昨天我們透過 Debezium + Kafka Connect 的搭配,我們把分別來自 Postgres 和 Mongo 的訂單 orders 和 顧客 users 每一次的資料變更都捕捉到訊息佇列 Kafka 了。但在此之後,離 RFM 分析即時報表,還有一段即時運算的距離未完成。
拿到即時資料後,我們可以從各種 Stream Processing 的框架中比較特性,挑選適合的工具:
看起來無懸念,延續我們先前使用 SQL 做資料轉換及利用 Python 撰寫 Airflow 做任務編排的技能樹,我們就選用 Flink 來做即時運算引擎啦!
Flink 透過分散式框架,面對巨量資料仍然能維持高效率處理,包含高吞吐量 (throughput) 低延遲 (latency)。同時,它將Batch Processing 視為一種特化的 Streaming Processing,可理解成批量處理就是時間區間無限小的串流處理,因此可以透過同樣的運算機制 DataStream API 處理,達成所謂的批流合一。
即使產製者 (producer) 重新嘗試發送訊息,也只會讓訊息傳送給消費者 (consumer) 一次。Flink 的這個特性非常重要,因為在我們的分析情境裡,沒辦法接受有些訂單變更可能被遺漏處理。也沒辦法接受重複收到訂單帶來的溢算後果。
狀態 (state) 表示執行單位 (operator) 在處理當下事件的時候,保持對先前事件的記憶。
有狀態操作 (stateful operation) 的一些範例:
這些記憶是透過保存點 (checkpoint) 技術實現,它定期保存上述提到的狀態和資料進展。這樣當系統不幸故障時,可以從最近的保存點恢復,避免重新處理整個資料流。
狀態記憶會儲存到永久性的訊息佇列或檔案系統 (例如 HDFS、S3 等),當系統故障或重啟時,從可以從這些 checkpoint 繼續處理未完成的資料流,確保資料計算的一致性和準確性。
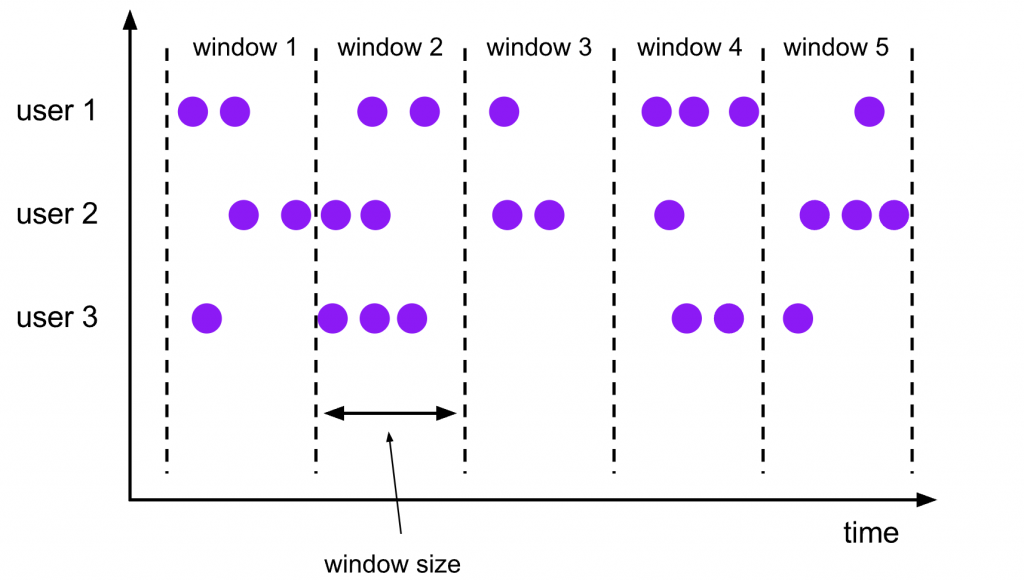
Source: https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/operators/windows/#window-lifecycle
像上圖的資料,視窗 (window) 是處理持續流入且沒有界線的資料流的核心概念。 Windows 將這種連續資料流分割成有限大小的桶子 (bucket) 後,就可以一一進行運算。
讓我們回顧一下 RFM 分析的三個指標,其實都和 orders 有關,在批量計算時的 SQL 如下:
SELECT
user_id,
MAX(ordered_at) AS last_order_date,
COUNT(order_id) AS order_count,
SUM(order_amount) AS total_spent_amount
FROM
`orders`
WHERE
{time_filter: from start to now}
GROUP BY
user_id
;
應用 Flink 在做 COUNT 和 SUM 的聚合時,只要善用前一次狀態,把新進來的訂單金額和數量疊加上去就可以獲得正確的數量。但對於 MAX 的計算而言,則會需要找出整個資料流中的最大值。在持續運行時,必須保存每個分組的目前最大值。隨著資料規模增長,保存這些狀態的記憶體需求也會增加。
狀態的保存時間 (time-to-live, TTL) 可以根據商業應用情境調控,以避免狀態記憶量過大。例如:超過一定時間以前的訂單就不納入考慮。
以上特性讓 Flink 在處理即時資料流時,能在巨量資料湧入下仍具備一定的低延遲水準。同時透過視窗切割以及狀態保存點,確保計算結果的準確性以及故障復原的可靠性。

