在完成前面兩章的基本知識說明後
想要帶大家去抓比較真實網頁情境
可以把這些技術概括
| 標題 | 技術說明 | 目標 |
|---|---|---|
| HTTP Requests | 通過 requests 庫向網頁伺服器發送 HTTP 請求,並獲取回應 |
獲取網頁的數據或 API 資料 |
| HTML 結構 | 掌握 HTML 文件的結構,包括標籤、屬性及其關係 | 分析網頁數據位置,準備提取數據 |
| BeautifulSoup 與 lxml | 使用 BeautifulSoup 或 lxml 庫解析 HTML 代碼,查找特定的標籤或屬性 | 提取網頁中的結構化數據 |
| 正規表達式(Regex) | 使用正規表達式來匹配和提取符合特定模式的數據 | 清理和解析網頁中非結構化的數據 |
| Cookie & Session | 透過處理 Cookie 和 Session 保持與伺服器的狀態或登入狀態 | 模擬登入、保持狀態並抓取受保護的內容 |
| Selenium | 使用 Selenium 自動控制瀏覽器,處理動態網頁抓取 | 抓取 JavaScript 生成的網頁內容 |
| Excel 網頁爬蟲 (額外) | 使用 Microsoft Excel 的 Power Query 或 VBA 進行簡單的網頁抓取 | 快速抓取靜態網頁的表格數據 |
| 反爬蟲技術 | 網站使用 IP 限制、Captcha、頻率限制等來阻止爬蟲 | 避免觸發封鎖,優化爬蟲行為,保持穩定性 |
| robots.txt | 網站提供的協議文件,指定允許或禁止的爬取範圍 | 尊重網站的爬取限制,避免違反爬取規則 |
前三項在昨天的章節中已經有基礎概念了
這邊簡單說明一下其他概念
資料驗證 : 確保用戶輸入的資料符合特定格式,如電子郵件地址、電話號碼等。文字搜尋與替換 : 可以把符合的文字替換。比如說日期:202410065轉成2024年10月06日網頁輸入:檢查中的輸入是否符合預期格式,提升用戶體驗。分組分類:用括號匹配字串,提取使用。常用在NLP自然語言處理做分句𰀁分詞的任務。2.Cookie & Session : 其實就是儲存網頁的記憶鑰匙(存在瀏覽器或裝置中)。透過記憶這些之資訊,使用者只要在網站定的規範日期內,通常都可以不需要重新登入就可以瀏覽,在爬蟲世界中,可以模擬記憶登入的鑰匙透過程式傳送請求得到結果。
3.**Selenium ** : 現代的許多框架都是透過javascript動態產生的(vue、react、angular),也就是我們使用者沒有透過瀏覽器查看前,資料是不會出來的。那麼這個套件就是模擬這麼功能。
4.反爬蟲技術 : 其實就是網站不想讓妳爬,推出的各種機器人驗證。但這也就是工程師跟網站架設者的技術比拚!? 基本上不建議這樣
這邊不會把每個例子都帶到非常詳細
但會透過目標的破題思路去拆解
並且實作
第一個目標就是把yahoo tsmc stock 當日價格擷取後
