
「資料變化要能即時反映出來,並透過事件的形式進行串接。」基於這樣的概念,我們需要在異動資料抵達系統時,在毫秒或秒級就處理完成。今天就逐步拆解概念,一一掌握技術名詞吧。
事件是指系統中發生的任何可觀察的行為或狀態變化。當事件發生時,通常會伴隨一些與之相關的資料產生。例如,在應用程式中使用者採取的行動,檢視頁面或訂單狀態更新都可以視為事件。事件也可能源自於伺服器 (server) 的日誌 (log)。
事件是不可變的 (immutable),表示它只描述某個時間點發生的某件事情的細節。而日誌會把所有系統上的歷程全部記下來,只增不減 (append only)。
若我們把事件視做一種帶有資料的訊息 (message),那麼訊息佇列 (message queue) 是一種用來在不同系統或應用程式之間傳遞訊息的架構。它核心概念是:訊息產製者 (producer) 將訊息放入佇列,而訊息消費者 (consumer) 會從佇列中提取訊息進行處理。這是一種**非同步 (Asynchronous) **的通訊模式,產製者不需要等待消費者完成處理,也不像輪詢 (Polling) 一樣,輪詢地越頻繁,能返回新事件比例就越低,而額外開銷也就越高。
同步 (Synchronous) 就像打 API 一樣,發出請求 (request) 之後必須等到回應 (response) ,中間若有連線中斷,資料就會遺失。
訊息佇列系統具有以下特性:
市面上有許多工具搭建訊息佇列系統,包含開源工具 (RabbitMQ、Redis、Kafka) 或雲端服務 (GCP Cloud Pub/Sub、AWS Amazon SQS) 可以搭建訊息佇列系統。
如果以 Day 03 提到的網購服務新創團隊為例,資料流複雜性與資料量級對一般的 message queue 可能會超出負擔。而 Kafka 透過使用 zero-copy 方法,直接將 bytes 從檔案系統傳輸到網路緩衝區 (network buffer),繞過應用程式緩衝區 (application buffer),是吞吐量 (throughput) 可以明顯地提升的原因。
Kafka 採用分散式架構方便水平擴張,且將資料存放於硬碟空間,可以長時間保存資料,這些特性針對巨量資料串流處理 (big data streaming processing) 處理非常實用。
接下來,我們要把這些概念轉成元件,拼湊出一條即時資料處理管線。
首先,在 Kafka Connect 中啟動一個 Debezium (開源的 CDC 平台)。這個 Debezium 負責監聽來自資料源的變更日誌,轉譯成 INSERT, UPDATE, DELETE 等 Kafka 事件後,最後由 Kafka Connect 將這些事件資料即時地傳送到 Kafka。
{
"schema": {
"type": "struct",
"fields": [ ... ]
},
"payload": {
"before": null,
"after": {
"id": 1001,
"first_name": "John",
"last_name": "Doe"
},
"source": {
"version": "1.6.0.Final",
"connector": "mysql",
"name": "my-app-db",
"ts_ms": 1623863456000
},
"op": "c",
"ts_ms": 1623863457000
}
}
before:變更前的資料。如果是 DELETE 操作,這裡會顯示被刪除的資料;如果是 INSERT,則為 null。after:變更後的資料。如果是 UPDATE 或 INSERT,這裡會顯示新資料。op:操作類型,c 代表 create,u 代表 update,d 代表 delete。因此,Debezium 提供的 CDC 服務就是一種來源連接器 (Source Connectors),類似訊息產製者的角色,負責把變更事件發送到訊息佇列 Kakfa。對應的目標連接器 (Sink Connector) 則作為訊息消費者的角色,把資料從 Kakfa 取走,送往後續的目的地,例如備份資料庫、應用程式資料湖、資料倉儲等。
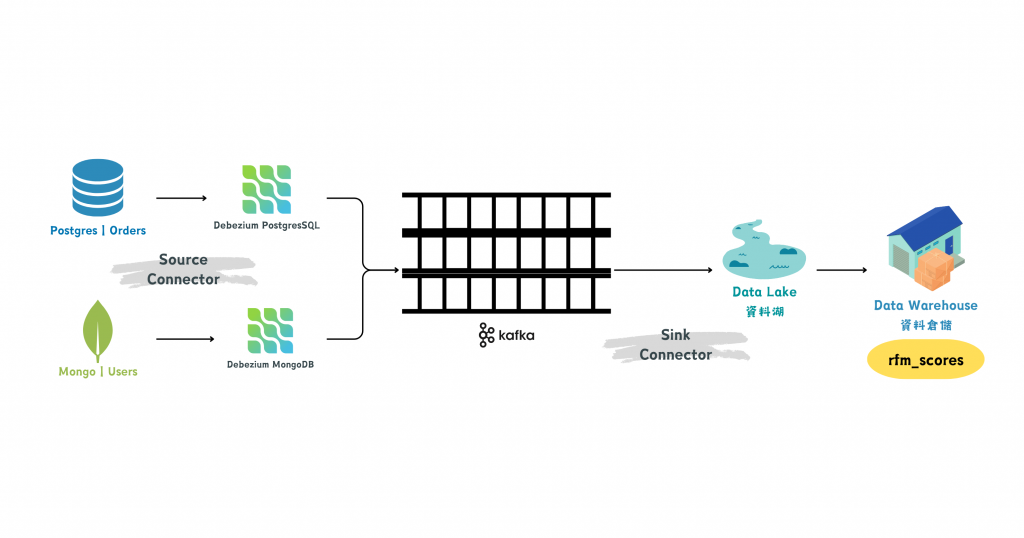
圖/RFM 分析的上游透過 Debezium + Kafka 實現資料源變化即時捕捉管線。簡書廷製。

