今天一樣不聊功能,改聊一個自架 GitLab 時,大家會想要了解的事情,那就是到底如何評估我需要多少資源來架設 GitLab?
咦,這個題目不是原廠文件上都寫好了嗎?怎麼還要自己評估?確實原廠文件上已經提供了數組建議的架構與規格,讓我們可以直接參考,但原廠又是怎麼做出那樣的評估的呢?
答案就是今天要介紹的工具 GPT!
咦,GitLab 也有自己的 GPT 模型嗎?並不是喔,這個 GPT 是 GitLab Performance Tool 的縮寫啦!(喂~)
GitLab Performance Tool 顧名思義,大家應該一眼就能看出它的用途,但我們今天還不會介紹到它,而是先介紹 GPT 的附屬工具——GPT Data Generator。
畢竟是要測試 GitLab Server 的效能,為了完整的模擬,你的 GitLab 上當然要有一些假資料,有著一定數量的 Group 與 Project,而且 Project 內最好還要有一定的資料量,才比較像一個真實的 Project。
因此在使用 GPT 之前,你會需要先透過 GPT Data Generator 來幫助你產出大量的假資料。
下面我們就來試著使用看看 GPT Data Generator。
首先你當然要先架設一座 GitLab,這一步我就不解釋了,但提醒大家可以的話多給一點資源,不然你可能光是跑 GPT Data Generator 就已經先把你的 GitLab Server 打掛了。
利用具備 GitLab Admin 權限的 User 產生 Access token。怎麼產生 Access token 這也直接跳過嘍,大家應該都很熟悉,只要進到 URL /user_settings/personal_access_tokens 即可產出 Access token。
建立一個產假資料用的 .json,在該檔案中我們需要設定假資料要放在哪裡,以及要產出多少假資料。
如下面的範例,其中比較重要的是 gpt_data 底下的內容。
large_projects 用來設定第一種假資料,這會用來匯入含有大量 Project 內容的假資料。
many_groups_and_projects 是第二種假資料,會用來產出大量的 Sub Group 與 Project。位於 many_groups_and_projects 之下的 subgroups 及 projects 即用來控制你要產出多少個 sub group 及 project,要注意每一個 sub group 都會產出 project。因此如果 "subgroups": 10 搭配 "projects": 10,你就會得到 10*10=100 總共 100 個 Project。
{
"environment": {
"name": "自己取個名稱",
"url": "https://你的_GitLab_Server",
"user": "你的_user",
"config": {
"latency": "0"
},
"storage_nodes": ["default"]
},
"gpt_data": {
"root_group": "替假資料的root group 取一個名字",
"large_projects": {
