上一章節,我們已經學會了基本的 Kueue 配置。而本章節將深入探討 Kueue 的運作機制,並闡述其如何透過配額管理來確保不同團隊或用戶之間的公平性,同時最大化叢集資源利用率。對於機器學習模型訓練而言,Kueue 能有效管理多個訓練任務的並行執行,避免資源爭搶,並根據預先設定的配額優先處理重要的訓練任務,從而縮短模型訓練時間並提升整體效率。
接下來,我們將分析 Kueue 的核心概念,例如配額、優先級和佇列,並演示如何配置和使用 Kueue 來最佳化 Kubernetes 叢集的資源利用率。實驗結果量化 Kueue 的效能,並展示其在提升叢集效率和降低 Job 等待時間方面的效益。
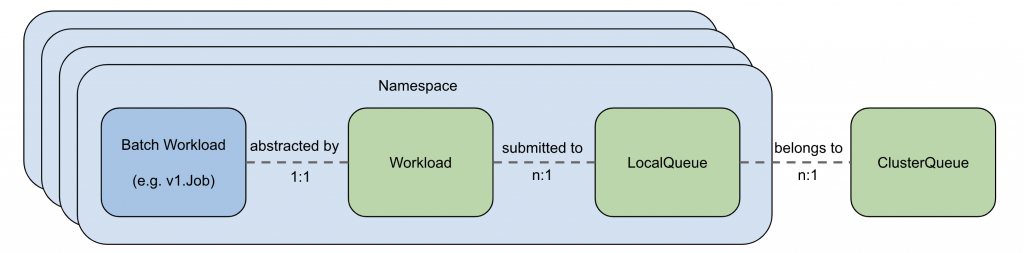
用 Kueue 介紹如何實現 Job 排隊系統、配置 Google Kubernetes Engine (GKE) 上不同命名空間之間的工作負載資源和配額共享,以及如何最大限度地提高集群的利用率。
為了部署實驗環境所需的機器,可以參考 Day3 的 Terraform 範例。
使用 Day21 範例創建的Cluster,再多創建一個 Spot 機器的 Node Pool,為 autoscaling 0~4。
node-pool-variables.tf
module "gke" {
node_pools = [
var.node_pool_cpu.config,
var.node_pool_cpu-spot.config,
]
node_pools_labels = {
"${var.node_pool_cpu-spot.config.name}" = var.node_pool_cpu-spot.kubernetes_label
}
node_pools_taints = {
"${var.node_pool_cpu-spot.config.name}" = var.node_pool_cpu-spot.taints
}
node_pools_resource_labels = {
"${var.node_pool_cpu-spot.config.name}" = var.node_pool_cpu-spot.node_pools_resource_labels
}
}
### Node pool
variable "node_pool_cpu-spot" {
default = {
config = {
name = "cpu-spot"
machine_type = "n2-standard-4"
max_pods_per_node = 64
node_locations = "us-central1-a"
autoscaling = true
min_count = 0
max_count = 4
local_ssd_count = 0
spot = true
disk_size_gb = 50
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
enable_gcfs = true
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
preemptible = false
}
node_pools_resource_labels = {
team = "cpu-spot"
}
kubernetes_label = {
role = "cpu-spot"
}
taints = []
}
}
創建 ResourceFlavor,kubectl apply -f flavors.yaml
on-demand 的標簽設置為 cloud.google.com/gke-provisioning: standard
spot 的標簽設置為 cloud.google.com/gke-provisioning: spot
# flavors.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: standard-on-demand
spec:
nodeLabels:
cloud.google.com/gke-provisioning: standard
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: spot
spec:
nodeLabels:
cloud.google.com/gke-provisioning: spot
創建 ClusterQueue 和 LocalQueue,kubectl apply -f cq-team-a.yaml ,kubectl apply -f cq-team-b.yaml。
.spec.cohort: all-teams 的同類群組。當兩個或更多 ClusterQueue 共享一個同類群組時,它們可以向彼此借用未使用的配額。cq-team-a 和 cq-team-b 共用同一個 cohort: all-teams。cq-team-a ClusterQueue 的 flavors 中的 standard-on-demand ClusterQueue 設定 cpu 請求的總和 10 core 以下,可以和同樣 cohort: all-teams 的 ClusterQueue 借 5 core,而 memory 請求的總和 10 Gi 以下,可以和同樣 cohort: all-teams 的 ClusterQueue 借 15 Gi。cq-team-b ClusterQueue 的 flavors 中的 standard-on-demand ClusterQueue 設定 cpu 請求的總和 6 core 以下,可以和同樣 cohort: all-teams 的 ClusterQueue 借 3 core,而 memory 請求的總和 6 Gi 以下,可以和同樣 cohort: all-teams 的 ClusterQueue 借 3 Gi。namespace: team-a 命名空間中用戶的工作負載,待會會在此命名空間創建 JOB 物件,將其發送到 lq-team-a LocalQueue,然後,cq-team-a ClusterQueue 會分配這些資源。# cq-team-a.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: cq-team-a
