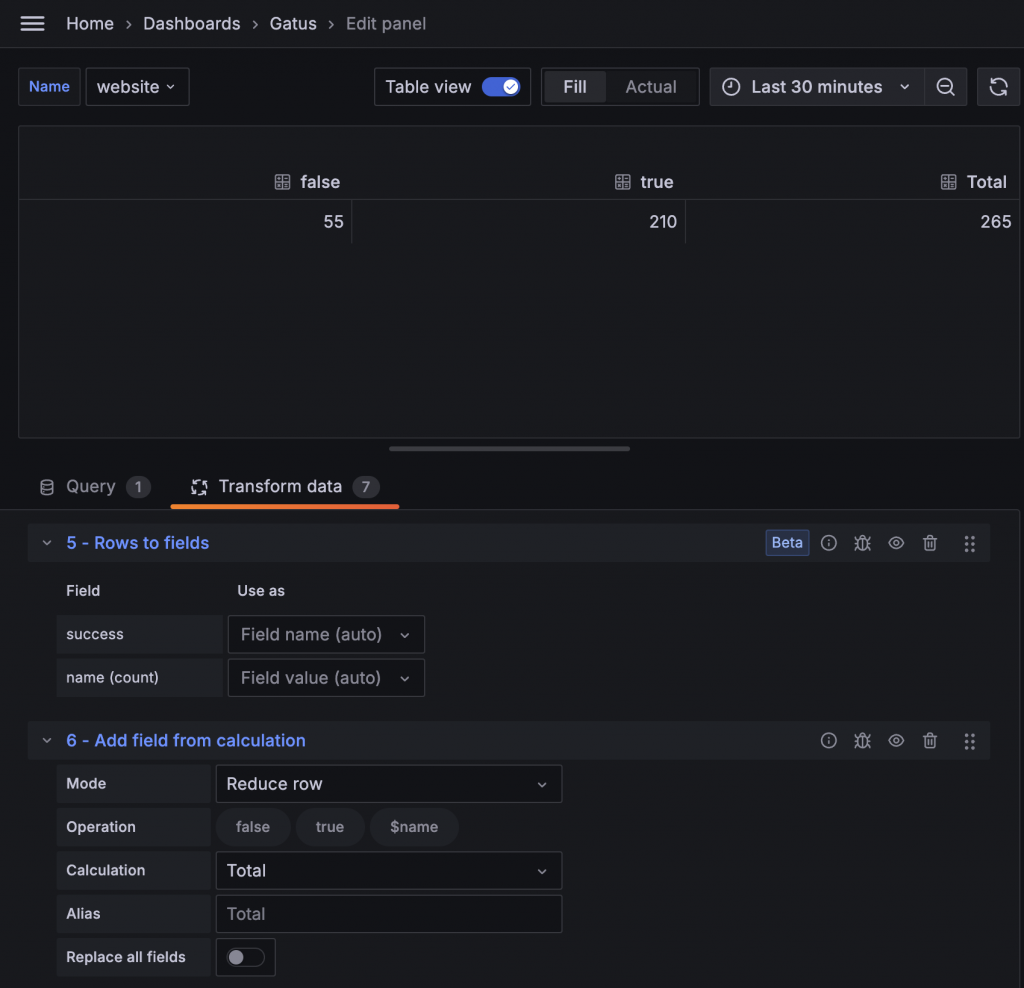
最後再用一次 Add field from calculation 把 true 的數量除以總和,並選擇 Replace all fields,這樣就只會保留最後算出的 Up 比率。
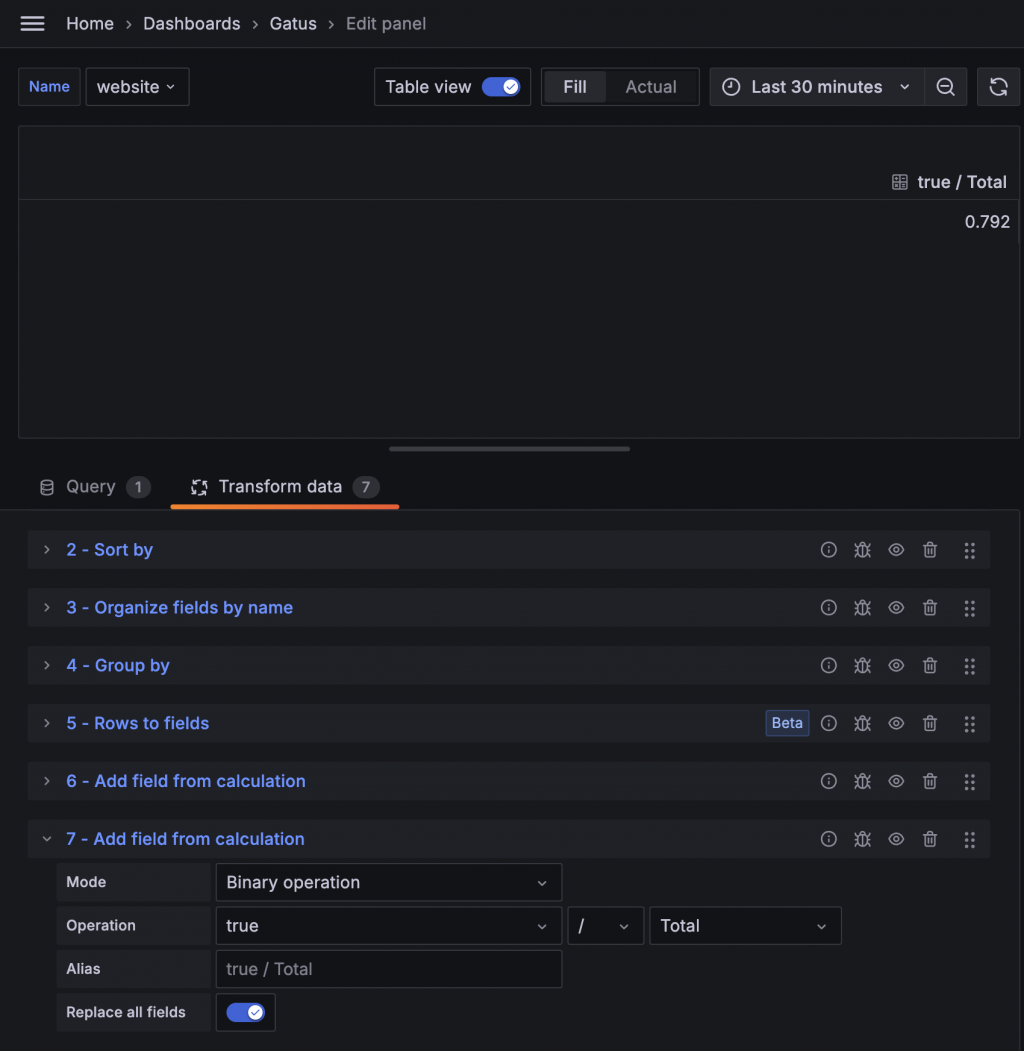
查詢 Prometheus Metrics 時,預設會使用 Dashboard 的時間範圍。但我們這裡需要的是 7 天、24 小時、1 小時的時間範圍,因此可以透過修改 Query options 的 Relative time,直接將範圍改為 Dashboard 結束時間點往前算的時間。