存到excel裡面
https://tw.stock.yahoo.com/quote/2330.TW
我們可以看到以yahoo護國神山股價
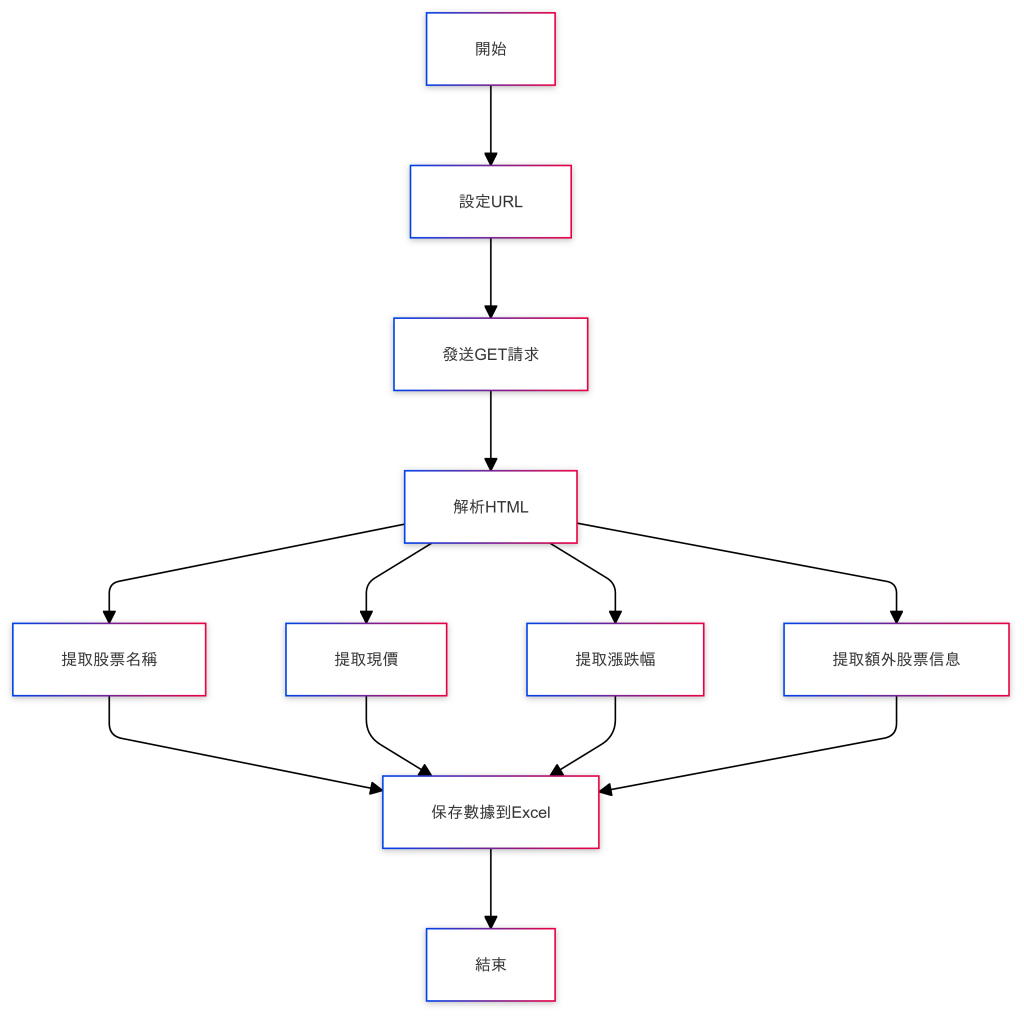
我們先透過流程圖來拆解動手程式前的設計思路
1.需求目的: 擷取神山股價到excel
2.分析設計: 首先我們需要把程式設計的流程列出來
有了設計架構思路後我們可以看一下時序圖展示的交互作用會怎麼呈現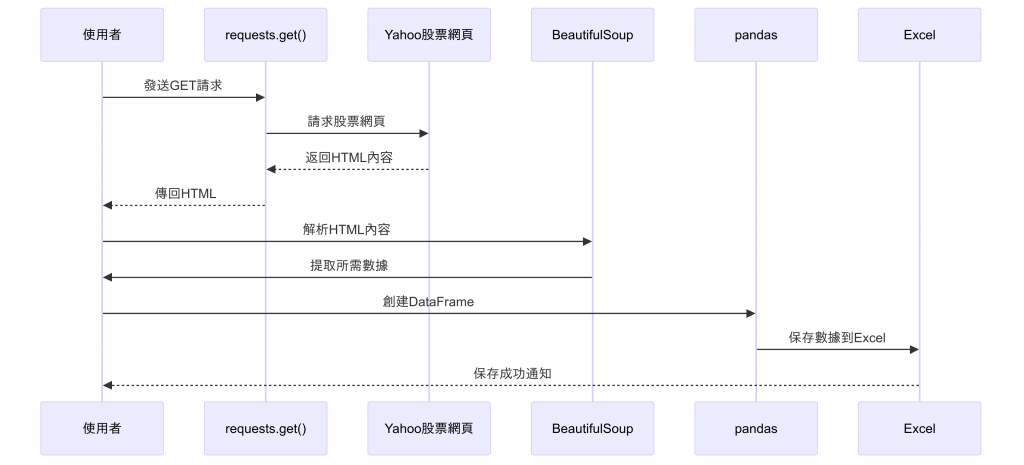
# 導入必要的庫
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 設定目標URL
url = "https://tw.stock.yahoo.com/quote/2330.TW"
# 設定請求頭,模擬瀏覽器行為
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
# }
# 發送GET請求並獲取網頁內容
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取股票名稱
try:
stock_name = soup.select_one('h1[class^="C($c-link-text)"]').text.strip()
except AttributeError:
stock_name = "無法獲取股票名稱"
# 提取股票現價
try:
price = soup.select_one('span[class*="Fz(32px)"]').text.strip()
except AttributeError:
price = "無法獲取價格"
# 提取股票漲跌
try:
change = soup.select_one('span[class*="Fz(20px)"]').text.strip()
except AttributeError:
change = "無法獲取漲跌"
# 提取額外的股票信息
info_elements = soup.select('div[class*="D(f) Jc(sb) Ai(c)"]')
additional_info = {}
for element in info_elements:
try:
label = element.select_one('span:nth-child(1)').text.strip()
value = element.select_one('span:nth-child(2)').text.strip()
additional_info[label] = value
except AttributeError:
continue
# 創建DataFrame存儲所有提取的數據
df = pd.DataFrame({
