在開始這章之前,想先說說在學習程式語言時,有些規則、方法像是武功的基礎,必須得用身體(頭腦)記憶才能在關鍵時候發招,而有些知識則像是解題推薦招式,我們若是每次看到類似的題型,下意識地能用出公式,便可以省去很多慢慢計算的時間,然而這不代表只有這個方法才能解出答案,只是比較快而已(快很多)。
正規表達式的存在,可以省去我們很多查找與歸納文字規則的時間,我們不用強求自己一定要記住正規表達式的語法,只要提醒自己,在遇到特定的問題時,可以使用正規表達式即可。
說到這裡可能還沒什麼感覺,所以讓我們開始介紹正規表達式吧!
正規表達式 Regular Expression(簡稱為 RegEx)是一種「特殊的字串,用來在資料中尋找特定模式(規例)」。我們可以使用正規表達式來檢查某種模式是否存在於不同的資料類型中。
上面這樣描述,可能還是讓人摸不著頭緒,所以我們用實例來說明,大家可以試想看看:「如果想確認使用者填入的資料,是否為 email 時,我們可以怎麼確認?」
根據日常常見的 email 地址,像是 ithome@gamil.com 或是 student@nccu.edu.tw,我們可以大致推論 email 地址可以拆解為「字串(使用者帳號)」+「@ (小老鼠)」+「字串(網域)」, 所以如果我們要驗證使用者輸入的資訊是否符合 email 規範時,我們可以用下列規則做確認:
@ 在其中?@ 前面是否有字串?@ 後面是否有網域字串?當然,上面第二點與第三點還可以再進行更詳盡全面的規則設定,但我們就以這三點為主(下圖是常見的 email 格式語法)。
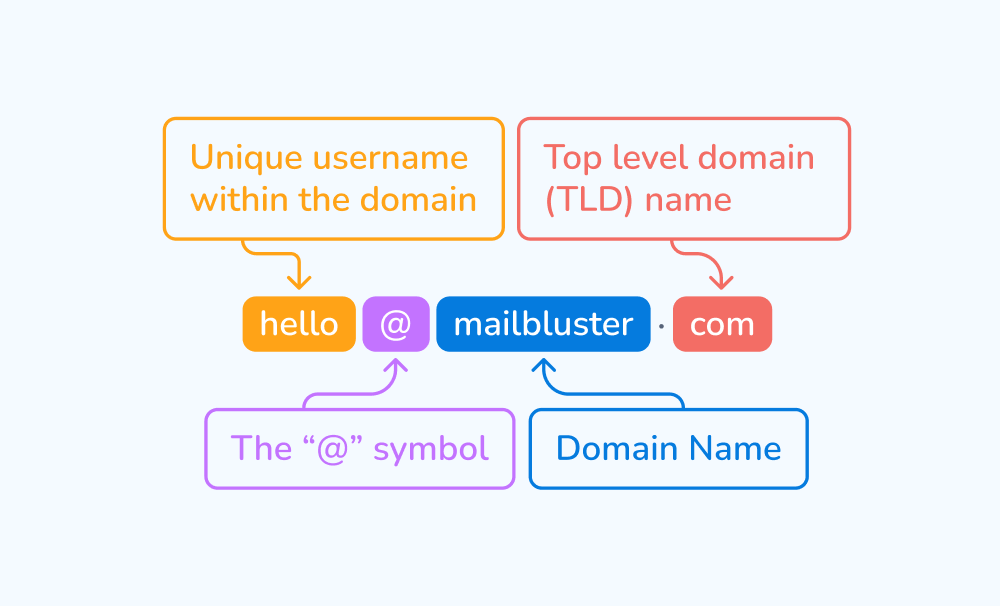
但我們不可能用文字說明規則,因此我們可以使用 RegEx 來表達這些文字規則,進而達到驗證與過濾資料的效果。(到現在還是不太理解的話,可以先繼續看下去!)
