Qdrant 除了可以地端自架,也有雲端 SaaS 的免費版本。一般建議除了有自架的需求之外,使用 SaaS 版本會是最省事的。用戶只需要註冊並開始使用,不需處理硬體部署、操作系統更新或資料庫備份等繁瑣的技術性任務。我們今天就來註冊一個 SaaS 的 Qdrant 吧。
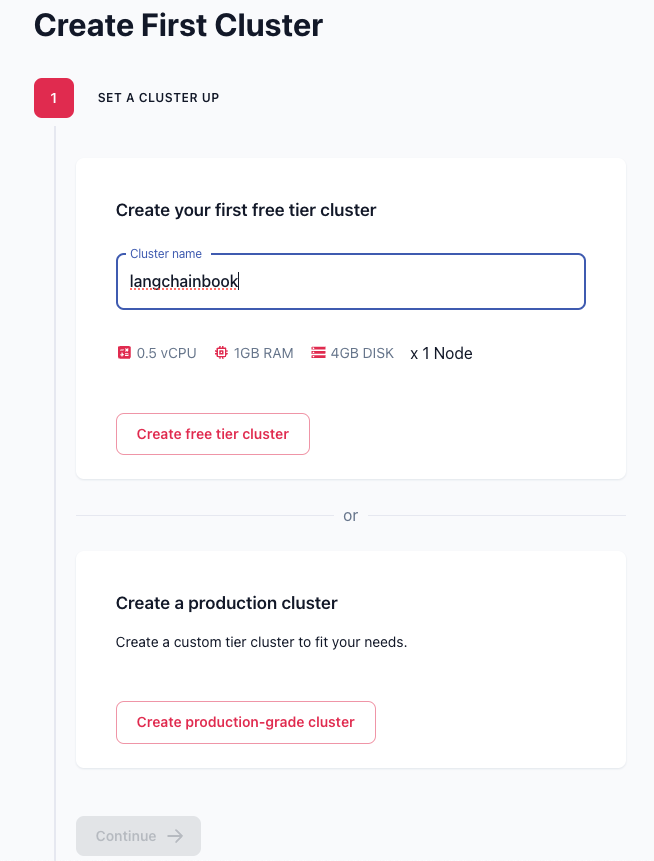
等待一下就會出現創建成功的畫面,接著點擊Continue。如下圖。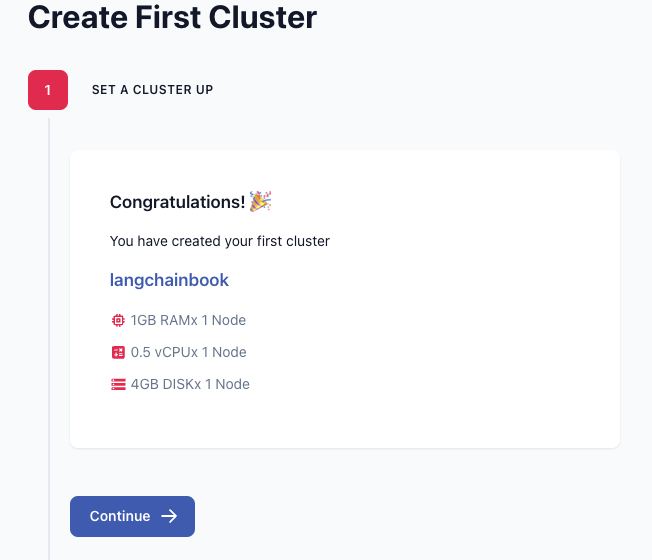
接著會要取得你的 API key,要注意不會再出現第二次了,要立刻存下來。如下圖所示。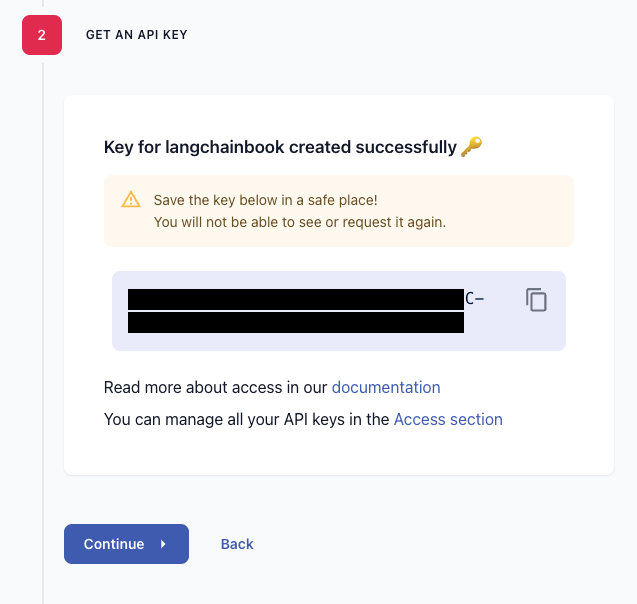
接著我們就來寫程式吧!