'股票名稱': [stock_name],
'股票代碼': ['2330'],
'現價': [price],
'漲跌': [change],
**additional_info
})
# 將數據保存到Excel文件
df.to_excel('2330_stock_data.xlsx', index=False)
print("數據已成功保存到2330_stock_data.xlsx文件中。")
相信大家在昨天
都有學習到BeautifulSoup
可以透過html的tag跟屬性來拆解
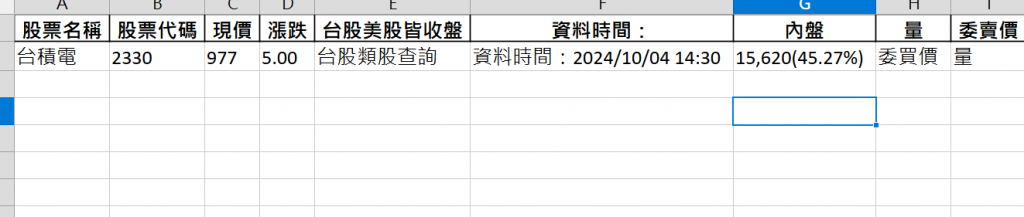
提取股票名稱 - 使用class選擇方式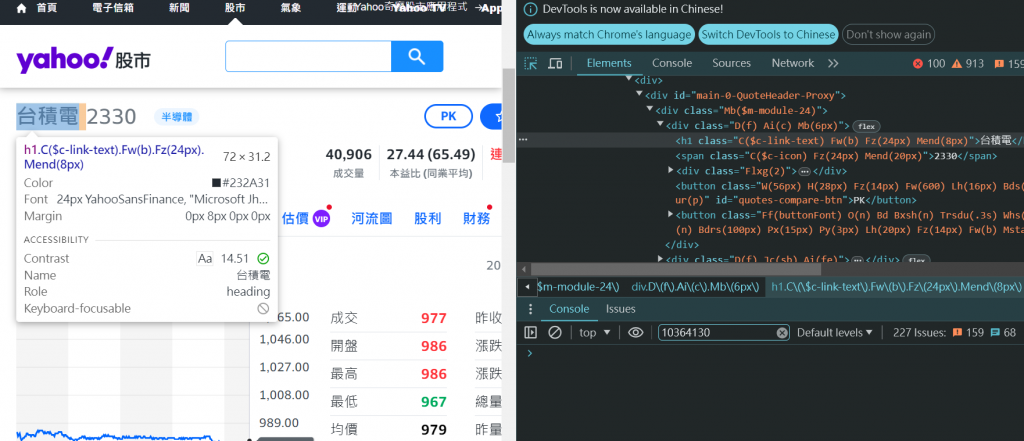
BeautifulSoup 解析。允許使用 CSS 選擇器 來查找與指定條件相符的第一個 HTML 元素。<h1> 元素,並且帶有一個 class。** tips ** 可以從上面的圖片 看到台積的名字就是在h1 tag標籤 class=C($c-link-text)這個class= 是html呈現的畫面,python的bs4語法或是有學過css選擇棄語法會透過這種方式來抓到資料
網頁的html看起來是
<h1 class="C($c-link-text) Fz(24px)"> 台積電 (2330) </h1>
stock_name = "台積電 (2330)"
正規表達式是一種用來匹配字符串的強大工具,可以用來搜索、提取、替換、分割字符串中的特定模式。Python 中通過 re 模組來實現正規表達式操作。
通常html結構的會bs4,沒有結構的文章會使用正規表達式撈起來
1.匹配:檢查字符串是否符合某種模式。
2.提取:從字符串中提取特定的模式部分。
3.替換:將符合條件的部分替換為其他字符串。
4.分割:將字符串根據特定模式進行分割。
| 語法 | 說明 | 範例 |
|---|---|---|
. |
匹配除換行符以外的任意單個字符。 | a.b 匹配 a1b、acb 等 |
^ |
匹配字符串的開始。 | ^abc 匹配以 abc 開頭的字符串 |
$ |
匹配字符串的結尾。 | abc$ 匹配以 abc 結尾的字符串 |
* |
匹配前一個字符 0 次或多次。 | a* 匹配 a、aa、空字符串 |
+ |
匹配前一個字符 1 次或多次。 | a+ 匹配 a、aa |
? |
匹配前一個字符 0 次或 1 次(非貪婪匹配)。 | a? 匹配 a 或空字符串 |
{n} |
精確匹配 n 次。 | a{3} 匹配 aaa |
{n,} |
匹配至少 n 次。 | a{2,} 匹配 aa、aaa 或更多 |
{n,m} |
匹配至少 n 次,最多 m 次。 | a{2,4} 匹配 aa、aaa、aaaa |
[] |
定義字符類,匹配方括號中的任意一個字符。 | [a-z] 匹配任意小寫字母 |