spec:
cohort: all-teams # cq-team-a 和 cq-team-b 共用同一個 cohort: all-teams
namespaceSelector:
matchLabels:
# 只有 team-a 可以將作業直接提交到此佇列,之後可以透過群組分享此佇列。
kubernetes.io/metadata.name: team-a
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: standard-on-demand
resources:
- name: "cpu"
nominalQuota: 10
borrowingLimit: 5
- name: "memory"
nominalQuota: 10Gi
borrowingLimit: 15Gi
# 暫時不使用 spot ResourceFlavor,所以將 cpu 及 memory 都設置為 0
- name: spot
resources:
- name: "cpu"
nominalQuota: 0
- name: "memory"
nominalQuota: 0
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: team-a
name: lq-team-a
spec:
clusterQueue: cq-team-a # 指向 ClusterQueue team-a-cq
# cq-team-b.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: cq-team-b
spec:
cohort: all-teams # cq-team-a 和 cq-team-b 共用同一個 cohort: all-teams
namespaceSelector:
matchLabels:
# 只有 team-b 可以將作業直接提交到此佇列,之後可以透過群組分享此佇列。
kubernetes.io/metadata.name: team-b
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: standard-on-demand
resources:
- name: "cpu"
nominalQuota: 6
borrowingLimit: 3
- name: "memory"
nominalQuota: 6Gi
borrowingLimit: 3Gi
# 暫時不使用 spot ResourceFlavor,所以將 cpu 及 memory 都設置為 0
- name: spot
resources:
- name: "cpu"
nominalQuota: 0
- name: "memory"
nominalQuota: 0
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: team-b # LocalQueue under team-b namespace
name: lq-team-b
spec:
clusterQueue: "cq-team-b" # 指向 ClusterQueue team-b-cq
創建 Job 並觀察允許的工作負載,為這兩個 ClusterQueue(將休眠 10 秒)生成 Job,包含三個並行 Job,三個 Job 都完成才算完成。然後,Job 會在 60 秒後進行清理。
以下兩個 Job 的 resources.requests.cpu 為 1 Core,resources.requests.memory 為 1 Gi
team-a 命名空間下的 job-team-a.yaml
# job-team-a.yaml
apiVersion: batch/v1
kind: Job
metadata:
namespace: team-a
generateName: sample-job-team-a- # Job 名稱前綴
labels:
kueue.x-k8s.io/queue-name: lq-team-a # 指向 `lq-team-a` LocalQueue
spec:
ttlSecondsAfterFinished: 60 # Job 將在 60 秒後刪除
parallelism: 3 # 同時執行 3 個副本
completions: 3 # 需要完成 3 次
suspend: true # 設定為 true 以允許 Kueue 控制 Job
template:
spec:
containers:
- name: test-job
image: gcr.io/k8s-staging-perf-tests/sleep:latest
args: ["10s"] # Sleep for 10 seconds
resources:
requests:
cpu: "1"
memory: "1Gi"
restartPolicy: Never
team-b 命名空間下的 job-team-b.yaml
# job-team-b.yaml
apiVersion: batch/v1
kind: Job
metadata:
namespace: team-b
generateName: sample-job-team-b- # Job 名稱前綴
labels:
kueue.x-k8s.io/queue-name: lq-team-b # 指向 `lq-team-b` LocalQueue
spec:
ttlSecondsAfterFinished: 60 # Job 將在 60 秒後刪除
parallelism: 3 # 同時執行 3 個副本
completions: 3 # 需要完成 3 次
suspend: true # 設定為 true 以允許 Kueue 控制 Job
template:
spec:
containers:
- name: dummy-job
image: gcr.io/k8s-staging-perf-tests/sleep:latest
args: ["10s"] # Sleep for 10 seconds
resources:
requests:
cpu: "1"
memory: "1Gi"
restartPolicy: Never
監控活躍 ClusterQueue cq-team-a 的 PromQL 的查詢
kueue_pending_workloads{cluster_queue="cq-team-a", status="active"} or kueue_admitted_active_workloads{cluster_queue="cq-team-a"}
監控活躍 ClusterQueue cq-team-b 的 PromQL 的查詢
kueue_pending_workloads{cluster_queue="cq-team-b", status="active"} or kueue_admitted_active_workloads{cluster_queue="cq-team-b"}
監控集群中的節點的查詢
count(kube_node_info)
使用以下指令,連續創建 job-team-a 及 job-team-b
$ while :; do kubectl create -f job-team-a.yaml; sleep 1; done
$ while :; do kubectl create -f job-team-b.yaml; sleep 1; done
觀察 Prometheus 中正在排隊的 Job。或使用以下命令
$ watch -n 2 kubectl get clusterqueues -o wide
NAME COHORT STRATEGY PENDING WORKLOADS ADMITTED WORKLOADS
cq-team-a all-teams BestEffortFIFO 29 3
cq-team-b all-teams BestEffortFIFO 25 4
等待一段時間,確認開始有 Job 排隊中,PENDING WORKLOADS 開始不為 0,之後將上述步驟的創建 job-team-b.yaml 的命令停下來。
確認 cq-team-b Clusterqueue 都消化完了。
$ watch -n 2 kubectl get clusterqueues -o wide
NAME COHORT STRATEGY PENDING WORKLOADS ADMITTED WORKLOADS
cq-team-a all-teams BestEffortFIFO 32 5
cq-team-b all-teams BestEffortFIFO 0 0
輸入以下指令,確認當下的 cq-team-a Clusterqueue 狀態,滑到輸出的指令最末尾,可以查到 Flavors Usage
$ kubectl describe clusterqueue cq-team-a
...以上省略...
Flavors Usage:
Name: on-demand
Resources:
Borrowed: 5
Name: cpu
Total: 15
Borrowed: 5Gi
Name: memory
Total: 15Gi
Name: spot
Resources:
Borrowed: 0
Name: cpu
Total: 0
Borrowed: 0
Name: memory
Total: 0
Pending Workloads: 32
Reserving Workloads: 5
發現 cq-team-a Clusterqueue 開始向同樣 cohort: all-teams的 cq-team-b 借用的可用资源。借了 5 cores cpu 及 5 Gi memory,因此總共有 15 core cpu 和 15 Gi memory 可以使用。
每一個 Job 同時執行 3 個副本,使一個 Job 進入 Clusterqueues ADMITTED WORKLOADS 總共所需 3 core cpu 和 3 Gi memory。經過計算得出 15/3=5,Clusterqueues ADMITTED WORKLOADS 可以容納 5 個 Job同時執行,計算結果和輸出結果一至。
至於消化不了的 Job 會進到 PENDING WORKLOADS,等到 ADMITTED WORKLOADS 中的 Job 執行完成後,才能將 PENDING WORKLOADS 的 Job 移到 ADMITTED WORKLOADS 開始執行。
這時可以再次啟動 job-team-b
$ while :; do kubectl create -f job-team-b.yaml; sleep 1; done
然後檢查 cq-team-a Clusterqueue 狀態
$ kubectl describe clusterqueue cq-team-a
...以上省略...