"group": "替假資料的 Sub Group 取一個名字",
"project": "替假資料的 Project name 取一個前綴字"
},
"many_groups_and_projects": {
"group": "替假資料的 Sub Group 取一個名字",
"subgroups": 100,
"subgroup_prefix": "替假資料的 Sub Sub Group 取一個前綴字",
"projects": 10,
"project_prefix": "替假資料的 Project name 取一個前綴字"
}
}
}
建立執行 GPT Data Generator 所需的環境。請按著下面的範例,建立一個資料夾,將上一步準備好的 .json 放進去。
- gpt #資料夾
|_ config #資料夾
| |_ environments #資料夾
| |_ 你的.json
|_ results #資料夾
執行 GPT Data Generator。
感謝原廠,已經做好 docker image 可以直接使用,因此你只要在有 docker 的環境執行下面的指令即可。
如下範例,記得要將你準備好的資料夾用 -v 同步給 container 使用。
docker run -it \
-e ACCESS_TOKEN=你的_Access_token \
-v /gpt/config:/config \
-v /gpt/results:/results \
gitlab/gpt-data-generator \
--environment 你的.json
指令會需要跑一段時間,特別是如果你 subgroups 及 projects 的數字設定的有一點大,那可能你可以先去吃個飯再回來。
最後就附上幾張截圖,讓大家感受一下。
我設定 "subgroups": 1000 搭配 "projects": 10,你看看跑了 43 分鐘還沒跑完。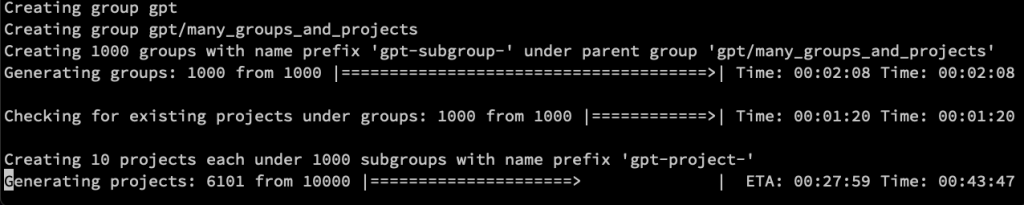
第二次學乖了,這次用 "subgroups": 10 搭配 "projects": 10,一下子就跑完了。(但這樣我後續就沒有大量 Project 可以用來測試效能了)
在過程中,會匯入一個有大量資料的 Project,因為 size 有點大,因此 GPT Data Generator 還會先幫你修改 GitLab Environment max_import_size 避免無法匯入。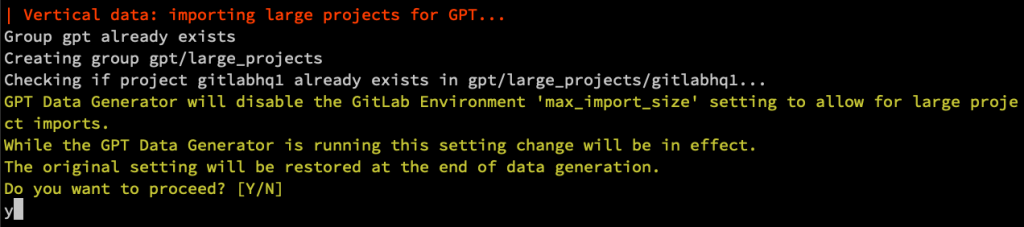
這個 Large Project 真的要花很多時間才能匯入,原廠甚至提醒你,如果超過 2 小時還沒完成匯入的動作,那你可能要先對環境除錯一下。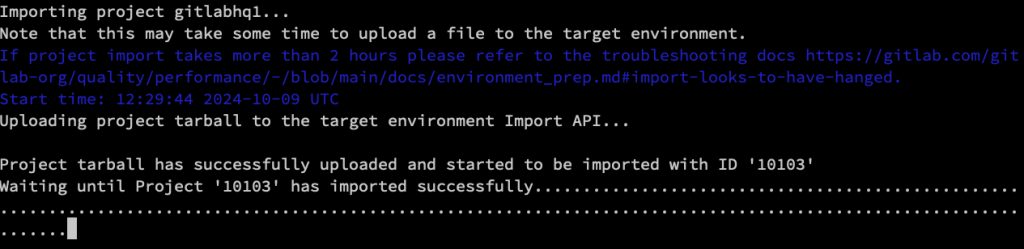
光是產假資料,我的 Server CPU 與 RAM 就開始狂飆了 Orz(VM 規格開太小)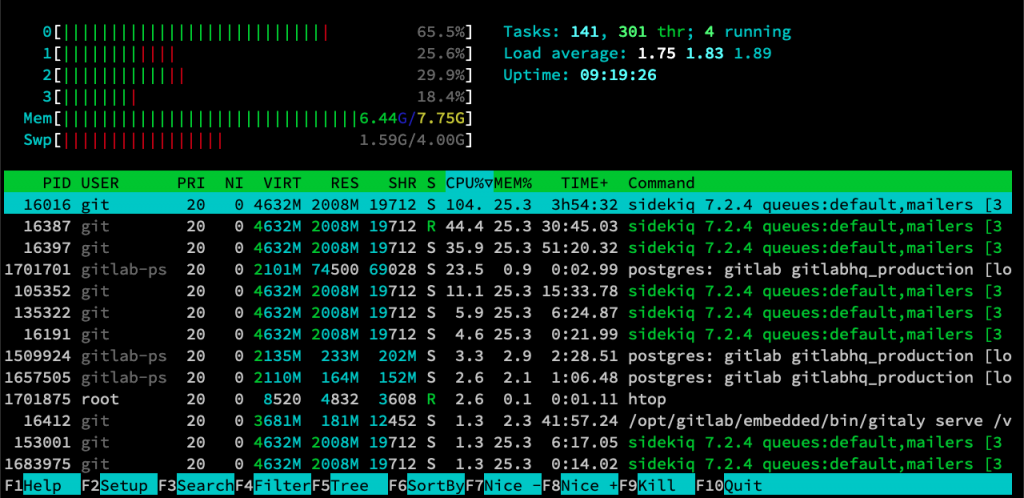
如果你重複執行 GPT Data Generator 會發生什麼事呢?這個工具很貼心,它會先幫你刪除舊的假資料,但如果你的 Sub Group 與 Project 數量很多,這個刪除也會跑很久喔!