| ` | ` | 邏輯「或」,匹配左邊或右邊的選項。 |
\d |
匹配任意數字,等價於 [0-9]。 |
\d+ 匹配 123、456 |
\D |
匹配任意非數字字符,等價於 [^0-9]。 |
\D+ 匹配 abc、xyz |
\w |
匹配任意字母、數字或下劃線字符,等價於 [a-zA-Z0-9_]。 |
\w+ 匹配 abc123_ |
\W |
匹配任意非字母、數字或下劃線字符。 | \W+ 匹配 @#$ |
\s |
匹配任意空白字符(如空格、換行符、Tab),等價於 [ \t\n\r\f\v]。 |
\s+ 匹配空格、Tab 等 |
\S |
匹配任意非空白字符。 | \S+ 匹配 abc123 |
\b |
匹配單詞邊界(如單詞與空格之間)。 | \bword\b 匹配整個單詞 word |
\B |
匹配非單詞邊界。 | \Bword 匹配 password 內的 word |
() |
用於分組,將多個字符或表達式視為一個單元。 | (abc)+ 匹配 abcabc |
(?:) |
非捕獲分組,用於分組但不保存匹配結果。 | (?:abc) 不保存分組結果 |
(?=...) |
正向先行斷言,要求後面的字符必須匹配但不包括在結果中。 | a(?=\d) 匹配 a1 中的 a |
(?!...) |
負向先行斷言,要求後面的字符不能匹配但不包括在結果中。 | a(?!\d) 匹配 ab 中的 a |
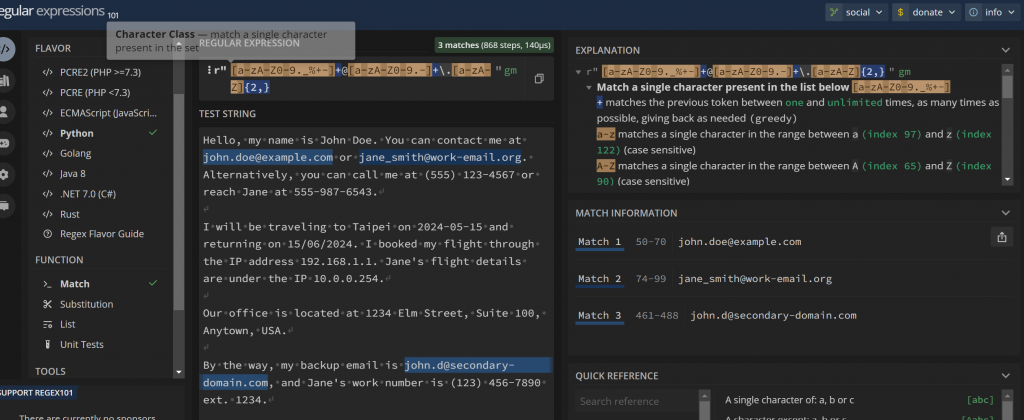
Hello, my name is John Doe. You can contact me at john.doe@example.com or jane_smith@work-email.org. Alternatively, you can call me at (555) 123-4567 or reach Jane at 555-987-6543.
I will be traveling to Taipei on 2024-05-15 and returning on 15/06/2024. I booked my flight through the IP address 192.168.1.1. Jane's flight details are under the IP 10.0.0.254.
Our office is located at 1234 Elm Street, Suite 100, Anytown, USA.
By the way, my backup email is john.d@secondary-domain.com, and Jane's work number is (123) 456-7890 ext. 1234.
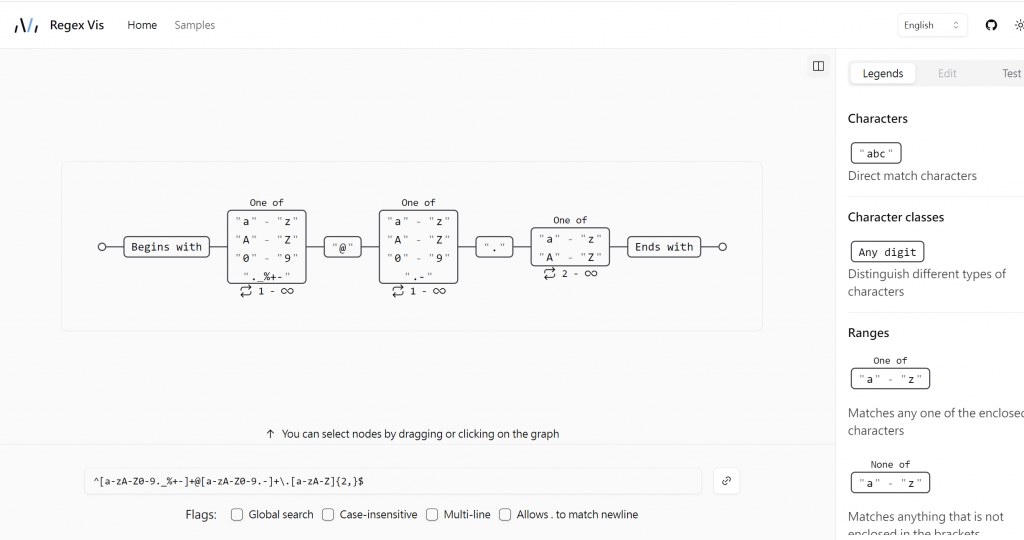
