
我們從 Day 08 知道若從資料源的 OLTP 擷取資料變化送往資料倉儲這個 OLAP 系統進行加值運用,可能有全量、增量、SCD 等方式。再藉由 Day 17 的說明,我們開始有了串流處理的概念。兩個概念整合起來,就是資料變化要能即時反映出來,並透過事件的形式進行串接。
OLTP 系統的資料變化偵測有以下幾種方法:
例如用 updated_at 來表示資料的變更,讓下游可以透過這個欄位來獲取變化資料。但這方法需要應用開發者在應用程式內維護這個邏輯,且一旦資料源的資料被刪除,也沒有 updated_at 可以偵測了。
資料庫可以設定在指定事件如 INSERT、UPDATE 或 DELETE 發生時,將資料變更記錄到一個日誌表 (log table),這方法可以捕捉資料刪除的這個變化,也不需要應用開發者的配合。但它會造成資料事務 (transaction) 需要等待紀錄完成才能送出 (commit);同時需要維護一張表,當資料源發生大量變化時,這會成為很大的寫入負擔。
這個資料事務日誌是資料庫用來備份 (backup) 資料或做為異常時的援備 (recovery) 手段,亦或用於分散式 (distributed) 資料庫的主從節點資料同步。當然,寫入日誌比另外寫入一張表來的有效率多了!
Day 13 就有提到在資料倉儲裡,我們至少要有一份資料是完整記載任何收集進來的變動,不能覆蓋任何的歷史,這樣才保有日後需要進行資料回溯時的可重現性。看來有解了,我們只要能完整且即時地串接這份 log,就同時擁有了即時性與可重現性兩大優勢,而且還不太會影響 OLTP 的運作!
為了追求效率,日誌本質上都是二進位或壓縮格式,因此直接原始資料並非人類直接可讀。不過每個資料庫系統都有工具可以將這些日誌轉換成可讀格式。我們就以幾個常見的關聯式資料庫 MySQL、PostgreSQL,和非關聯式資料庫 MongoDB 來說明吧!
MySQL 的二進位日誌 binlog記錄了所有影響資料的修改操作。透過 mysqlbinlog 工具可以將這些日誌轉換為可讀格式。而在參數配置上,可分為
可想而知,ROW 的記錄方法在大量更新資料時會造成大量日誌內容。
#230924 12:01:25 server id 1 Query BEGIN
#230924 12:01:25 server id 1 Table_map: `test`.`users`
#230924 12:01:25 server id 1 Update_rows: table `test`.`users`
### UPDATE `test`.`users`
### WHERE @1=1 /* id */
### @2='John' /* first_name */
### SET @2='Jonathan' /* first_name */
#230924 12:01:25 server id 1 COMMIT
這個 binlog 紀錄了一個 UPDATE 操作,修改 id = 1 的 user 的 first_name。
參考:MySQL Binary Logging Formats
預寫日誌記錄 (Write-Ahead Logging, WAL) 是確保資料完整性的標準方法。簡言之如果 WAL 記載變更之後到永久儲存,即便資料的更新未完成,我們還是能夠使用日誌來恢復資料庫。可以使用 pg_waldump 工具來讀取這些日誌。
