昨天我們了解了 igb 網卡驅動建立的 igb_ring 隊列,那今天就要真的來解析 igb 網卡驅動是怎麼接收封包的。這邊我們跳過中斷處理的內容,直接從 igb 網卡驅動開始一直到轉交給 Kernel 的網路子系統。
當網卡接收到封包並透過 DMA (Direct Memory Access) 傳輸到記憶體後,會發起中斷。此時,Kernel 會呼叫 igb driver 提供的 igb_clean_rx_irq 函數來處理這些封包的接收。
這裡我們將跳過中斷處理與 NAPI 的細節,未來有時間再補充介紹。
static int igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
...
unsigned int total_bytes = 0, total_packets = 0
...
while (likely(total_packets < budget)) {
/* 處理一個封包 DMA PAGE */
...
if (/* ring 上的封包都處理完了 */)
break;
/* update budget accounting */
total_packets++;
}
...
}
如果每次接收一個封包都要發起一次中斷,在遇到大流量時就會造成大量的中斷,降低低 CPU 的處理效率。
因此這邊使用 Poll 的方式去處理封包。每次中斷發生時,igb_clean_rx_irq 函數會盡可能的把所有已經 DMA 到記憶體中的封包都處理掉,所以這邊會跑一個 while loop,每個 iteration 都會處理一個 ring buffer 上的封包,直到 ring buffer 上的封包都處理完了,或著次數超出次數上限 (budget)。
接下來,我們將跳過與 igb 維護 rx_ring 相關的部分,專注於分析 igb 驅動如何處理單個封包。先給大家看完整的 igb_clean_rx_irq 函數,後面會一段一段解析。
static int igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
struct igb_adapter *adapter = q_vector->adapter;
struct igb_ring *rx_ring = q_vector->rx.ring;
struct sk_buff *skb = rx_ring->skb;
unsigned int total_bytes = 0, total_packets = 0;
u16 cleaned_count = igb_desc_unused(rx_ring);
unsigned int xdp_xmit = 0;
struct xdp_buff xdp;
u32 frame_sz = 0;
int rx_buf_pgcnt;
/* Frame size depend on rx_ring setup when PAGE_SIZE=4K */
#if (PAGE_SIZE < 8192)
frame_sz = igb_rx_frame_truesize(rx_ring, 0);
#endif
xdp_init_buff(&xdp, frame_sz, &rx_ring->xdp_rxq);
while (likely(total_packets < budget)) {
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *rx_buffer;
ktime_t timestamp = 0;
int pkt_offset = 0;
unsigned int size;
void *pktbuf;
/* return some buffers to hardware, one at a time is too slow */
if (cleaned_count >= IGB_RX_BUFFER_WRITE) {
igb_alloc_rx_buffers(rx_ring, cleaned_count);
cleaned_count = 0;
}
rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean);
size = le16_to_cpu(rx_desc->wb.upper.length);
if (!size)
break;
/* This memory barrier is needed to keep us from reading
* any other fields out of the rx_desc until we know the
* descriptor has been written back
*/
dma_rmb();
rx_buffer = igb_get_rx_buffer(rx_ring, size, &rx_buf_pgcnt);
pktbuf = page_address(rx_buffer->page) + rx_buffer->page_offset;
/* pull rx packet timestamp if available and valid */
if (igb_test_staterr(rx_desc, E1000_RXDADV_STAT_TSIP)) {
int ts_hdr_len;
ts_hdr_len = igb_ptp_rx_pktstamp(rx_ring->q_vector,
pktbuf, ×tamp);
pkt_offset += ts_hdr_len;
size -= ts_hdr_len;
}
/* retrieve a buffer from the ring */
if (!skb) {
unsigned char *hard_start = pktbuf - igb_rx_offset(rx_ring);
unsigned int offset = pkt_offset + igb_rx_offset(rx_ring);
xdp_prepare_buff(&xdp, hard_start, offset, size, true);
xdp_buff_clear_frags_flag(&xdp);
#if (PAGE_SIZE > 4096)
/* At larger PAGE_SIZE, frame_sz depend on len size */
xdp.frame_sz = igb_rx_frame_truesize(rx_ring, size);
#endif
