在本系列的最後幾天,我們將收斂探索範圍,專注討論網卡驅動與 Linux 網路子系統。
在第 3 天的文章中,我們曾提到,透過 ip link list 列舉出來的,是 Linux Kernel 內部的 net_device 結構。這個 net_device 結構保存了一個網路設備的所有資訊,這是一個相當複雜的資料結構,光是這個結構體的定義就有 354 行。除了介面名稱等基本資訊外,它還包含了各種網路層相關的參數,並將不同的協定處理,如 MPLS、VLAN、IPv6 等,包裝在次級結構指標中。
// include/linux/netdevice.h
struct net_device {
char name[IFNAMSIZ];
int ifindex;
...
const struct net_device_ops *netdev_ops;
...
const struct ethtool_ops *ethtool_ops;
...
#if IS_ENABLED(CONFIG_VLAN_8021Q)
struct vlan_info __rcu *vlan_info;
#endif
...
#if IS_ENABLED(CONFIG_MPLS_ROUTING)
struct mpls_dev __rcu *mpls_ptr;
#endif
...
}
我們主要要了解的 net_device 是如何與底層驅動進行互動並處理封包的收發。從 net_device 結構體中的 netdev_ops 可以看到,這類似於在 VFS 中的 inode_operations。正如 VFS 使用 operations 對 API 進行抽象,net_device 也將網路設備的操作封裝成如 net_device_ops、ethtool_ops 等 API 群。當驅動程式建立新的 net_device 時,會填充這些 operations 結構來支援具體的操作。
// include/linux/netdevice.h
struct net_device_ops {
int (*ndo_init)(struct net_device *dev);
void (*ndo_uninit)(struct net_device *dev);
int (*ndo_open)(struct net_device *dev);
int (*ndo_stop)(struct net_device *dev);
netdev_tx_t (*ndo_start_xmit)(struct sk_buff *skb,
struct net_device *dev);
...
}
例如,從 net_device_ops 可以看出,ndo_open 和 ndo_stop 是用來處理透過 ip link set xxx up/down 的操作指令。驅動程式註冊的 handler 函數會接收這些請求,完成網路設備的開關操作。
當我們使用
ip link set up下達指令時,實際上會透過 netlink 與 rtnetlink 呼叫net_device_ops.ndo_open,然後進行網卡的開啟操作。由於時間有限,本系列文章將不進一步深入討論 netlink 及 rtnetlink,如果之後有機會,會在番外篇補充這些內容。
在 Linux Kernel 中,sk_buff 是核心的封包上下文結構,sk_buff 保存了單個封包的資訊。協定層之間在傳遞封包時,都會使用 sk_buff 作為參數。
// include/linux/skbuff.h
struct sk_buff {
...
__u8 pkt_type:3, // Packet class
ignore_df:1, // Allow local fragmentation
dst_pending_confirm:1, // Need to confirm neighbour
ip_summed:2, // Driver fed us an IP checksum
ooo_okay:1; // Allow the mapping of a socket to a queue to be changed
__u8 mono_delivery_time:1; // When set, skb->tstamp has the delivery_time in mono clock base (i.e. EDT)
#ifdef CONFIG_NET_XGRESS
__u8 tc_at_ingress:1, // Used within tc_classify to distinguish in/egress
tc_skip_classify:1; // Do not classify packet. Set by IFB device
#endif
__u8 remcsum_offload:1, // Remote checksum offload is enabled
csum_complete_sw:1, // Checksum was completed by software
csum_level:2, // Number of consecutive checksums found in the packet minus one
inner_protocol_type:1; // Inner protocol is ENCAP_TYPE_ETHER or ENCAP_TYPE_IPPROTO
...
}
不過,sk_buff 保存的只是封包的上下文資訊,實際的封包內容並不儲存在 sk_buff 中,而是透過多個指標指向真正儲存封包內容的資料區。
// include/linux/skbuff.h
typedef unsigned int sk_buff_data_t;
/**
* DOC: Basic sk_buff geometry
*
* struct sk_buff itself is a metadata structure and does not hold any packet
* data. All the data is held in associated buffers.
