
Kueue 是一個基於配額共享的作業排隊系統,用於管理配額以及作業如何使用配額,尤其適用於像機器學習模型訓練這類資源密集型的工作負載。Kueue 決定何時應該等待 Job,何時應該允許 Job 啟動 ( 可以創建 Pod ) 以及何時應該搶佔 Job ( 刪除活動 Pod )。
接下來,我們將分析 Kueue 的核心概念以及基本配置。
Google Kubernetes Engine (GKE) Kueue 是一個用於原生地協調工作負載在 GKE 叢集中的作業批次工作排程器。它通過一個分層的公平共享佇列系統來管理工作負載,確保各種工作負載類別獲得其資源份額,並根據可用資源,以先進先出的方式處理工作負載。
Kueue 將 K8s 中的工作負載資源請求轉換為抽象資源配額,允許叢集管理員在命名空間或其他任意邊界之間定義和實施容量分配。當工作負載提交到 Kueue 佇列時,它會等待直到與其資源請求匹配的配額可用。這可以防止某些工作負載獨占叢集資源,並確保公平訪問。
Kueue 還支援從核心工作排程器中斷 Pod,允許使用盡可能多的可用資源,並在更高優先級的工作負載到達時搶佔低優先級的工作負載。這對於需要快速啟動或必須滿足特定 SLA 的工作負載而言尤其有用。
通過其簡單的 API 和與現有 Kubernetes 工具的集成,Kueue 簡化了批次工作負載管理,同時在共享叢集中確保公平性和效率。
Kueue 將 ResourceFlavor 作為異構環境的一項功能。 如下圖所示,可以在 ClusterQueue 中為每種計算資源類型指定 ResourceFlavor,並將 ResourceFlavor 中指定的標籤用作 Workload 的 nodeSelector。
ClusterQueue 是一個集群範圍的物件,用於管理資源池,例如 Pod、CPU、記憶體和硬體加速器。ClusterQueue 定義:
ClusterQueue 管理 Resource Flavor 的配額,包括使用限制和使用順序。spec.resourceGroups.coveredResources可管理四種資源:cpu、memory、nvidia.com/gpu 和 ephemeral-storage。LocalQueue 是一個命名空間物件,接受來自命名空間中使用者的工作負載。 不同命名空間的LocalQueue可以指向同一個ClusterQueue,它們可以在其中共用資源的配額。 LocalQueue 指向一個 ClusterQueue,從中分配資源以運行其 workload(工作負載)。
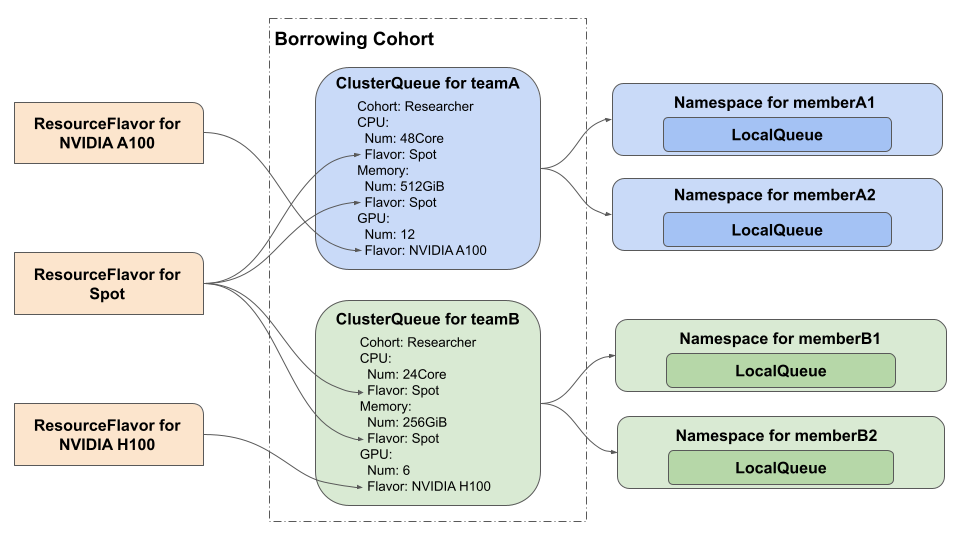
有兩個使用排隊平台的團隊,teamA 和 teamB,每個團隊有兩個成員,memberA1、memberA2、memberB1 和 memberB2。 此時,如無所示,管理員預定義了 teamA 和 teamB 可以被 ClusterQueue 使用的計算資源量。
使用者(如 memberA1)創建一個 LocalQueue,用於指定他們想要在各自的命名空間中使用的 ClusterQueue。 之後,用戶可以創建一個 Workload,這是一組需要同時執行的 Job,並將 Workload 放在一個 Queue 中並按順序執行它們。
為了部署實驗環境所需的機器,可以參考 Day3 的 Terraform 範例,使用 Day3 範例創建的 Cluster。
node-pool-variables.tf
module "gke" {
node_pools = [
var.node_pool_cpu.config,
var.node_pool_cpu-spot.config,
]
node_pools_labels = {
"${var.node_pool_cpu.config.name}" = var.node_pool_cpu.kubernetes_label
"${var.node_pool_cpu-spot.config.name}" = var.node_pool_cpu-spot.kubernetes_label
}
node_pools_taints = {
"${var.node_pool_cpu.config.name}" = var.node_pool_cpu.taints
"${var.node_pool_cpu-spot.config.name}" = var.node_pool_cpu-spot.taints
}
node_pools_resource_labels = {
"${var.node_pool_cpu.config.name}" = var.node_pool_cpu.node_pools_resource_labels
"${var.node_pool_cpu-spot.config.name}" = var.node_pool_cpu-spot.node_pools_resource_labels
}
}
### Node pool
variable "node_pool_cpu" {
default = {
config = {
name = "cpu"
machine_type = "n2-standard-8"
max_pods_per_node = 64
node_locations = "us-central1-a"
autoscaling = true
min_count = 1
max_count = 2
local_ssd_count = 0
spot = false
disk_size_gb = 50
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
enable_gcfs = true
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
preemptible = false
}
node_pools_resource_labels = {
team = "cpu"
}
kubernetes_label = {
role = "cpu"
}
taints = []
}
}
設定 GKE 集群,在 GKE 上安裝 v0.8.0 版本的 Kueue
$ VERSION=v0.8.0 # 安裝 v0.8.0 版本的 Kueue
$ kubectl apply --server-side -f \
https://github.com/kubernetes-sigs/kueue/releases/download/$VERSION/manifests.yaml
創建兩個名為 team-a 和 team-b 的 Namespace,待會要為此 Namespace 創建實驗用的 Job
$ kubectl create namespace team-a
$ kubectl create namespace team-b
在本教程中,為 CPU、記憶體創建一個 ResourceFlavor,而不使用標籤或污點。
kubectl apply -f ResourceFlavor.yaml
# ResourceFlavor.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: default-flavor # 此 ResourceFlavor 將用於所有資源
kubectl apply -f cluster-queue.yaml
