今天我們就來整理產品資料,而且我們要整理成 LangChain Document 的通用格式,然後儲存到向量資料庫之中。
[
{"品名": "ResiMax RM1001", "介紹": "RM1001是電阻器,具有高精度和穩定性,非常適合精密電路設計。"},
{"品名": "CapacitorPro CP2205", "介紹": "CP2205是電容器,具有極低的等效串聯電阻(ESR),適合高頻濾波應用。"},
{"品名": "TransiTech TT500N", "介紹": "TT500N是一款晶體管,具有高增益和快速切換特性,適合開關電源設計。"},
{"品名": "InduMax IM300", "介紹": "IM300是一款電感器,具有高穩定性的自諧振頻率,適合高精度濾波應用。"},
{"品名": "DiodeX DX100S", "介紹": "DX100S是一款蕭特基二極體,具有低正向壓降和快速反向恢復,適合高效能電源設計。"},
{"品名": "InduMax IM450Q", "介紹": "IM450Q是一款電感器,具有極高的Q值,非常適合射頻濾波器和振盪器設計。"},
{"品名": "PowerGuard PG500", "介紹": "PG500是一款電源穩壓器,具有寬廣的輸入電壓範圍和高穩壓精度,適合各類電子設備。"},
{"品名": "CMOSPro CP3000", "介紹": "CP3000是一款基於CMOS技術的晶片,具有低功耗和高集成度,適合數位電路設計。"},
{"品名": "MicroBoard MB1000", "介紹": "MB1000是一款微控制器,具備多種接口和擴展功能,適合快速開發和測試各類嵌入式應用,用於嵌入式系統和原型設計。"}
]
然後因為 LangChain 還沒有針對 Azure ML 的 embedding model 的 serverless endpoint 做整合,那麼就自己寫一個吧!我還發了 PR 給 LangChain,看看他們要不要 merge。 https://github.com/langchain-ai/langchain/pull/27148
我們可以用上次 Day 11 的手法,從我的 GitHub repo 裡來抓,也可以直接在專案裡新增一個 azure_ml_embeddings.py 檔案,貼上下面的程式碼:
import json
import os
from typing import Any, List, Optional
from langchain_core.embeddings import Embeddings
from langchain_core.utils import from_env
from pydantic import BaseModel, ConfigDict, Field, model_validator
from typing_extensions import Self
import requests
import asyncio
import aiohttp
DEFAULT_MODEL = "Cohere-embed-v3-multilingual"
class AzureMLEndpointEmbeddings(BaseModel, Embeddings):
"""Azure ML embedding endpoint for embeddings.
To use, set up Azure ML API endpoint and provide the endpoint URL and API key.
Example:
.. code-block:: python
from my_module import AzureMLEndpointEmbeddings
azure_ml = AzureMLEndpointEmbeddings(
embed_url="https://Cohere-embed-v3-multilingual.azure.com/embeddings",
api_key="your-api-key"
)
"""
client: Any = None #: :meta private:
async_client: Any = None #: :meta private:
embed_url: Optional[str] = None
"""Azure ML endpoint URL to use for embedding."""
api_key: Optional[str] = Field(
default_factory=from_env("AZURE_ML_API_KEY", default=None)
)
"""API Key to use for authentication."""
model_kwargs: Optional[dict] = None
"""Keyword arguments to pass to the embedding API."""
model_config = ConfigDict(
extra="forbid",
protected_namespaces=(),
)
@model_validator(mode="after")
def validate_environment(self) -> Self:
"""Validate that api key exists in environment."""
if not self.api_key:
self.api_key = os.getenv("AZURE_ML_API_KEY")
if not self.api_key:
raise ValueError("API Key must be provided or set in the environment.")
if not self.embed_url:
raise ValueError("Azure ML endpoint URL must be provided.")
return self
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Call Azure ML embedding endpoint to embed documents.