如果想要在 Python 中使用 RegEx,我們需要先匯入 re 模組,再匯入 re 模組後,我們就可以使用它來確認或尋找特定的模式。
import re
re 模組中的方法為了找到特定的模式,我們可以使用 re 模組中的方法來比對字串,然後進行匹配:
re.match(): 僅在字串的開頭進行搜尋,如果找到匹配的對象則返回匹配對象,否則返回 None。re.search(): 搜尋字串中的任意位置,如果找到則返回匹配對象,否則返回 None。re.findall(): 返回一個包含所有匹配項的列表。re.split(): 根據匹配點將字串分割,並返回一個列表。re.sub(): 將字串中的一個或多個匹配項進行替換。# 語法
re.match(substring, string, re.I)
# substring 是要尋找的子字串或模式
# string 是要檢查的文本
# re.I 代表忽略大小寫,不區分大小寫
# 範例
import re
txt = 'I love to teach python and javaScript'
# 返回一個匹配對象,包含範圍和匹配內容
match = re.match('I love to teach', txt, re.I)
print(match) # <re.Match object; span=(0, 15), match='I love to teach'>
span = match.span()
print(span) # (0, 15)
start, end = span
print(start, end) # 0, 15
substring = txt[start:end]
print(substring) # I love to teach
在上面的例子中,我們尋找的模式是 “I love to teach”。match 方法僅會在字串的開頭進行匹配,如果字串不以這個模式開頭,則返回 None。
import re
txt = 'I love to teach python and javaScript'
match = re.match('I like to teach', txt, re.I)
print(match) # None
由於字串並不是 “I like to teach” 開頭,因此沒有匹配結果,match 方法會返回 None。
# 語法
re.search(substring, string, re.I)
# 範例
import re
txt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''
match = re.search('first', txt, re.I)
print(match) # <re.Match object; span=(100, 105), match='first'>
span = match.span()
print(span) # (100, 105)
start, end = span
print(start, end) # 100, 105
substring = txt[start:end]
print(substring) # first
search 方法比 match 更方面,因為它會在整個字串中尋找模式。search 返回第一個匹配的對象,而非所有匹配項。如果找不到匹配,則會返回 None。如果想要尋找所有的匹配,可以改使用 findall 方法。
相比 search(),findall() 方法返回一個包含所有匹配項的列表。
import re
txt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language of many languages'''
matches = re.findall('language', txt, re.I)
print(matches) # ['language', 'language', 'language']
如上所示,字串 “language” 出現了三次。
現在我們來找找看字串中出現的 “Python” 和 “python”。
import re
matches = re.findall('python', txt, re.I)
print(matches) # ['Python', 'python']
由於我們使用了 re.I 標誌,意味著我們希望正規表達式所查找的規律「不區分大小寫」。如果不使用 re.I,那根據上面的範例,就只會尋找大小鞋完全符合 "python" 的字串。
在 Python 中,我們會使用 r'' 來宣告正則表達式。
下面的範例也示範了如何忽略大小寫來尋找 “apple”:
import re
regex_pattern = r'apple'
txt = 'Apple and banana are fruits. An old cliche says an apple a day keeps the doctor away.'
matches = re.findall(regex_pattern, txt, re.I)
print(matches) # ['Apple', 'apple']
若我們不想使用 re.I,但仍然想找到符合 python 且不區分大小寫,我們必須更改模式來匹配這樣的模式:
# 方法一
import re
matches = re.findall('Python|python', txt)
print(matches) # ['Python', 'python']
# 方法二
import re
matches = re.findall('[Pp]ython', txt)
print(matches) # ['Python', 'python']
這兩種方式也可以得到相同的效果,'Python|python' 表示搜尋 “Python” 或 “python”;'[Pp]ython' 表示搜尋 “P” 或 “p” 開頭的 “ython”。
我們直接透過範例,看看如何使用 sub 方法將字串中的某些匹配項替換掉成其他字串:
import re
txt = '''Python is the most beautiful language that a human being has ever created.
I recommend python for a first programming language'''
match_replaced = re.sub('Python|python', 'JavaScript', txt, re.I)
print(match_replaced) # JavaScript is the most beautiful language that a human being has ever created.
split 來分割字串如果使用 split() 方法,會返回一個串列。
import re
txt = '''I am a teacher and I love teaching.
There is nothing as rewarding as educating and empowering people.'''
print(re.split('\n', txt)) # 使用 \n 進行分割
下面舉例了一些常見的正規表達式符號,如果想知道更多的 RegEx 用法,可以到這個網站 regex101 更深入地認識 RegEx。
[]: 一組字符集[a-c]: 表示 a 或 b 或 c[A-Z]: 表示任意大寫字母[0-9]: 表示任意數字\\: 用來跳脫特殊字符\d: 匹配數字\D: 匹配非數字.: 匹配除換行符以外的任何字符^: 開頭$: 結尾*: 0 次或多次+: 1 次或多次?: 0 次或 1 次{n}: 精確匹配 n 個字符{n,m}: 匹配 n 到 m 個字符|: 或():捕獲和分組一開始在解 codewars 某些類型的問題時,像是「過濾目標字串,只保留特定的字串模式」時,常常會忘記有 RegEx 這個方便的方法,會傻乎乎地想要透過類似 filter 的方式,手動過濾模式,所以未來遇到跟字串過濾有關係的狀況時,可以先下意識地思考能不能用 RegEx 處理,至於 RegEx 裡面各種稀奇古怪的符號,如果能記起來當然好,但記不起來,打開 GPT 就是了,不用強求一定得背起來。