我們先安裝 qdrant-client,使用指令 poetry add qdrant-client ,然後把下面的程式碼複製貼上。
from qdrant_client import QdrantClient, models
import requests
import json
import uuid
qdrant_url = "YOUR_QDRANT_SAAS_URL"
qdrant_api_key = "YOUR_API_KEY"
qclient = QdrantClient(url=qdrant_url, api_key=qdrant_api_key)
cohere_embed_url = "https://Cohere-embed-v3-multilingual-yqv.westus3.models.ai.azure.com/embeddings"
headers = {
"Authorization": "Bearer xx",
"Content-Type": "application/json"
}
data = {
"input": [
"大家好"
]
}
response = requests.post(cohere_embed_url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
response_data = response.json()
# Extract the embedding vector from the response
embedding_vector = response_data['data'][0]['embedding']
print("Embedding Vector:", len(embedding_vector))
else:
print("Error:", response.status_code, response.text)
if not qclient.collection_exists(collection_name="ironman2024"):
qclient.create_collection(
collection_name="ironman2024",
vectors_config=models.VectorParams(size=3, distance=models.Distance.COSINE),
)
print("Not exisit, collection created")
qclient.upsert(
collection_name="ironman2024",
points=[
models.PointStruct(
id=uuid.uuid4().hex,
payload={
"text": data["input"][0],
},
vector=embedding_vector,
),
],
)
這段程式碼首先引入了所需的套件。QdrantClient 用於與 Qdrant,requests 用於發送 HTTP 請求,json 用於處理 JSON 數據,uuid 用於生成唯一的 ID。
qdrant_url 和 qdrant_api_key 是 Qdrant SaaS 的 URL 和 API key。接著,通過 QdrantClient 創建了一個 Qdrant 的 client,用於後續操作。
接著我們向前幾天部署好的 Cohere API 發送一個 POST 請求。Cohere API 的 URL 是 cohere_embed_url,並通過 headers 提供必要的身份驗證(Bearer xx)。請求的資料用「大家好」 作為輸入文本,Cohere API 將生成這段文本的 embedding。
這我們檢查請求是否成功(狀態碼為 200)。如果成功,它會從 response 裡取出 embedding向量並印出來。
接著我們建立 collection。這部分程式碼檢查名為 ironman2024 的 collection 是否已經存在。如果該 collection 不存在,則創建一個新的 collection。vectors_config 中定義了向量的大小和距離計算的方式。注意這裡要根據你所使用的 embedding model 來決定向量大小,例如我們用 Cohere-embed-v 3-multilingual,那就是 1024。
最後,我們將文本及其對應的 embedding 向量上傳到 Qdrant 資料庫中。使用 upsert 方法來插入資料點,每個資料點有唯一的 ID(uuid.uuid4().hex),並包括一個 payload(原始文本就要放在 payload 裡),以及生成的 embedding_vector。這樣,文本和向量就會被儲存在 Qdrant 中,後續可以進行相似度查詢。
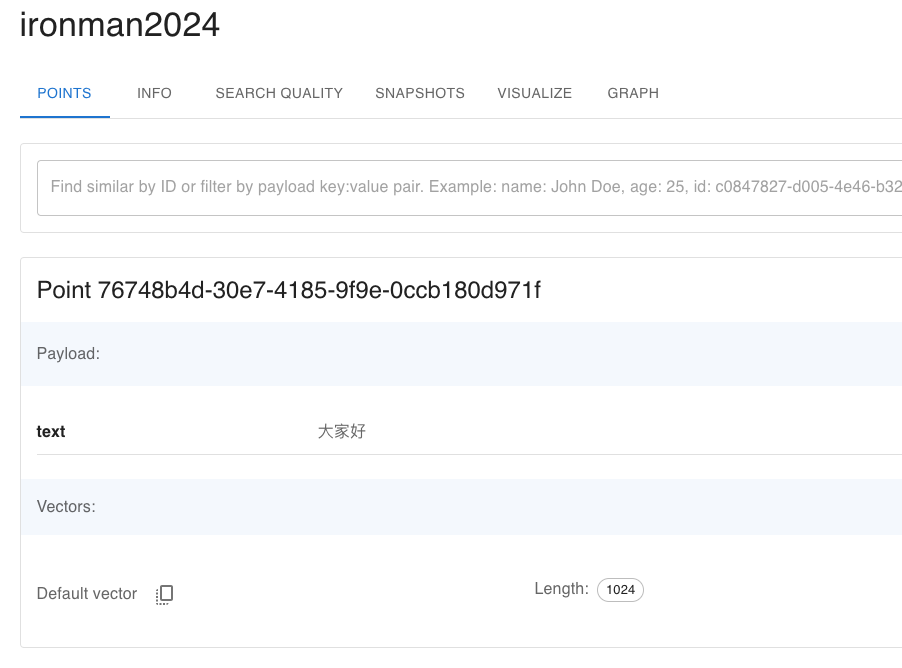
好的,明天我們就來把前幾天的產品資料,通通整合到向量資料庫裡吧!


 iThome鐵人賽
iThome鐵人賽