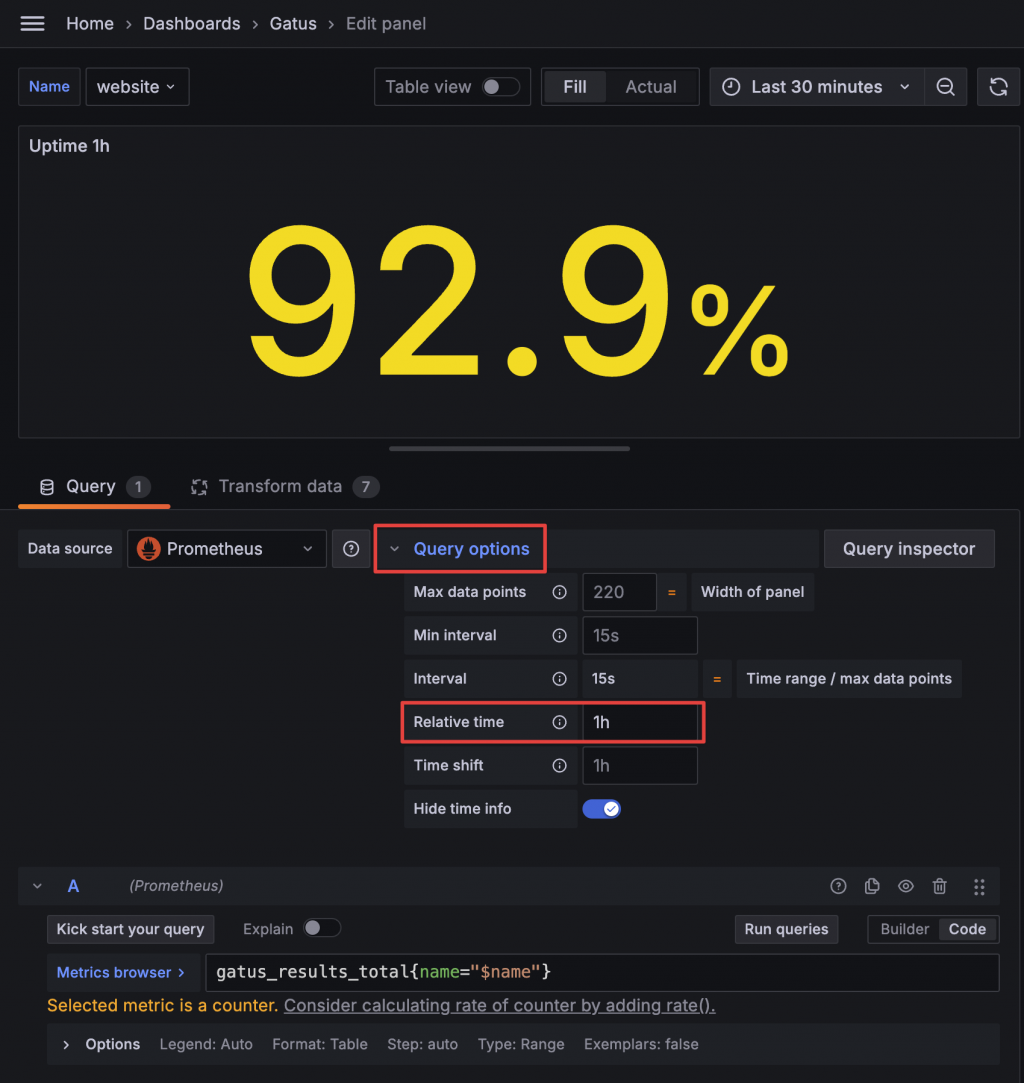
透過這樣的設定,我們就能夠做出 7 天、24 小時、1 小時三個 Panel。

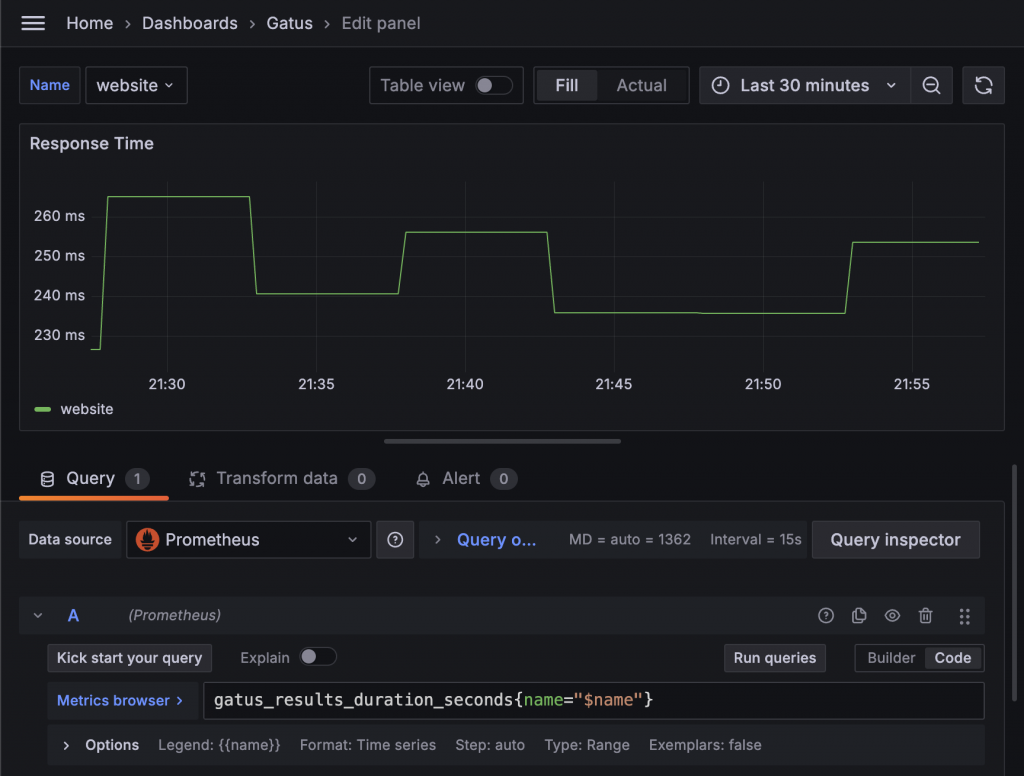
參照前面的探索方式以及和 Gatus Status Page 對照,我們可以發現 gatus_results_duration_seconds 指標就是 Response Time 的時間。最簡單的 Response Time 可以使用折線圖,選擇 Time Series 就能顯示。