假資料產生完畢,回到 Web UI 上查看,還真的是產出一堆。因為我跑了三次,每次都有改前綴字,所以才會有好幾個 root group。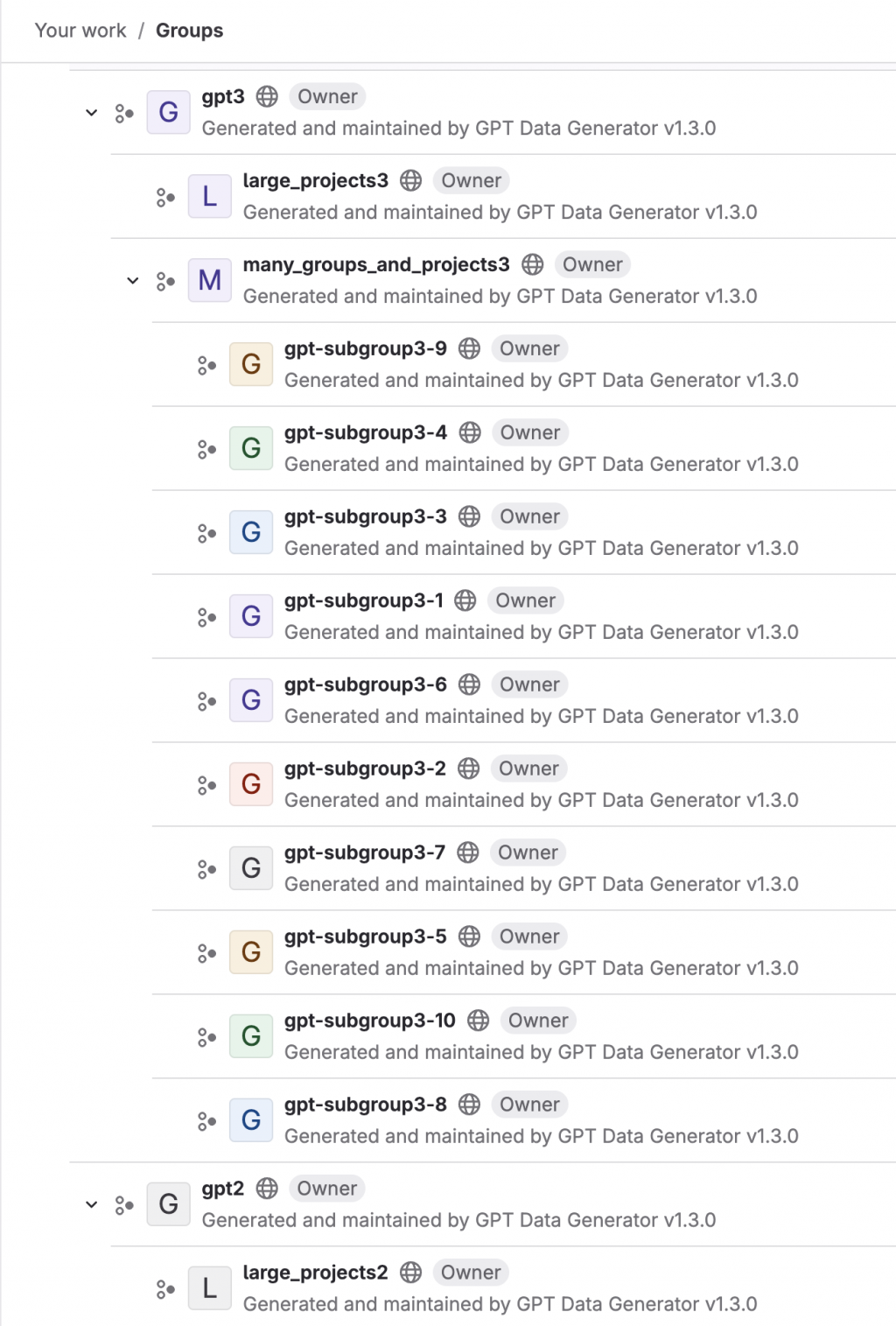
GPT Data Generator 真的是一個方便的好工具,特別是對我這種會需要建立 GitLab Demo 環境的人,以前我都自已傻傻的寫程式去打 GitLab API 來產出這些 Group 與 Project,沒想到原廠早就做出好用的工具了,以後就省事多了。如果你也跟我一樣有這方面的需求,務必要自己玩看看喔!

圖片來源 - 吉卜力工作室 https://www.ghibli.jp/works/tanuki/#&gid=1&pid=49