skb = igb_run_xdp(adapter, rx_ring, &xdp);
}
if (IS_ERR(skb)) {
unsigned int xdp_res = -PTR_ERR(skb);
if (xdp_res & (IGB_XDP_TX | IGB_XDP_REDIR)) {
xdp_xmit |= xdp_res;
igb_rx_buffer_flip(rx_ring, rx_buffer, size);
} else {
rx_buffer->pagecnt_bias++;
}
total_packets++;
total_bytes += size;
} else if (skb)
igb_add_rx_frag(rx_ring, rx_buffer, skb, size);
else if (ring_uses_build_skb(rx_ring))
skb = igb_build_skb(rx_ring, rx_buffer, &xdp,
timestamp);
else
skb = igb_construct_skb(rx_ring, rx_buffer,
&xdp, timestamp);
/* exit if we failed to retrieve a buffer */
if (!skb) {
rx_ring->rx_stats.alloc_failed++;
rx_buffer->pagecnt_bias++;
break;
}
igb_put_rx_buffer(rx_ring, rx_buffer, rx_buf_pgcnt);
cleaned_count++;
/* fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
/* verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* probably a little skewed due to removing CRC */
total_bytes += skb->len;
/* populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
napi_gro_receive(&q_vector->napi, skb);
/* reset skb pointer */
skb = NULL;
/* update budget accounting */
total_packets++;
}
/* place incomplete frames back on ring for completion */
rx_ring->skb = skb;
if (xdp_xmit & IGB_XDP_REDIR)
xdp_do_flush();
if (xdp_xmit & IGB_XDP_TX) {
struct igb_ring *tx_ring = igb_xdp_tx_queue_mapping(adapter);
igb_xdp_ring_update_tail(tx_ring);
}
u64_stats_update_begin(&rx_ring->rx_syncp);
rx_ring->rx_stats.packets += total_packets;
rx_ring->rx_stats.bytes += total_bytes;
u64_stats_update_end(&rx_ring->rx_syncp);
q_vector->rx.total_packets += total_packets;
q_vector->rx.total_bytes += total_bytes;
if (cleaned_count)
igb_alloc_rx_buffers(rx_ring, cleaned_count);
return total_packets;
}
在接收封包的過程中,驅動首先會取得下一個待處理的 descriptor,並從中讀取封包的長度。
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *rx_buffer;
rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean);
size = le16_to_cpu(rx_desc->wb.upper.length);
if (!size)
break;
這裡使用 rx_ring->next_to_clean 來從 desc ring buffer 中取得下一個 descriptor,然後使用 rx_desc->wb.upper.length 來獲取網卡寫入的封包長度。由於封包長度是由網卡這種外部設備寫入的,因此會使用 le16_to_cpu 來進行大小端轉換。如果此時封包長度為 0,則表示該 descriptor 對應的DMA PAGE還沒沒有封包寫入,整個 ring 上沒有需要處理的封包了,就會直接 break 離開處理函數。
由於 descriptor 保存的 DMA Page 地址已經被網卡寫入覆蓋成封包的資訊了,所以需要從igb_rx_buffer 中取得對應的資料。
void *pktbuf;
struct igb_rx_buffer *rx_buffer;
rx_buffer = igb_get_rx_buffer(rx_ring, size, &rx_buf_pgcnt);
pktbuf = page_address(rx_buffer->page) + rx_buffer->page_offset;
驅動會透過 igb_rx_buffer 取得對應的 DMA PAGE 物理地址,然後使用 page_address 函數將頁的物理地址轉換為虛擬地址,並加上 page_offset,取得網卡寫入封包的虛擬地址,最終將結果保存在 pktbuf 中,這樣驅動便可以直接存取封包內容,進行後續的處理。
如果網卡支援 PTP 時間同步,則網卡寫入封包時,會在封包前寫入時間戳 (timestamp)。那麼,實際的 packet 內容的所在地址就要在往後移時間戳的長度 (ts_hdr_len)。
int pkt_offset = 0;
if (igb_test_staterr(rx_desc, E1000_RXDADV_STAT_TSIP)) {
int ts_hdr_len;
ts_hdr_len = igb_ptp_rx_pktstamp(rx_ring->q_vector,
pktbuf, ×tamp);
pkt_offset += ts_hdr_len;