*
* &sk_buff.head points to the main "head" buffer. The head buffer is divided
* into two parts:
*
* - data buffer, containing headers and sometimes payload;
* this is the part of the skb operated on by the common helpers
* such as skb_put() or skb_pull();
* - shared info (struct skb_shared_info) which holds an array of pointers
* to read-only data in the (page, offset, length) format.
*
* Optionally &skb_shared_info.frag_list may point to another skb.
*
* Basic diagram may look like this::
*
* ---------------
* | sk_buff |
* ---------------
* ,--------------------------- + head
* / ,----------------- + data
* / / ,----------- + tail
* | | | , + end
* | | | |
* v v v v
* -----------------------------------------------
* | headroom | data | tailroom | skb_shared_info |
* -----------------------------------------------
* + [page frag]
* + [page frag]
* + [page frag]
* + [page frag] ---------
* + frag_list --> | sk_buff |
* ---------
*
*/
struct sk_buff {
...
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
...
}
在 sk_buff 中,會維護 head、data、tail 和 end 四個指標,這些指標分別指向封包資料區的不同部分。head 和 end 指向封包記憶體區塊的頭尾,而 data 和 tail 之間的區間保存了真實的封包內容。為了在協定層處理時可以方便地增加或減少封包頭(header),在 head 和 data 之間和tail跟end之間會留出 headroom 和 tailroom 的空間。這樣設計的好處是,當協定層需要增加 header 時,只需要調整 data 和 tail 指標即可,避免了重新分配更大塊的記憶體和資料搬遷的成本。
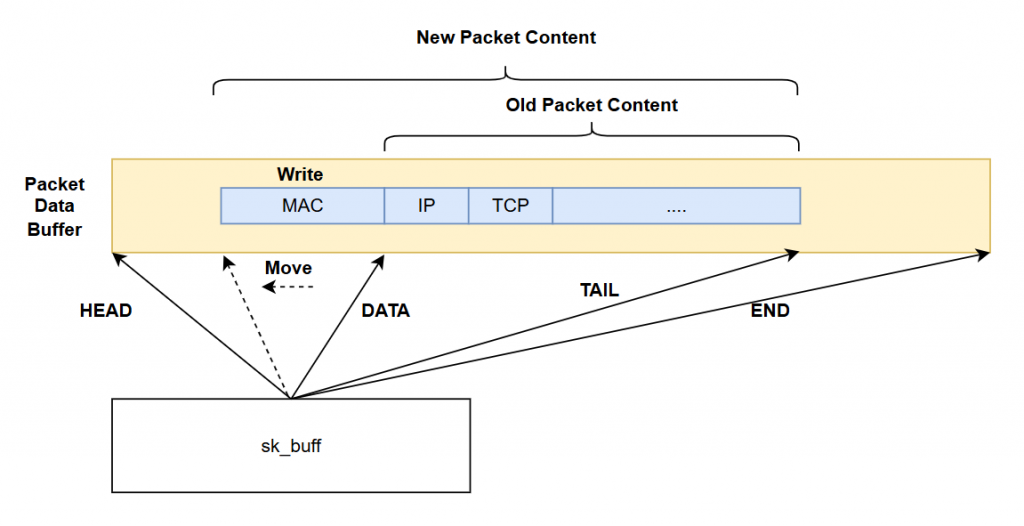
當上層協定處理完要發送的封包後,會呼叫 net_device 的 net_device_ops.ndo_start_xmit,並將 skb 作為參數,請求驅動程式發送封包。而在接收封包的部分,驅動程式完成封包接收後,會建立對應的 skb,然後呼叫網路子系統提供的函數,如 netif_receive_skb,將封包傳遞給網路子系統與協定堆疊進行處理。
透過這樣的設計,網路設備子系統作為一層抽象,將底層驅動程式與網卡設備隔離,讓上層的協定堆疊與應用程式能夠更容易地操作網路設備,實現封包的收發。


 iThome鐵人賽
iThome鐵人賽