在這個系列的尾聲,我們將探討 Linux 系統是如何接收封包的,我一樣會以 igb 網卡為例。
首先,當我們執行 ip link set eth0 up 這個命令時,會觸發網卡的 netdev_ops.ndo_open 函數,對於 Intel 的 IGB 驅動來說,這個函數對應的是 igb_open。
int igb_open(struct net_device *netdev)
{
return __igb_open(netdev, false);
}
static int __igb_open(struct net_device *netdev, bool resuming)
{
struct igb_adapter *adapter = netdev_priv(netdev);
struct e1000_hw *hw = &adapter->hw;
struct pci_dev *pdev = adapter->pdev;
...
/* 初始化 ring */
igb_setup_all_tx_resources(adapter);
igb_setup_all_rx_resources(adapter);
/* 物理上啟動網卡 */
igb_power_up_link(adapter);
/* 硬體相關配置 */
igb_configure(adapter);
/* 中斷配置 */
igb_request_irq(adapter);
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
igb_irq_enable(adapter);
...
/* 標記網卡允許發送封包 */
netif_tx_start_all_queues(netdev);
...
/* start the watchdog. */
/* 檢測線路連線狀態 */
hw->mac.get_link_status = 1;
schedule_work(&adapter->watchdog_task);
}
igb_open 主要負責配置作業系統和網卡之間傳輸封包的記憶體,並設置中斷。理解這些細節需要先瞭解作業系統與網卡之間如何進行封包傳輸。
現代網卡大多使用 DMA (Direct Memory Access) 技術來進行資料交換。傳統方式需要 CPU 介入,透過中斷通知接收封包並由 CPU 執行 IO 指令。
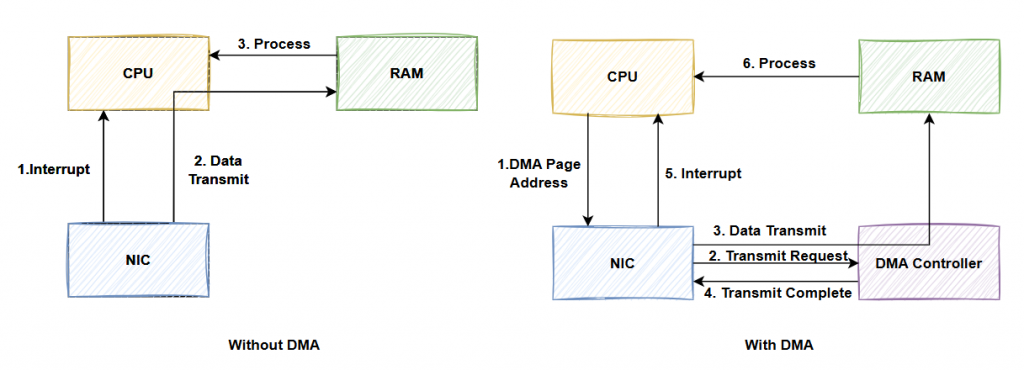
DMA 架構有一個獨立的 DMA 控制器,作業系統會將一個物理記憶體頁面標記為可進行 DMA 傳輸,並將該頁面的物理地址告知網卡。
當網卡接收到封包時,它會通知 DMA 控制器,後者將封包資料從網卡快取搬到記憶體中,完成後,網卡才會向 CPU 發送中斷通知,此時作業系統便可讀取封包。
當然,Linux Kernel 對 DMA 的操作進行了封裝,驅動程式只需呼叫 Kernel 提供的函數即可完成 DMA 頁面的分配與傳輸。詳細資訊可以參考 Dynamic DMA Mapping Guide。
接著,我們來看看 IGB 驅動在使用 DMA 模式下,如何與 Kernel 進行封包傳輸。
// drivers/net/ethernet/intel/igb/igb.h
struct igb_adapter {
struct net_device *netdev;
...
/* TX */
u16 tx_work_limit;
u32 tx_timeout_count;
int num_tx_queues;
struct igb_ring *tx_ring[16];
/* RX */
int num_rx_queues;
struct igb_ring *rx_ring[16];
...