透過英文字母大小寫+小老鼠@+字段.字段
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
因為盡量避免爬取別的網站資料
所以我自己做了一個簡單的react範本
讓大家看demo
爬動態網站的應用
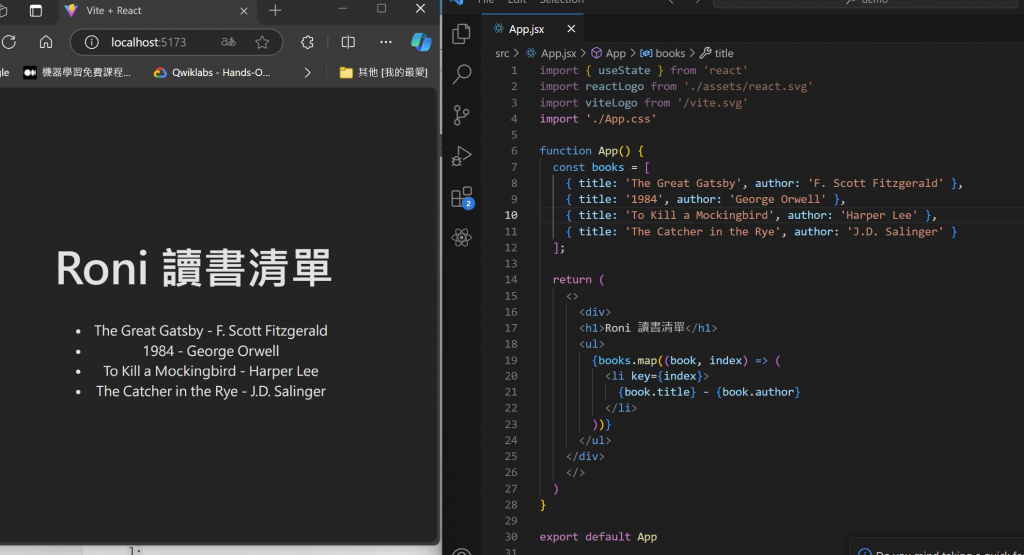
APP.js 這邊我是想要展示給大家看
前端書單的畫面
import { useState } from 'react'
import reactLogo from './assets/react.svg'
import viteLogo from '/vite.svg'
import './App.css'
function App() {
const books = [
{ title: 'The Great Gatsby', author: 'F. Scott Fitzgerald' },
{ title: '1984', author: 'George Orwell' },
{ title: 'To Kill a Mockingbird', author: 'Harper Lee' },
{ title: 'The Catcher in the Rye', author: 'J.D. Salinger' }
];
return (
<>
<div>
<h1>Roni 讀書清單</h1>
<ul>
{books.map((book, index) => (
<li key={index}>
{book.title} - {book.author}
</li>
))}
</ul>
</div>
</>
)
}
export default App
import requests
# 设置 API URL
api_url = 'http://localhost:5173' # 替换为实际的 API URL
# 设置请求的 headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 发送 GET 请求以获取数据
response = requests.get(api_url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 打印响应内容
print("请求成功,返回的数据:")
print(response.text) # 打印原始文本内容
else:
print(f"请求失败,状态码: {response.status_code}")
我們可以看到單純用
request蝦咪都謀~!?
原因是現代動態框架的應用就是使用者點進去網頁之後JS才會生成html元素
所以只用指令或是curl來打一定會是只看到基本html的訊息
內容都悾悾

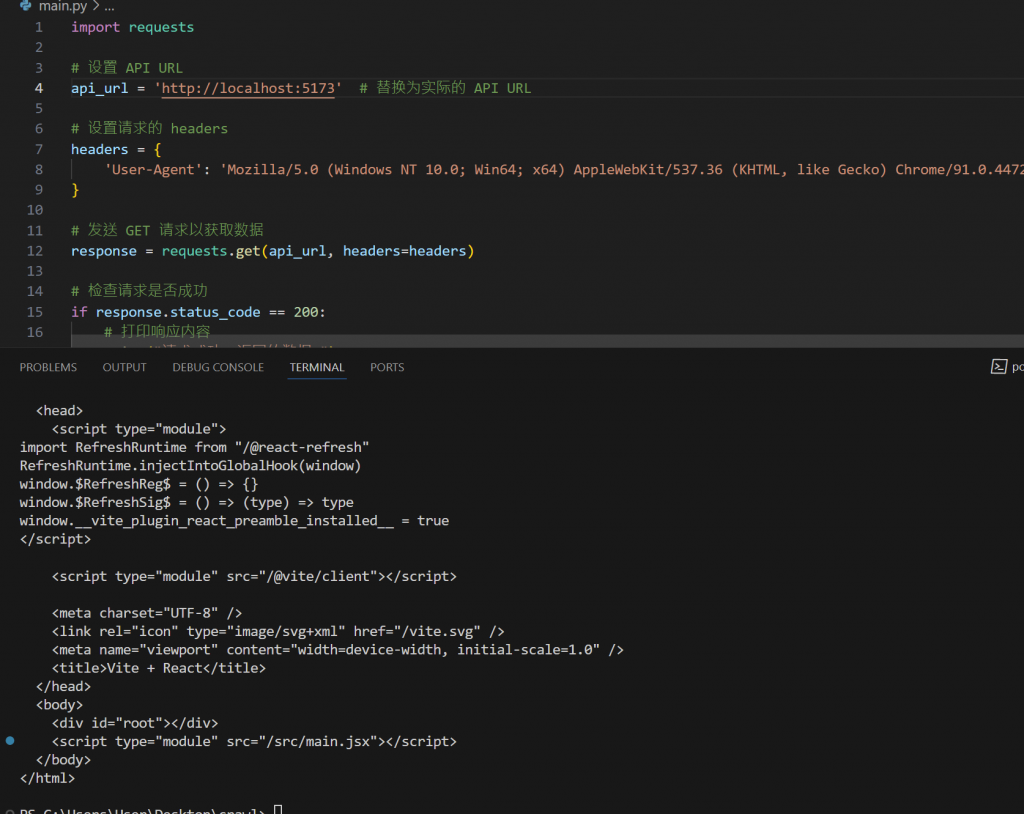
那聰民的各位一定想到解法了?