size -= ts_hdr_len;
}
這邊會先把這個數值會保存在 pkt_offset 中,然後實際的封包大小 (size) 就要扣掉 ts_hdr_len。
struct xdp_buff xdp;
/* retrieve a buffer from the ring */
if (!skb) {
unsigned char *hard_start = pktbuf - igb_rx_offset(rx_ring);
unsigned int offset = pkt_offset + igb_rx_offset(rx_ring);
xdp_prepare_buff(&xdp, hard_start, offset, size, true);
xdp_buff_clear_frags_flag(&xdp);
#if (PAGE_SIZE > 4096)
/* At larger PAGE_SIZE, frame_sz depend on len size */
xdp.frame_sz = igb_rx_frame_truesize(rx_ring, size);
#endif
skb = igb_run_xdp(adapter, rx_ring, &xdp);
}
這邊會先判斷 skb 是不是空,一般情況下 skb 指標會是空的,所以進入該區塊。
因為 while 迴圈的一個 iteraction 只會處取一個 Page,所以當封包內容大小超過一個 Page 的大小時就會需要跑多次回圈,讀多個 Page 來拼接。當發生這個情況或著或上一次處理中斷時,封包存在不完整的狀況,skb 會保留前一次 iteraction 申請的 sk_buff 指標,那就不會執行到該區塊。
接著要計算兩個數值 hard_start 和 offset。
hard_start 指向該封包 data buffer 的起始位置,pktbuf 指向封包內容的開頭,所以這邊會用 pktbuf 扣掉 igb_rx_offset 找到最起始的位置。前面說道這個如果是 IGB_RING_FLAG_RX_BUILD_SKB_ENABLED,那驅動會在buffer開頭額外預留出 IGB_SKB_PAD,那這邊就要把扣掉。整理起來長這樣: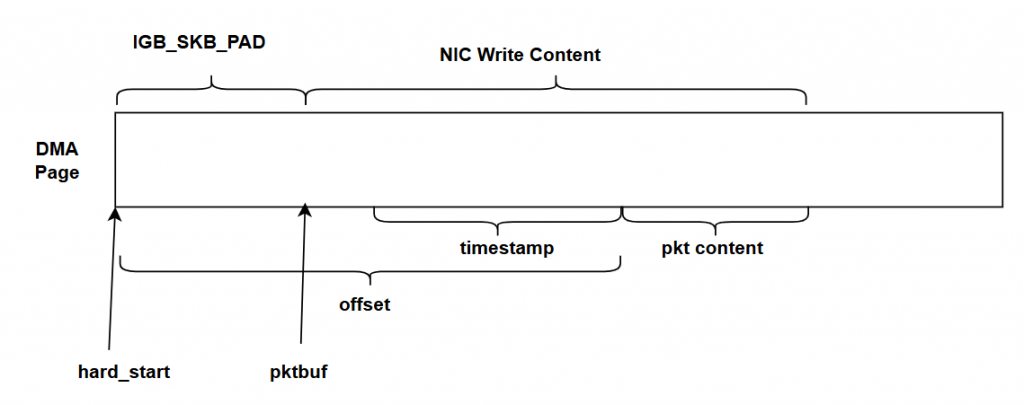
接著看到一連串 XDP 開頭的函數就知道,這裡就是網卡驅動接收封包時的 eBPF XDP 進入點了,所以可知 XDP 真的需要驅動去寫才能支援的,而且是在 socket buffer allocation 之前。
首先會根據剛剛算出來的位移和封包大小資料去準備 xdp 的上下文,接著呼叫 igb_run_xdp 。
static struct sk_buff *igb_run_xdp(struct igb_adapter *adapter,
struct igb_ring *rx_ring,
struct xdp_buff *xdp)
{
int err, result = IGB_XDP_PASS;
struct bpf_prog *xdp_prog;
u32 act;
xdp_prog = READ_ONCE(rx_ring->xdp_prog); /* 讀取 XDP 程式 */
if (!xdp_prog)
goto xdp_out;
prefetchw(xdp->data_hard_start); /* xdp_frame write */
act = bpf_prog_run_xdp(xdp_prog, xdp); /* eBPF 進入點 */
switch (act) {
case XDP_PASS:
break;
case XDP_TX:
result = igb_xdp_xmit_back(adapter, xdp);
if (result == IGB_XDP_CONSUMED)
goto out_failure;
break;
case XDP_REDIRECT:
err = xdp_do_redirect(adapter->netdev, xdp, xdp_prog);
if (err)
goto out_failure;
result = IGB_XDP_REDIR;
break;
default:
bpf_warn_invalid_xdp_action(adapter->netdev, xdp_prog, act);
fallthrough;
case XDP_ABORTED:
out_failure:
trace_xdp_exception(rx_ring->netdev, xdp_prog, act);
fallthrough;
case XDP_DROP:
result = IGB_XDP_CONSUMED;
break;
}
xdp_out:
return ERR_PTR(-result);
}
可以看到 igb 驅動會讀取綁定在 rx_ring 上的 xdp program,然後呼叫 bpf_prog_run_xdp 執行 XDP 程式。然後根據 XDP 結果去處理,如果是 XDP_PASS 就繼續執行一般封包的接收流程。
#define IGB_XDP_PASS 0
skb = igb_run_xdp(adapter, rx_ring, &xdp);
// igb_clean_rx_irq
if (IS_ERR(skb)) {
unsigned int xdp_res = -PTR_ERR(skb);
if (xdp_res & (IGB_XDP_TX | IGB_XDP_REDIR)) {
xdp_xmit |= xdp_res;
igb_rx_buffer_flip(rx_ring, rx_buffer, size);
} else {
rx_buffer->pagecnt_bias++;
}
total_packets++;
total_bytes += size;
} else if (skb)
igb_add_rx_frag(rx_ring, rx_buffer, skb, size);
else if (ring_uses_build_skb(rx_ring))
skb = igb_build_skb(rx_ring, rx_buffer, &xdp,
timestamp);
else
skb = igb_construct_skb(rx_ring, rx_buffer,
&xdp, timestamp);
回到 igb_clean_rx_irq ,接著是對 XDP 的執行結果做一些處理,如果沒有錯誤然後是 XDP_PASS 的話,skb 會是 0,所以跳到最後一個if判斷。