rmgr: Heap len (rec/tot): 44/ 44, tx: 605, lsn: 0/1602C80, prev 0/1602C48, desc: INSERT off 3
BLOCK 0 OFFSET 3 TUPLE DATA: 0003 006a 6f6e 6168 616e
rmgr: Transaction len (rec/tot): 32/ 32, tx: 605, lsn: 0/1602CB0, prev 0/1602C80, desc: COMMIT 2023-09-24 12:01:25.123 UTC
這段 WAL 記錄了一個事務,其中有一個 INSERT 操作。資料插入在某個表格的第 3 行 (off 3);插入的資料是二進位編碼 (006a 6f6e 6168 616e 代表 Jonathan )。該事務隨後在 2023-09-24 12:01:25 時間點被提交。
參考:PostgreSQL Write-Ahead Logging(WAL)
Mongo 的操作日誌 operations log,存放在 oplog.rs 這個集合 (collection) 裡面,可以透過 mongo 的查詢語法來查看日誌資料。
{
"ts" : Timestamp(1692957685, 1),
"h" : NumberLong("1234567890123456789"),
"v" : 2,
"op" : "u",
"ns" : "test.users",
"o2" : { "_id" : 1 },
"o" : { "$set" : { "first_name" : "Jonathan" } }
}
這個 oplog 記錄了 test.users 表中的一個 UPDATE 操作,將 id 為 1 的 firstname 改為 Jonathan。op: "u" 表示這是一個 UPDATE 操作。
不過 oplog 是為了讓分散式儲存系統的 Replica Sets 之間資料達到最終一致性而生的日誌。還可以透過 MongoDB 提供的高階 API db.collection.watch() 進行資料變更監控,也是一種方便的選擇。
參考:MongoDB Replica Set Oplog、MongoDB db.collection.watch()
這些被捕捉到的變更或 CDC 日誌,都是從資料源所產生的衍生資料 (derived data),Day 05 提過的資料湖、資料倉儲、資料湖倉都是由衍生資料所搭建的系統,可統稱衍生資料系統。衍生資料系統的強大就在於它介接了各種不同的資料來源,成為一個彙集完整資訊的資料中心。
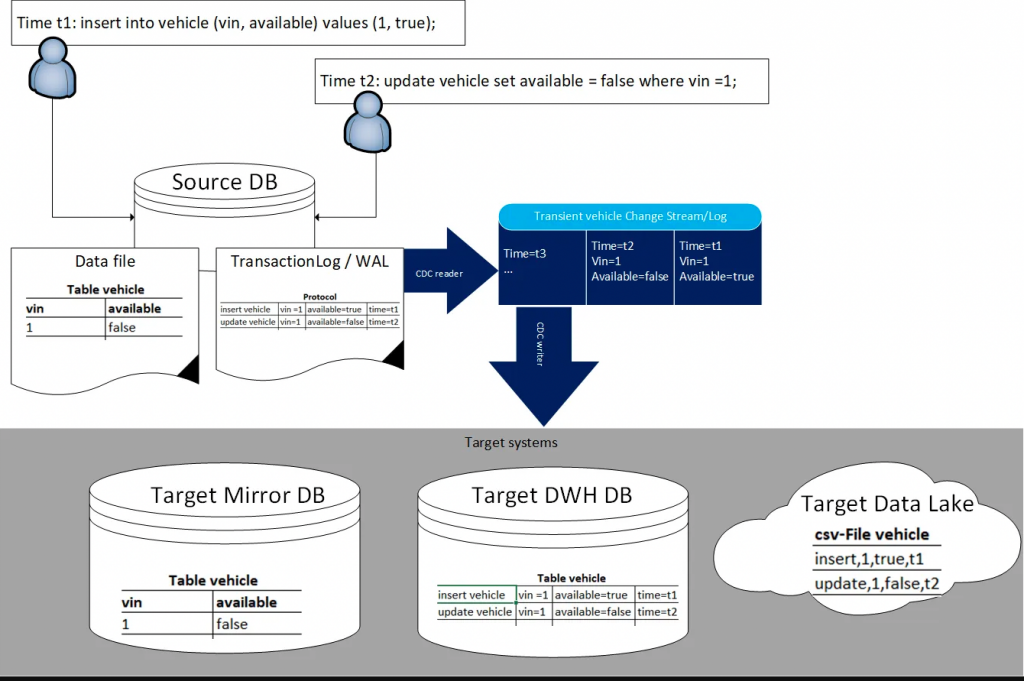
Source: https://medium.com/mercedes-benz-techinnovation-blog/change-data-capture-lessons-learnt-7976391cf78d
從上方這張圖 Mirrow DB 可以看見,這些變更日誌,本質上還是為了資料源本身的備份、故障援備機制而生。擁有日誌對於資料庫的重建是關鍵的存在。而對於資料倉儲或資料湖而言,衍生資料的取得只是分別以結構化或非結構化的方式存入系統,重點則是後續的加值運用。
今天就談到這。回顧第一段談的「資料變化要能即時反映出來,並透過事件的形式進行串接。」今天只提到資料變化而已,即時/事件/串接的操作技術留待明日分曉。