}
首先,根據昨天的說明,在每一個網路設備 (net_device) 上,IGB 驅動都會建立一個 igb_adapter 來保存相關參數。該結構中有 16 個 tx_ring 和 rx_ring,每個 tx/rx_ring 是一個 igb_ring 資料結構,對應到邏輯上的傳輸對列。當然實際使用的隊列數會受硬體和配置影響,這邊就先不管。
static int __igb_open(struct net_device *netdev, bool resuming)
{
struct igb_adapter *adapter = netdev_priv(netdev);
...
/* 初始化 ring */
igb_setup_all_tx_resources(adapter);
igb_setup_all_rx_resources(adapter);
...
}
static int igb_setup_all_rx_resources(struct igb_adapter *adapter)
{
for (i = 0; i < adapter->num_rx_queues; i++) {
err = igb_setup_rx_resources(adapter->rx_ring[i]);
}
return err;
}
當執行 open 操作時,IGB 驅動會初始化每個隊列的 igb_ring 結構。
接下來的講解會對igb驅動的邏輯,做一定程度上的簡化,並不完全符合igb驅動的工作原理,主要差異是忽略了igb 驅動有 page reuse 機制來避免持續reallocate新的page。
IGB 的 igb_ring 是基於 ring buffer 的結構。ring buffer 是一個環狀資料結構,常見於 queueing 系統中。它具有兩個指標,一個指向下一個要讀取的位置 (next to read),另一個指向下一個要寫入的位置 (next to write)。
資料提供者 (producer) 會將資料寫入 next to write 指向的位置,並將指標移動到下一個位置。資料使用者 (consumer) 則從 next to read 讀取資料,並同樣移動指標。這個結構能夠在有限的空間內實現無限的讀寫操作。
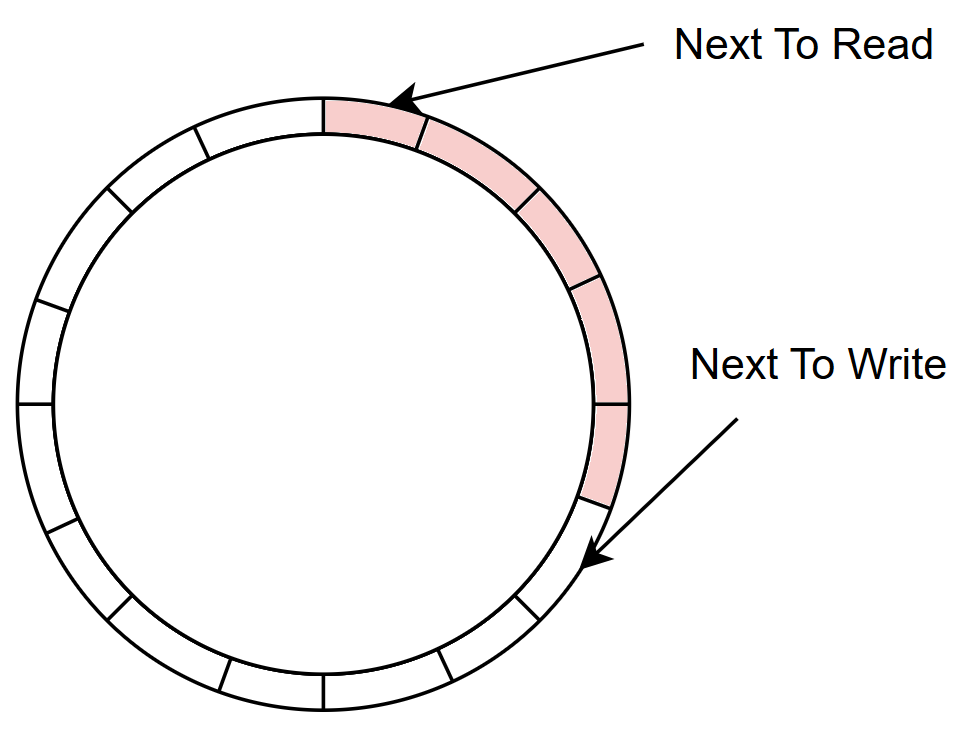
當 ring buffer 被填滿時,資料提供者需等待使用者清空一些空間。該結構通常用一個陣列和兩個索引變數來實現。
那網卡是怎麼使用 ring buffer 結構與 DMA 機制的呢?