就是透過前面提到的模擬瀏覽器的做法來解決這個問題
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 設置 Chrome 瀏覽器
options = webdriver.ChromeOptions()
options.add_argument("--headless") # 無頭模式(可選)
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
# 訪問本地 React 應用
driver.get("http://localhost:5173")
# 等待頁面加載(可根據需要調整等待時間)
driver.implicitly_wait(10)
# 擷取書單資料
book_list = driver.find_element(By.TAG_NAME, "ul") # 獲取 <ul> 元素
books = book_list.find_elements(By.TAG_NAME, "li") # 獲取所有 <li> 元素
# 輸出書名和作者
for book in books:
print(book.text) # 每個 <li> 的文本
finally:
driver.quit() # 關閉瀏覽器
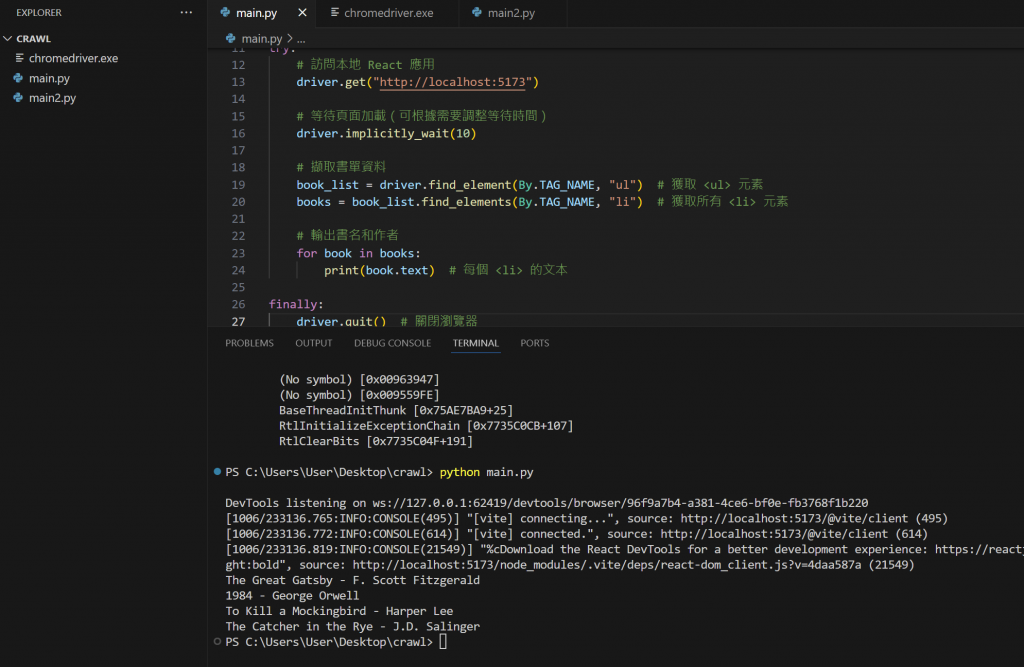
大家透過這個框架就會開啟瀏覽器
之後把模擬瀏覽器執行的動作
就可以把動態元素擷取回來搂~!!
