
昨天介紹的是把爬蟲下來的資料,轉換成適合 LLM 讀取的資料格式,今天要介紹的是利用 LLM 簡化爬蟲這件事,會用到 skyvern 和 Scrapegraph-ai 這兩個工具
Skyvern 利用大型語言模型和電腦視覺自動化基於瀏覽器的工作流程。提供了一個簡單的 API 端點,可以完全自動化大量網站上的手動工作流程,取代了脆弱或不可靠的自動化解決方案。過去我們要使用 selenium 的工作都可以透過 skyvern 完成!

可以使用 Open Source 或者雲端方案是 Pricing
目前雲端方案每爬一頁是 0.1 美金,這邊我們自己用 docker 架服務即可 (需要提供 LLM 供應商 API key)
從 Github 上複製下來
git clone https://github.com/Skyvern-AI/skyvern.git
cd skyvern
修改 docker-compose.yaml 中的 API key,看你想要用哪一家 LLM 供應商,目前有 OpenAI, Anthropic, Azure
environment:
- DATABASE_STRING=postgresql+psycopg://skyvern:skyvern@postgres:5432/skyvern
- BROWSER_TYPE=chromium-headful
- ENABLE_OPENAI=true
- OPENAI_API_KEY=<這邊放你的 key>
使用 docker 啟動,服務會 run 在 8080 port
docker compose up -d

非常簡單,直接告訴 skyvern 你要做什麼即可。這邊一樣用昨天住宿服務組的活動網站為例

然後 LLM 就會開始「思考」要採取哪些動作,回傳結果,從沒想過爬蟲可以如此簡單 🥳🥳

甚至可以看到爬蟲的過程、提取的參數等等

這邊我們讓模型做更細節的操作,也就是針對每個活動爬取內容,以下是我的 prompt
幫我把 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw 上的活動爬下來,包含活動的詳細資訊,點擊可以查看詳細資訊,把每個活動的詳細內容也爬下來
結果如下,雖然是有抓到啦...但... 600 歲是什麼啦XD,而且他只有爬到一筆資料

原來是因為原本的圖片有「需 600 字」

來修復它只爬取一筆資料的缺點,將 prompt 寫得更明確,把剛剛第一次爬到的標題都附上,然後寫成以下的 prompt
針對將以下活動的資訊爬出來,網址為 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
2024勝利校區地震避難疏散演練活動
2024 肌動一下-綜合肌力有氧訓練(勝利舍區)
93校慶:捐輸幸福-捐血活動(摸彩結果將更新於此)
分離術捐血活動 (113/3/25-114/12/31)"
113-1 光一舍廚藝教室活動
居然給我爬到空的QQ

或許,我們該嘗試更直白的 prompt
從成大住宿服務組上找到最新的五個活動,以及各自的詳細內容

還是失敗了哇啊啊啊
回到上上個任務 (600 歲那個),點選 rerun task,然後在這邊設定 prompt

這邊我強調了兩點
**ALL** 來強調所有頁面都要爬到{"data": "content of page"}
然後觀察執行紀錄,會發現他在點擊第一個活動連結之後,就沒有按下返回,直接想要點第二個連結

我們再次修改 prompt
針對將以下活動的資訊爬出來,網址為 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
點擊 -> [2024勝利校區地震避難疏散演練活動 -> 取出內容] -> 按下返回
點擊 -> [2024 肌動一下-綜合肌力有氧訓練(勝利舍區)] -> 取出內容 -> 按下返回
點擊 -> [93校慶:捐輸幸福-捐血活動(摸彩結果將更新於此)] -> 取出內容 -> 按下返回
點擊 -> [分離術捐血活動 (113/3/25-114/12/31)] -> 取出內容 -> 按下返回
點擊 -> [113-1 光一舍廚藝教室活動] -> 取出內容 -> 按下返回
這邊又出現一個問題,就是 LLM 把「返回」當成「回首頁了」