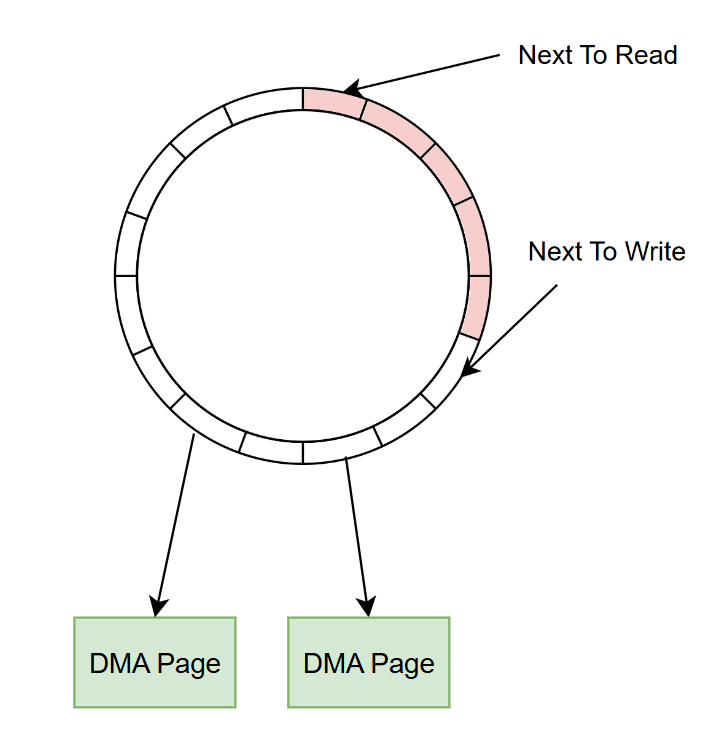
RX 模式下,網路卡是 ring buffer 的 producer,它會從 next to write 取得一個 DMA Page 地址,並將封包內容通過 DMA 寫入該記憶體中。驅動程式則是 consumer,當中斷發生時,驅動會從 ring buffer 上取得 DMA Page,並將新的 DMA Page 補回 ring buffer。
實務上,這樣每次都要補一個新的page上去時間成本很高,所以igb驅動有一些優化作法,像是page reuse還有batch allocation,不過後面有空再細談,這邊先忽略。
要注意的是,這些 DMA Page 實際上並不在 ring buffer 中儲存,ring buffer 只是存放指向這些 Page 的指標。
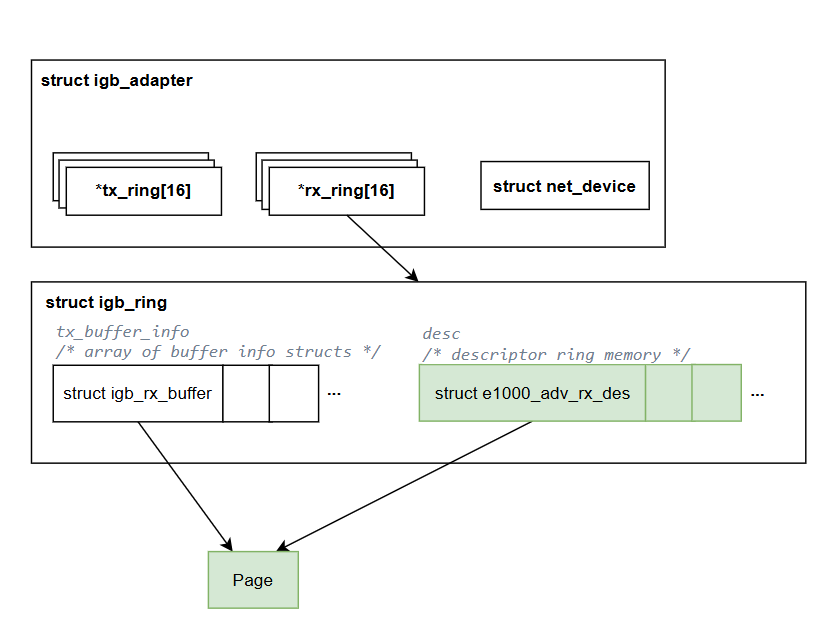
接著讓我們回到 IGB 驅動的實作,雖然每一個 igb_ring 都是一個封包傳輸對列,但是在 igb_ring 結構中卻是由兩個 ring buffer 結構構成的。
struct igb_ring {
struct igb_q_vector *q_vector; /* 中斷相關資料結構 */
struct net_device *netdev; /* back pointer to net_device */
struct bpf_prog *xdp_prog;
struct device *dev; /* device pointer for dma mapping */
union { /* array of buffer info structs */
struct igb_tx_buffer *tx_buffer_info;
struct igb_rx_buffer *rx_buffer_info;
};
void *desc; /* descriptor ring memory */
...