使用一個輕量級的反爬蟲套件,例如 user-agents 來檢測 User-Agent 是否是爬蟲。
user-agents 是一個用於解析和分析 HTTP 請求中的 User-Agent 字串的 Python 套件。User-Agent 是瀏覽器或其他客戶端在 HTTP 請求中發送的一個標頭,用來標識自身的類型、版本以及運行平台等資訊。
pip install user-agents
from http.server import BaseHTTPRequestHandler, HTTPServer
import user_agents
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
# 獲取請求的 User-Agent
user_agent_str = self.headers.get('User-Agent', '')
# 使用 user-agents 套件解析 User-Agent
user_agent = user_agents.parse(user_agent_str)
# 檢查是否為爬蟲
if user_agent.is_bot:
self.send_response(403) # Forbidden
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(b'{"error": "Bot detected"}')
else:
# 正常的訪問
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(b'{"message": "Welcome, human user!"}')
# 啟動 HTTP 伺服器
def run(server_class=HTTPServer, handler_class=SimpleHTTPRequestHandler, port=8080):
server_address = ('', port)
httpd = server_class(server_address, handler_class)
print(f"Server running on port {port}...")
httpd.serve_forever()
if __name__ == '__main__':
run()
import requests
# 模擬爬蟲的 User-Agent
def crawl_as_bot():
headers = {