所以這次我們在微調一下 Prompt
針對將以下活動的資訊爬出來,網址為 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
點擊 -> [2024勝利校區地震避難疏散演練活動 -> 取出內容] -> 回到 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
點擊 -> [2024 肌動一下-綜合肌力有氧訓練(勝利舍區)] -> 取出內容 -> 回到 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
點擊 -> [93校慶:捐輸幸福-捐血活動(摸彩結果將更新於此)] -> 取出內容 -> 回到 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
點擊 -> [分離術捐血活動 (113/3/25-114/12/31)] -> 取出內容 -> 回到 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
點擊 -> [113-1 光一舍廚藝教室活動] -> 取出內容 -> 回到 https://housing-osa.ncku.edu.tw/p/403-1052-407-1.php?Lang=zh-tw
即使改了如此詳細,他還是只有爬到一篇文QQ,所以我在猜應該是成大的網站 url、和網站設定實在太不直覺了 (也可能是要反爬蟲),於是我決定用我的網站

爬取海狸大師最新的五篇文章
他給我找到 beavermaster.com ((??

換一個 Prompt
爬取 yenslife.top 最新的五篇文章
網頁對了,但是沒有爬到文章...

小結:待加強,不過也可能是中文的網站對這種英文 prompt based 的爬蟲工具不友善。他其實還有工作流的功能,但這邊就不深入探討了,畢竟我不是什麼爬蟲高手X)
Skyvern 也有工作流可以使用,不過他就不像 Dify 那麼滑順了

ScrapeGraphAI 是一個開源的 Python 函式庫,結合大型語言模型(LLMs)和圖結構來自動化網站或其他文件的資料爬蟲。傳統的網頁爬蟲工具通常依賴固定的結構,但 ScrapeGraphAI 利用 LLM 的靈活性來適應網站結構變更,減少開發者手動維護的需求。
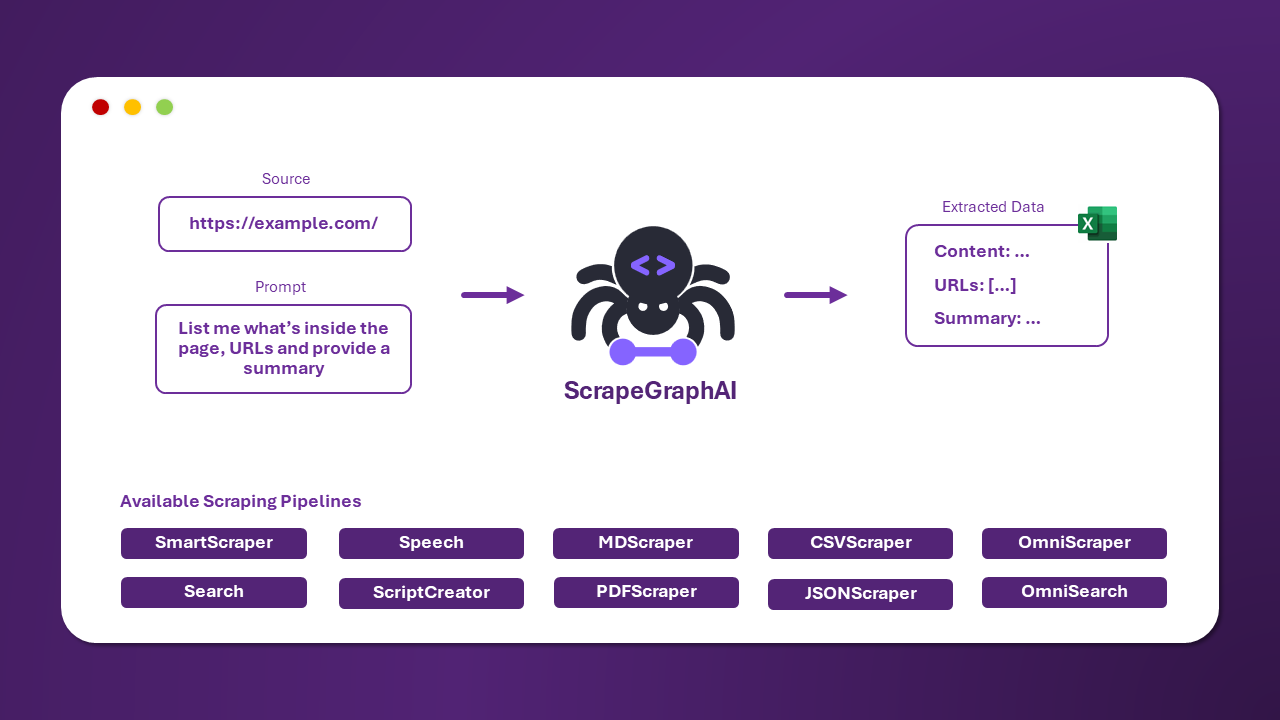
以下是一些 Scrapegraph 提供的 pipeline,有 Omni 開頭的是專們給 OpenAI o 系列的模型使用
| Pipeline 名稱 | 描述 |
|---|---|
| SmartScraperGraph | 單頁爬蟲,只需使用者提示和輸入來源。 |
| SearchGraph | 多頁爬蟲,從搜尋引擎的前 n 個搜尋結果中爬出資料。 |
| SpeechGraph | 單頁爬蟲,從網站爬出信息並生成音訊檔案。 |
| ScriptCreatorGraph | 單頁爬蟲,從網站爬出信息並生成 Python 腳本。 |
| SmartScraperMultiGraph | 多頁爬蟲,根據單一提示和多個來源提取多個頁面的資料。 |
| ScriptCreatorMultiGraph | 多頁爬蟲,生成 Python 腳本以提取多個頁面和來源的信息。 |
| OmniScraperGraph | 與 SmartScraperGraph 相似,但具備爬取圖像並進行描述的能力。 |
| OmniSearchGraph | 與 SearchGraph 相似,但具備爬取圖像並進行描述的能力。 |
官網文件對於各種 pipeline 的串接方法都有很漂亮的介紹,有興趣的在自己看吧!