/* everything past this point are written often */
u16 next_to_clean;
u16 next_to_use;
u16 next_to_alloc;
...
}
igb_ring 中有兩個指標:rx_buffer_info 和 desc。這兩個指標分別指向 igb_rx_buffer 和 e1000_adv_rx_desc 結構的陣列,這兩個陣列實際上構成了兩個 ring buffer。
我們可以先看看 igb 是怎麼初始化這兩個 ring buffer 的,在初始化 igb_ring 結構的函數中。
int igb_setup_rx_resources(struct igb_ring *rx_ring)
{
struct igb_adapter *adapter = netdev_priv(rx_ring->netdev);
struct device *dev = rx_ring->dev;
int size, res;
...
size = sizeof(struct igb_rx_buffer) * rx_ring->count;
rx_ring->rx_buffer_info = vmalloc(size);
/* Round up to nearest 4K */
rx_ring->size = rx_ring->count * sizeof(union e1000_adv_rx_desc);
rx_ring->size = ALIGN(rx_ring->size, 4096);
rx_ring->desc = dma_alloc_coherent(dev, rx_ring->size,
&rx_ring->dma, GFP_KERNEL);
...
rx_ring->next_to_alloc = 0;
rx_ring->next_to_clean = 0;
rx_ring->next_to_use = 0;
...
}
rx_buffer_info 和 desc 都是大小為 rx_ring->count 的 ring buffer 結構,分別由 vmalloc 和 dma_alloc_coherent 申請記憶體。前者是用來申請一般記憶體的函數,後者是用來申請 DMA 記憶體的函數 (因為 DMA 記憶體申請是以4K page為單位,所以他會round up到最近的4K倍數)。
接著,我們來看一下 rx_buffer_info 的 igb_rx_buffer 結構的定義:
struct igb_rx_buffer {
dma_addr_t dma;
struct page *page;
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 page_offset;
#else
__u16 page_offset;
#endif
__u16 pagecnt_bias;
};
在 igb_rx_buffer 結構中,保存了 DMA Page 的物理地址(dma)以及該 DMA Page 在 Kernel 中的管理結構 struct page 的指標。另外,page_offset 是通過 igb_rx_offset 函數來計算的。
至於 page_offset,表示地是,當網卡實際要寫入封包的起始地址,要從 DMA Page 的開頭往後偏移多少。根據原始碼追蹤是使用 igb_rx_offset 算出來的。
static unsigned int igb_rx_offset(struct igb_ring *rx_ring)
{
return ring_uses_build_skb(rx_ring) ? IGB_SKB_PAD : 0;
}
// drivers/net/ethernet/intel/igb/igb.h
#define ring_uses_build_skb(ring) \
test_bit(IGB_RING_FLAG_RX_BUILD_SKB_ENABLED, &(ring)->flags)
IGB_RING_FLAG_RX_BUILD_SKB_ENABLED 這個 flag 的功能是直接將 DMA Page 作為 sk_buff 的 packet data buffer。按照一般的做法驅動會申請一個全新的 sk_buff 和 packet data buffer 空間,然後將封包內容搬過去,但這樣就會增加一次額外的封包複製。因此,為了省下這次封包複製,就可以將 DMA 寫入的這個 DMA Page 直接當成是 packet data buffer。