Flavors Usage:
Name: on-demand
Resources:
Borrowed: 0
Name: cpu
Total: 9
Borrowed: 0
Name: memory
Total: 9Gi
會發現 cq-team-a Clusterqueue 剛剛和 Clusterqueue job-team-b 借用的資源被收回去了,原因是因為彼此都正在啟動, 不能相互借用資源
創建一個名為 cq-spot 的新 ClusterQueue,同類群組設置為 cohort: all-teams,
kubectl apply -f cq-spot.yaml
# cq-spot.yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: spot-cq
spec:
cohort: all-teams # 和 cq-team-a 及 cq-team-b 使用同樣的 cohort
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: spot
resources:
- name: "cpu"
nominalQuota: 40
- name: "memory"
nominalQuota: 144Gi
使用以下指令,連續創建 job-team-a 及 job-team-b
$ while :; do kubectl create -f job-team-a.yaml; sleep 1; done
$ while :; do kubectl create -f job-team-b.yaml; sleep 1; done
使用 kubectl get nodes 指令查看 spot 機器有沒有 autoscaling 起來
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-demo2-cluster-cpu-280f2740-exvz Ready <none> 2d1h v1.30.3-gke.1639000
gke-demo2-cluster-cpu-280f2740-hbzc Ready <none> 28m v1.30.3-gke.1639000
gke-demo2-cluster-cpu-280f2740-wodh Ready <none> 2d1h v1.30.3-gke.1639000
gke-demo2-cluster-cpu-spot-f7e9537c-8ltm Ready <none> 2m30s v1.30.3-gke.1969001
gke-demo2-cluster-cpu-spot-f7e9537c-d79w Ready <none> 2m33s v1.30.3-gke.1969001
確定 Spot 機器 Ready 了以後,輸入 kubectl get clusterqueues -o wide ,kubectl describe clusterqueue cq-team-a 和 kubectl describe clusterqueue cq-team-b指令,查看 clusterqueue 資源被借用的情況。
$ kubectl get clusterqueues -o wide
NAME COHORT STRATEGY PENDING WORKLOADS ADMITTED WORKLOADS
cq-team-a all-teams BestEffortFIFO 68 14
cq-team-b all-teams BestEffortFIFO 66 15
spot-cq all-teams BestEffortFIFO 0 0
$ kubectl describe clusterqueue cq-team-a
...以上省略...
Flavors Usage:
Name: on-demand
Resources:
Borrowed: 0
Name: cpu
Total: 9
Borrowed: 0
Name: memory
Total: 9Gi
Name: spot
Resources:
Borrowed: 19
Name: cpu
Total: 19
Borrowed: 19Gi
Name: memory
Total: 19Gi
Pending Workloads: 68
Reserving Workloads: 14
$ kubectl describe clusterqueue cq-team-b
...以上省略...
Flavors Usage:
Name: on-demand
Resources:
Borrowed: 2
Name: cpu
Total: 12
Borrowed: 2Gi
Name: memory
Total: 12Gi
Name: spot
Resources:
Borrowed: 17
Name: cpu
Total: 17
Borrowed: 17Gi
Name: memory
Total: 17Gi
Pending Workloads: 66
Reserving Workloads: 15
可以發現 clusterqueue cq-team-a 及cq-team-b 因為彼此都正在啟動, 不能相互借用資源,但是因為增加了使用同樣 cohort: all-teams 的 Spot 機器的 spot-cq ClusterQueue,所以 cq-team-a 及cq-team-b 都可以向 spot-cq ClusterQueue 借用資源,而因為我將 Spot Node Pool 設定成 Autoscaling,所以 Spot 機器的節點數量會增加 。
依照spot-cq ClusterQueue 設定,40 core cpu 及 144 GI memory。
本文演示了如何使用 Kueue 在 GKE 上構建一個作業排隊系統,實現 Namespace 間的資源配額共享,並最大化集群利用率。
文章內模擬了兩個團隊共享資源,並利用同類群組(Cohort)機制實現配額借用,提高資源利用效率。 當一個團隊資源空閒時,另一個團隊可以借用,避免資源浪費。此外,教程還引入了 Spot 虛擬機作為溢出資源池,進一步提升集群彈性和成本效益。
通過 Prometheus 監控,可以實時觀察作業排隊情況和資源分配。 Kueue 有效地解決了多團隊共享集群資源的分配和管理難題,提高了集群整體效率。