平均 Response Time 可以直接使用 PromQL 的 avg_over_time,它可以某段時間內所有數值的平均值,時間範圍的指定方式是使用 [] 設定,以查詢 7 天內 Response Time 的平均值為例,PromQL 就會寫成:avg_over_time(gatus_results_duration_seconds{name="$name"}[7d])。另外這我們也選用 Instant Type,只查詢 Dashboard 結束時間點起算的數值。
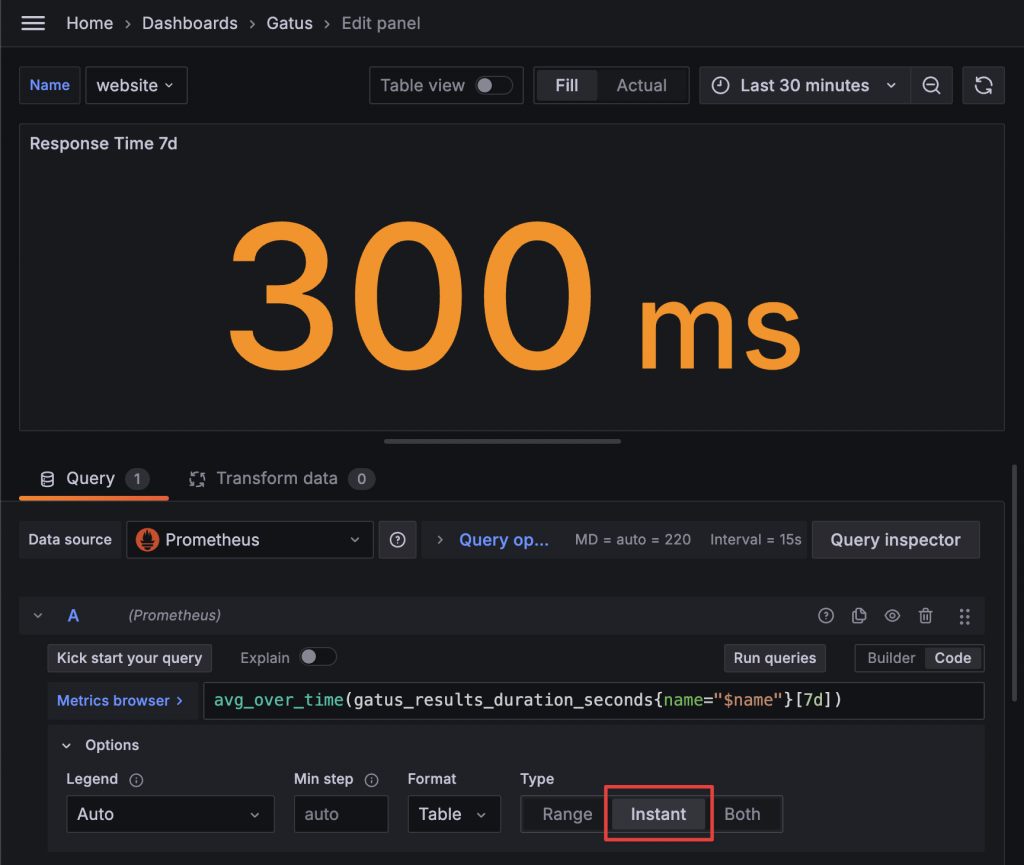
透過類似的設定,改變 [] 內的值,我們就能夠做出 7 天、24 小時、1 小時三個 Panel。

經過一系列操作後,我們的竊盜出來的完美作品如下:
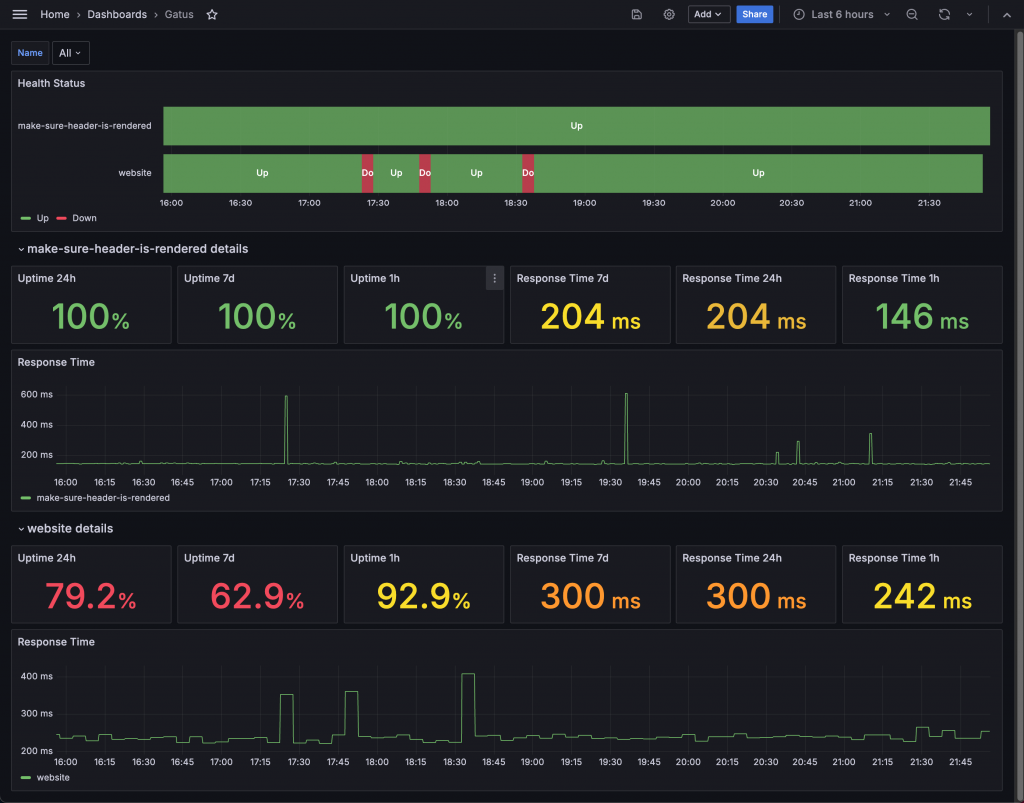
範例程式碼:https://github.com/blueswen/grafana-zero-to-hero/tree/main/use-case/gatus
此 Lab 會建立
啟動所有服務
docker-compose up -d
檢視服務
admin/admin
關閉所有服務
docker-compose down
雖然這樣在 Grafana 上重新造輪子好像很多餘,明明可以直接使用現有工具,Gatus 也還支援完整的告警功能。但 Grafana 的優勢在於能夠將各種資訊集中顯示在同一個平台上,當需要跨資料源進行比較時,可以更快讓我們專注於解決問題,而不是花大量時間在不同工具間切換,以及人肉 Join 和 Group 資料。透過這樣的練習,我們也能更加熟悉 Grafana 的各種 Panel 與 Query Transform 功能,這些技巧有時候真的是江湖一點訣,講破不值錢,但實際操作後會發現,原來真的可以這樣做。