當啟用 IGB_RING_FLAG_RX_BUILD_SKB_ENABLED 這個 flag 的時候,這個 igb ring 對列就會利用現有的 DMA page來做為 sk_buff 的 packet data buffer,這時候 driver 會在 DMA page的最前面留下 IGB_SKB_PAD 的空間,但具體來說留下這段空間的功能是甚麼,筆者目前不太了解。。
這邊有點岔題了,讓我們回到igb_ring 結構,該結構包含兩個主要的環形緩衝區:rx_buffer_info 與 desc。另外一個,desc 是建立在 DMA Page 上的,因此網卡可以直接存取它。
union e1000_adv_rx_desc (desc 元素) 是 IGB 驅動中的接收描述符(rx descriptor)結構,具體如下:
// drivers/net/ethernet/intel/igbvf/vf.h
union e1000_adv_rx_desc {
struct {
__le64 pkt_addr; /* Packet buffer address */
__le64 hdr_addr; /* Header buffer address */
} read;
struct {
struct {
union {
__le32 data;
struct {
__le16 pkt_info; /* RSS/Packet type */
/* Split Header, hdr buffer length */
__le16 hdr_info;
} hs_rss;
} lo_dword;
union {
__le32 rss; /* RSS Hash */
struct {
__le16 ip_id; /* IP id */
__le16 csum; /* Packet Checksum */
} csum_ip;
} hi_dword;
} lower;
struct {
__le32 status_error; /* ext status/error */
__le16 length; /* Packet length */
__le16 vlan; /* VLAN tag */
} upper;
} wb; /* writeback */
};
該結構是一個 union,其子結構為 read 與 wb。在 C 語言中,union 表示這些子結構是共用同一段記憶體空間的。
在接收封包的過程中,驅動會申請新的 DMA Page,並將其物理地址寫入 rx_desc->read.pkt_addr。當網卡接收到封包後,會透過 DMA 直接將封包資料寫入這個地址,接著網卡會將封包資訊寫回 wb 結構中。其中,rx_desc->wb.upper.length 欄位表示接收到的封包長度。
雖然 read 與 wb 共用記憶體空間,但 wb.upper.length 對應的記憶體區域並不會被 read.pkt_addr 覆蓋。因此,驅動程式可以檢查 wb.upper.length 來判斷是否有新的封包進來需要處理。
對於驅動程式來說,只需要檢查 next_to_read 指向的 descriptor 是否有非 0 的長度,就可以知道是否有新的封包可供處理。相對地,網卡只需檢查 next_to_write 指向的 descriptor 是否為 0,就能確認該緩衝區是否可以寫入封包資料。
struct igb_rx_buffer {
dma_addr_t dma;
struct page *page;
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 page_offset;
#else
__u16 page_offset;
#endif
__u16 pagecnt_bias;
};
從上面的介紹可以發現,驅動與網卡之間主要是透過 desc 這個 ring buffer 完成 DMA 地址與封包內容的交換的。
不過可能因為需要保存原始 DMA 地址、page 結構指標,這些沒有必要 DMA 給網卡的資訊,所以驅動才建立了額外以 igb_rx_buffer 為元素的 rx_buffer_info ring buffer。 (個人理解上的猜測,暫時沒找到相關說明)
igb_open 函數中,除了與接收隊列 (igb_ring) 相關的內容,剩下的部分與中斷相關,但是因為中斷是另外一個很複雜的議題,所以我們先跳過,在本系列不講,直接來看igb驅動具體是怎麼接收封包的,而中斷相關的內容,如果後續還有空再來補充。
今天介紹了 igb_ring 對列,以及其中 rx_buffer_info 和 desc 兩個 ring buffer 的結構,明天我們就實際來了解 igb_ring 是怎麼運作接收資料的。


 iThome鐵人賽
iThome鐵人賽