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
texts = [text.replace("\n", " ") for text in texts]
data = {
"input": texts
}
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
response = requests.post(self.embed_url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
response_data = response.json()
embeddings = [item['embedding'] for item in response_data['data']]
return embeddings
else:
raise Exception(f"Error: {response.status_code}, {response.text}")
async def aembed_documents(self, texts: List[str]) -> List[List[float]]:
"""Async Call to Azure ML embedding endpoint to embed documents.
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
texts = [text.replace("\n", " ") for text in texts]
data = {
"input": texts
}
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
async with aiohttp.ClientSession() as session:
async with session.post(self.embed_url, headers=headers, json=data) as response:
if response.status == 200:
response_data = await response.json()
embeddings = [item['embedding'] for item in response_data['data']]
return embeddings
else:
response_text = await response.text()
raise Exception(f"Error: {response.status}, {response_text}")
def embed_query(self, text: str) -> List[float]:
"""Call Azure ML embedding endpoint to embed a single query text.
Args:
text: The text to embed.
Returns:
Embeddings for the text.
"""
response = self.embed_documents([text])[0]
return response
async def aembed_query(self, text: str) -> List[float]:
"""Async Call to Azure ML embedding endpoint to embed a single query text.
Args:
text: The text to embed.
Returns:
Embeddings for the text.
"""
response = (await self.aembed_documents([text]))[0]
return response