這邊要做的事情是執行 socket allocation,建立 sk_buff 結構實體。前面介紹到的,如果啟用IGB_RING_FLAG_RX_BUILD_SKB_ENABLED,那就會執行 igb_build_skb,直接使用前面的 DMA Page 當作 packet data buffer,不然就會呼叫到 igb_construct_skb,同時建立 sk_buff 和 packet data buffer。兩個函數都會建立 sk_buff 結構實體,然後配置指標指向 packet data buffer,這邊就不跟進去看了。
/* exit if we failed to retrieve a buffer */
if (!skb) {
rx_ring->rx_stats.alloc_failed++;
rx_buffer->pagecnt_bias++;
break;
}
/* 更新 rx_ring 跳過不說明 */
igb_put_rx_buffer(rx_ring, rx_buffer, rx_buf_pgcnt);
cleaned_count++;
/* fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
/* verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* probably a little skewed due to removing CRC */
total_bytes += skb->len;
/* populate checksum, timestamp, VLAN, and protocol */
/* 提取封包內容,寫入到 sk_buff */
igb_process_skb_fields(rx_ring, rx_desc, skb);
接著會有一系列的處理來維護 rx_ring 結構還有計算 sk_buff 裡面的欄位數值,igb_is_non_eop 會判斷封包是否結尾,非結尾表示一個封包太大,超過一個 page 可以保存的內容需要讀取下一個 page,所以會 continue 再走一遍流程,這時候 skb 指標已經指向建立好的 sk_buff 實例。
napi_gro_receive(&adapter->napi, skb);
因為沒有介紹中斷機制,所以沒有特別介紹 NAPI (New API),並默認採用 NAPI,有興趣可以的讀者可以在查查。
接著就會呼叫 kernel API 將處理好的 sk_buff 轉交給 kernel 還有協定層來處理拉!
這邊會呼叫 napi_gro_receive 先做 Generic Receive Offload (GRO) 處理。GRO 簡單來說就是把同一個TCP/UDP flow 的多個封包 (sk_buff) 合併成一個 sk_buff 再交由上層的協定層處理,減少協定層處理的封包數量。所以呼叫napi_gro_receive 後封包會被快取在GRO子系統中,然後要等 GRO 的快取存超過一定數量的封包才會 flush 轉交給網路子系統。
雖然沒有想要介紹 GRO,但是找 GRO 怎麼送到網路子系統的時候花了不少時間,所以這邊補充說明流程。
// net/core/gro.c
static gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb, 0);
ret = napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
trace_napi_gro_receive_exit(ret);
return ret;
}
static gro_result_t napi_frags_finish(struct napi_struct *napi,
struct sk_buff *skb,
gro_result_t ret)
{
switch (ret) {
case GRO_NORMAL:
case GRO_HELD:
__skb_push(skb, ETH_HLEN);
skb->protocol = eth_type_trans(skb, skb->dev);
if (ret == GRO_NORMAL)
gro_normal_one(napi, skb, 1);
break;
case GRO_MERGED_FREE:
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else
napi_reuse_skb(napi, skb);
break;
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}
napi_gro_receive 會呼叫 dev_gro_receive 處理,然後根據結果判斷需要合併還是直接送到協定層,但都會是呼叫 gro_normal_one 來把放到一個 GRO 內部的快取列表。
// include/net/gro.h
static inline void gro_normal_one(struct napi_struct *napi, struct sk_buff *skb, int segs)
{
list_add_tail(&skb->list, &napi->rx_list);
napi->rx_count += segs;
if (napi->rx_count >= READ_ONCE(gro_normal_batch))
gro_normal_list(napi);
}
static inline void gro_normal_list(struct napi_struct *napi)
{
if (!napi->rx_count)
return;
netif_receive_skb_list_internal(&napi->rx_list);
INIT_LIST_HEAD(&napi->rx_list);
napi->rx_count = 0;
}
接著會檢查快取的數量是不是超過 gro_normal_batch,如果數量到了就會呼叫 gro_normal_list,藉由 netif_receive_skb_list_internal 將封包送到網路子系統。gro_normal_batch 由 /proc/sys/net/core/gro_normal_batch 控制,在我的電腦上是 8,
到這邊封包就成功被送到網路子系統了,明天我們再接著來看網路子系統的部分。


 iThome鐵人賽
iThome鐵人賽