# cluster-queue.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: default-cluster-queue
spec:
namespaceSelector: {} # Available to all namespaces
queueingStrategy: BestEffortFIFO # Default queueing strategy
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: default-flavor
resources:
- name: "cpu"
nominalQuota: 6
- name: "memory"
nominalQuota: 6Gi
使用順序由 .spec.queueingStrategy 確定,其中有兩種配置:
以上 cluster-queue.yaml 我們只有設定cpu、memory規範請求,請求如下:
命名空間 team-a 和 team-b 中的 LocalQueue 指向 .spec.clusterQueue 下的同一 ClusterQueue cluster-queue。
# local-queue.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: team-a # LocalQueue 在 team-a namespace 底下
name: localqueue-team-a
spec:
clusterQueue: default-cluster-queue # 指向 default-cluster-queue
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: team-b # LocalQueue 在 team-b namespace 底下
name: localqueue-team-b
spec:
clusterQueue: default-cluster-queue # 指向 default-cluster-queue
以下 team-a Job 的 resources.requests.cpu 為 1 Core,resources.requests.memory 為 1 Gi
# sample-job-team-a.yaml
apiVersion: batch/v1
kind: Job
metadata:
namespace: team-a
generateName: sample-job-team-a-
annotations:
kueue.x-k8s.io/queue-name: localqueue-team-a # 指向 localqueue-team-a LocalQueue
spec:
ttlSecondsAfterFinished: 60 # Job 將在 60 秒後刪除
parallelism: 3 # 同時執行 3 個副本
completions: 3 # 需要完成 3 次
suspend: true # 設定為 true 以允許 Kueue 控制 Job
template:
spec:
containers:
- name: dummy-job
image: gcr.io/k8s-staging-perf-tests/sleep:latest
args: ["10s"] # Sleep for 10 seconds
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "1"
memory: "1Gi"
restartPolicy: Never
以下 team-b Job 的 resources.requests.cpu 為 2 Core,resources.requests.memory 為 2 Gi
# sample-job-team-b.yaml
apiVersion: batch/v1
kind: Job
metadata:
namespace: team-b # Job 在 team-b namespace 底下
generateName: sample-job-team-b-
annotations:
kueue.x-k8s.io/queue-name: localqueue-team-b # 指向 localqueue-team-b LocalQueue
spec:
ttlSecondsAfterFinished: 60 # Job 將在 60 秒後刪除
parallelism: 3 # 同時執行 3 個副本
completions: 3 # 需要完成 3 次
suspend: true # 設定為 true 以允許 Kueue 控制 Job
template:
spec:
containers:
- name: dummy-job
image: gcr.io/k8s-staging-perf-tests/sleep:latest
args: ["10s"] # Sleep for 10 seconds
resources:
requests:
cpu: "2"
memory: "2Gi"
limits:
cpu: "2"
memory: "2Gi"
restartPolicy: Never
使用以下指令,每秒連續創建 sample-job-team-a 及 sample-job-team-b
$ while :; do kubectl create -f sample-job-team-a.yaml; sleep 1; done
$ while :; do kubectl create -f sample-job-team-b.yaml; sleep 1; done
使用以下指令觀察正在排隊的 Job、在 ClusterQueue 中允許的 Job。
$ watch -n 1 kubectl -n team-a get jobs
$ watch -n 1 kubectl -n team-a get pods
$ watch -n 1 kubectl -n team-b get jobs
$ watch -n 1 kubectl -n team-b get pods
$ watch -n 2 kubectl get clusterqueues -o wide
Kueue 有效地管理了 teamA 和 teamB 的資源共享。通過 clusterQueue: default-cluster-queue,Kueue 限制了總資源使用量在 6 CPU 核心和 6Gi 記憶體內。
由於兩個團隊的 Job 都需要 3 個副本並行運行,Kueue 的 BestEffortFIFO 策略動態地調度資源,使得同一時間可以運行 6 個 teamA 的 Job (每個請求 1 CPU 和 1Gi 內存) 或 3 個 teamB 的 Job (每個請求 2 CPU 和 2Gi 內存)。
實驗結果清晰地展示了 Kueue 如何在資源限制下,公平地在不同團隊間分配資源,並確保 Job 按順序執行,防止資源競爭和饑餓。 這驗證了 Kueue 作為 Kubernetes 批處理工作負載調度器的有效性。