day23.py 裡,貼上下面的程式碼並運作。from langchain_community.vectorstores import Qdrant
from langchain_core.documents import Document
from azure_ml_embeddings import AzureMLEndpointEmbeddings
cohere_embed_api_key = "xx"
cohere_embed_url = "https://Cohere-embed-v3-multilingual-yqv.westus3.models.ai.azure.com/embeddings"
qdrant_url = "https://xx.cloud.qdrant.io:6333"
qdrant_api_key = "xx"
products = [
{"品名": "ResiMax RM1001", "介紹": "RM1001是電阻器,具有高精度和穩定性,非常適合精密電路設計。"},
{"品名": "CapacitorPro CP2205", "介紹": "CP2205是電容器,具有極低的等效串聯電阻(ESR),適合高頻濾波應用。"},
{"品名": "TransiTech TT500N", "介紹": "TT500N是一款晶體管,具有高增益和快速切換特性,適合開關電源設計。"},
{"品名": "InduMax IM300", "介紹": "IM300是一款電感器,具有高穩定性的自諧振頻率,適合高精度濾波應用。"},
{"品名": "DiodeX DX100S", "介紹": "DX100S是一款蕭特基二極體,具有低正向壓降和快速反向恢復,適合高效能電源設計。"},
{"品名": "InduMax IM450Q", "介紹": "IM450Q是一款電感器,具有極高的Q值,非常適合射頻濾波器和振盪器設計。"},
{"品名": "PowerGuard PG500", "介紹": "PG500是一款電源穩壓器,具有寬廣的輸入電壓範圍和高穩壓精度,適合各類電子設備。"},
{"品名": "CMOSPro CP3000", "介紹": "CP3000是一款基於CMOS技術的晶片,具有低功耗和高集成度,適合數位電路設計。"},
{"品名": "MicroBoard MB1000", "介紹": "MB1000是一款微控制器,具備多種接口和擴展功能,適合快速開發和測試各類嵌入式應用,用於嵌入式系統和原型設計。"}
]
docs = []
for product in products:
page_content = f"電子零件 - {product['品名'].split()[1]}\n型號: {product['品名']}\n功能: {product['介紹']}\n"
doc = Document(
page_content=page_content,
metadata={
"department": "electronic",
"source": "產品型錄.pdf"
}
)
docs.append(doc)
embeddings_model = AzureMLEndpointEmbeddings(embed_url=cohere_embed_url, api_key=cohere_embed_api_key)
qdrant = Qdrant.from_documents(
docs,
embeddings_model,
url=qdrant_url,
api_key=qdrant_api_key,
collection_name="ironman2024",
force_recreate=True,
)
然後,我們到 Qdrant 的 Dashboard 裡,就可以看到我們把產品型錄給放進來了。如下圖所示。
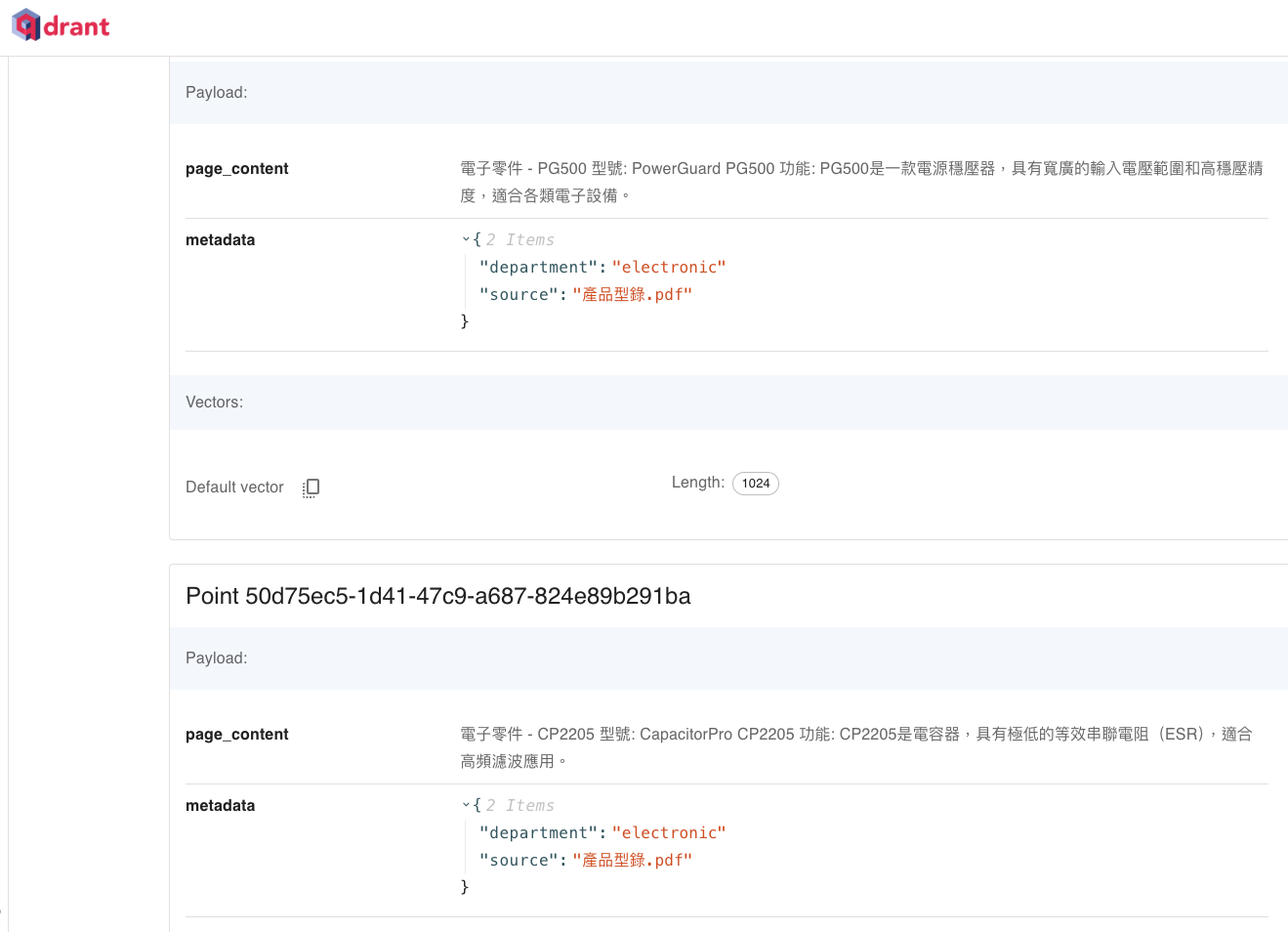
明天我們就來用這個產品型錄做 RAG 吧!


 iThome鐵人賽
iThome鐵人賽