'User-Agent': 'Googlebot/2.1 (+http://www.google.com/bot.html)' # Googlebot 爬蟲
}
response = requests.get('http://127.0.0.1:8080/', headers=headers)
print("Bot Response:", response.status_code, response.text)
# 模擬正常使用者的 User-Agent
def crawl_as_human():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
response = requests.get('http://127.0.0.1:8080/', headers=headers)
print("Human Response:", response.status_code, response.text)
if __name__ == "__main__":
crawl_as_bot() # 模擬爬蟲
crawl_as_human() # 模擬正常使用者
執行~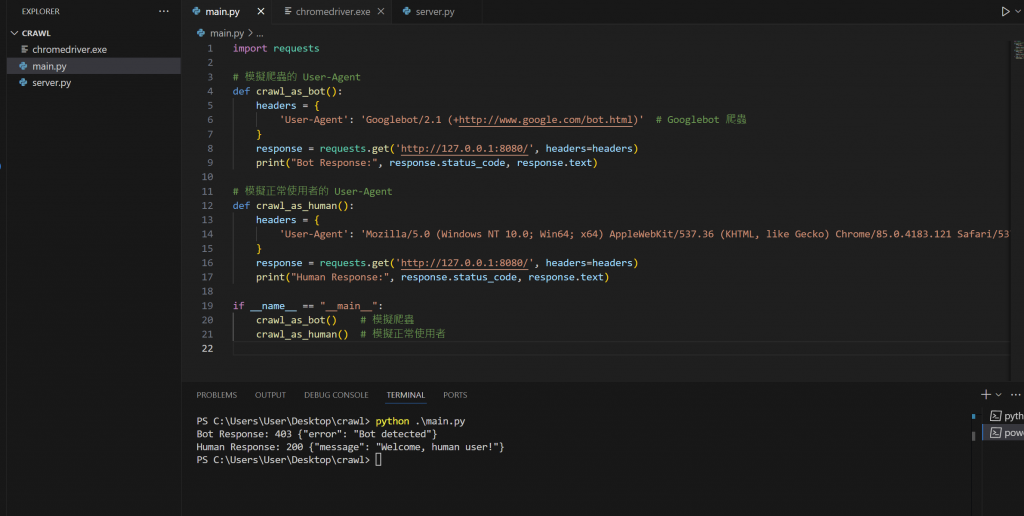
大家可以看到
headers = {
'User-Agent': 'Googlebot/2.1 (+http://www.google.com/bot.html)' # Googlebot 爬蟲
}
兩個function的差別可以簡易模擬有沒有使用chrome的標示展示~ 這個也是簡單反爬蟲的範例喔
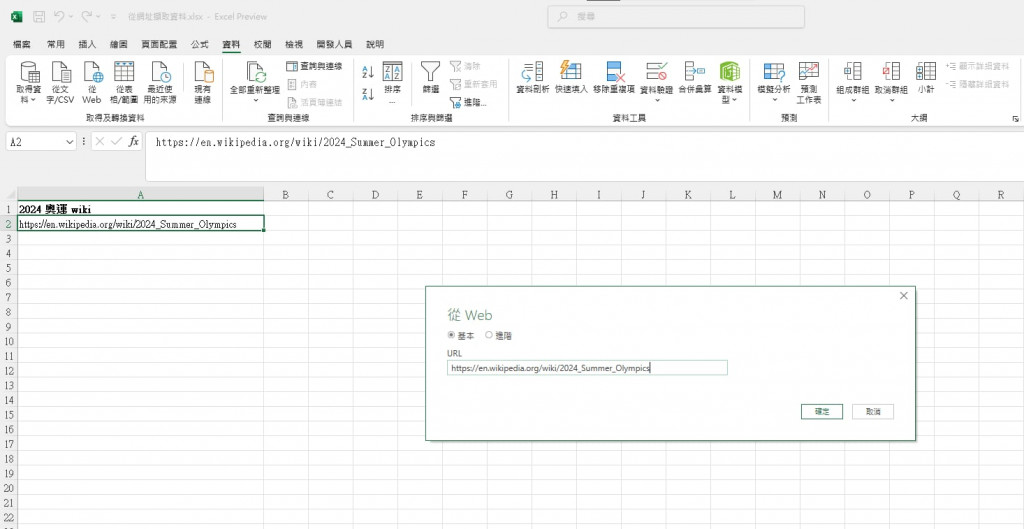
微軟教學
其實這是在查詢資料無意間找到的
可以跟大家分享
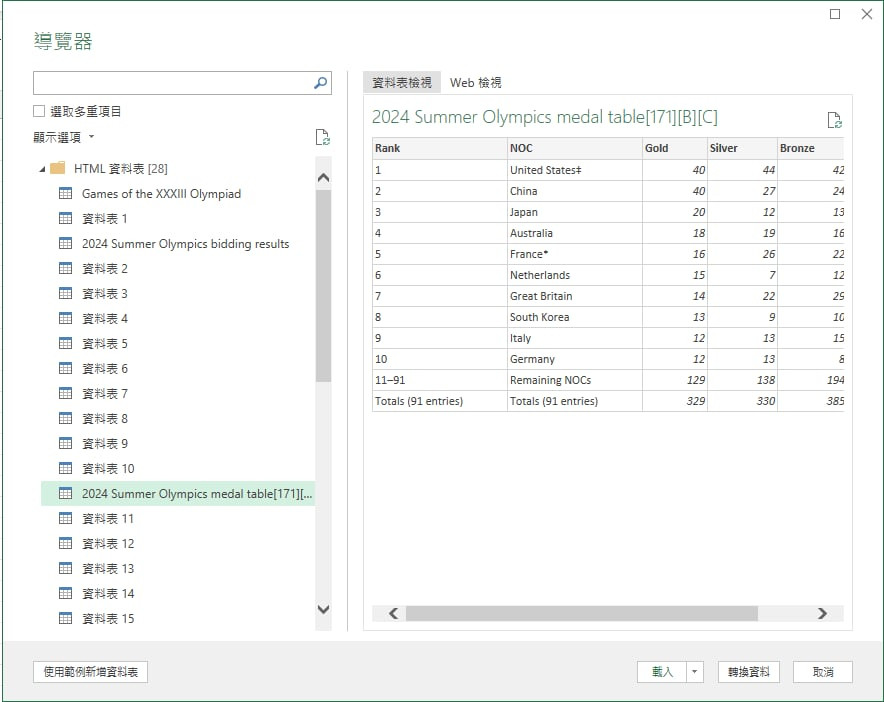
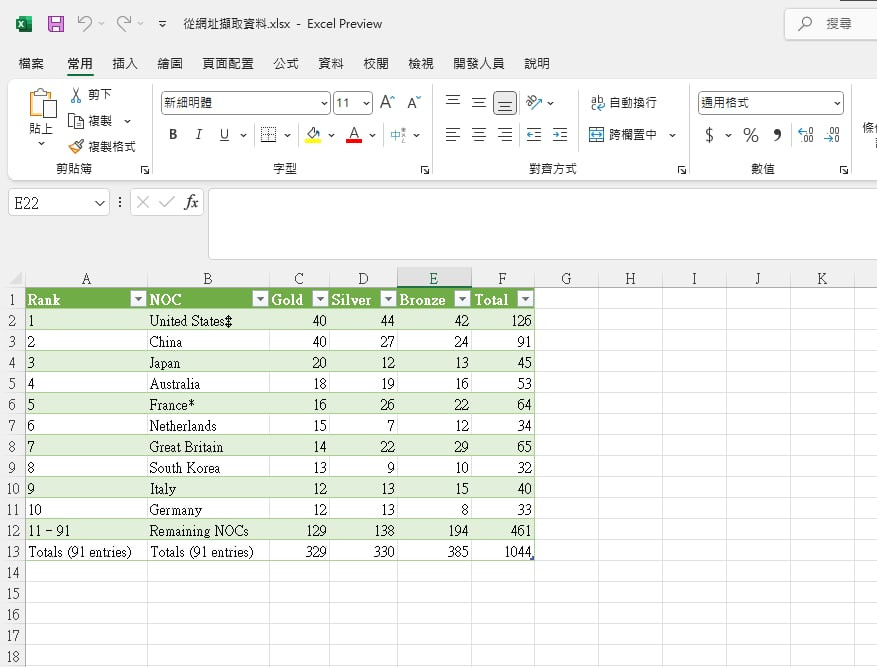
這個是excel O365 或是office 2016以上的版本
這個是我從奧運網站上輸入透過內建的Power query功能擷取的表格
快速又方便
雖然沒有到爬片許多網站
但是相信各位對爬蟲也有一定程度的了解了
我比較是希望一個引路人的方式帶大家突破門檻~
而非貼身保鑣
進入到該技術會用到的基本知識
跟可能需要突破的點
都會盡量幫大家補上
並且提到一些工程師的小技巧、工具跟心法給大家
基本上就是
1.拆解需求
2.查詢相關的套件
3.模擬人類的操作(user-agent、Selenium)
接者再透過正規表達式
或是資料清理方式處理就好搂~!!
下周開始進入web章節