pip install scrapegraphai
playwright install
這邊用 SearchGraph 單純找活動名稱和網站 (其實這樣就很夠),至這邊嵌入模型也可以不同供應商混搭著用 (一樣記得要去設定 .env 檔案歐)
from scrapegraphai.graphs import SearchGraph
from dotenv import load_dotenv
import os
load_dotenv()
graph_config = {
"llm": {
"api_key": os.getenv("OPENAI_API_KEY"),
"model": "openai/gpt-4o-mini",
},
"embedding": {
"api_key": os.getenv("OPENAI_API_KEY"),
"model": "text-embedding-3-small",
}
}
search_graph = SearchGraph(
prompt="找到最新的五個成大住宿服務組辦的活動",
config=graph_config,
)
result = search_graph.run()
print(result)
結果如下
{
"latest_events":[
{
"title":"2024 肌動一下-綜合肌力有氧訓練(勝利舍區)",
"date":"2024-10-04",
"link":"https://housing-osa.ncku.edu.tw/p/406-1052-273737,r407.php?Lang=zh-tw"
},
{
"title":"93校慶:捐輸幸福-捐血活動(摸彩結果將更新於此)",
"date":"2024-09-24",
"link":"https://housing-osa.ncku.edu.tw/p/406-1052-273384,r407.php?Lang=zh-tw"
},
{
"title":"分離術捐血活動 (113/3/25-114/12/31)",
"date":"2024-03-26",
"link":"https://housing-osa.ncku.edu.tw/p/406-1052-265993,r407.php?Lang=zh-tw"
},
{
"title":"113-1 光一舍廚藝教室活動",
"date":"2024-09-24",
"link":"https://housing-osa.ncku.edu.tw/p/406-1052-273381,r407.php?Lang=zh-tw"
},
{
"title":"國際美食烹飪比賽",
"date":"NA",
"link":"NA"
}
],
"sources":[
"https://housing-osa.ncku.edu.tw/",
"https://housing-osa.ncku.edu.tw/p/412-1052-18885.php?Lang=zh-tw",
"https://housing-osa.ncku.edu.tw/p/412-1052-6854.php?Lang=zh-tw"
]
}
用 LLM 幫忙爬蟲固然方便,但感覺要變成一個產品還有一段路要走,就和所有生成式 AI 的產品一樣,都是一種機率軟體,要做到很穩定還很困難,像是我今天嘗試的 skyvern 就給我很差的印象,但也可能是因為我不太會用,畢竟我就不是什麼爬蟲高手,真正的爬蟲高手是我認識的一個大佬 Vincent55 也是資安大師。講到資安,剩下幾天來寫一些關於 Prompt Injection 以及 LLM 的安全相關的內容好了,期待一下吧~

 iThome鐵人賽
iThome鐵人賽