昨天,我們分析了,中斷發生後 igb 網卡驅動是如何透過 igb_clean_rx_irq 函數,接收封包資料、建立 sk_buff 結構,然後轉交給 GRO 處理的,最後 GRO 呼叫網路子系統的 netif_receive_skb_list_internal 函數,將 GRO 快取的一系列 skb 轉交給網路子系統處理。
如果是呼叫 netif_receive_skb 直接由網路子系統接收封包,路徑會是:
netif_receive_skb
- netif_receive_skb_internal
-- __netif_receive_skb
--- __netif_receive_skb_one_core
---- __netif_receive_skb_core
GRO 呼叫的 netif_receive_skb_list_internal 則是:
netif_receive_skb_list_internal
- __netif_receive_skb_list
-- __netif_receive_skb_list_core
--- __netif_receive_skb_core
不同接收封包的路徑,最後都會到達網路子系統處理封包接收的核心函數 __netif_receive_skb_core。
這個中間過程不會做過多的介紹,不過可以稍微提一下的是,兩個路徑的中間函數中會處理 RPS (Receive Packet Steering)。
簡單來說,因為中斷處理的特性,前面的封包處理可能會集中在特定幾個 CPU Core 上,RPS 機制會重新將封包分配到多個 CPU Core 去處理。當然 RPS 會把童一個 TCP/UDP flow放 在同一個Core處理,所以不會有 Out of order 的問題。
網路子系統的接收處理主要還是在 __netif_receive_skb_core 這個大函數。所以接下來我們就來解析這個函數,跟igb_clean_rx_irq 一樣,我會一段一段介紹,但這次就不貼完整的函數定義上來佔篇幅了。
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
/* 變數初始化 */
...
another_round:
if (static_branch_unlikely(&generic_xdp_needed_key)) {
int ret2;
migrate_disable();
ret2 = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
migrate_enable();
if (ret2 != XDP_PASS) {
ret = NET_RX_DROP;
goto out;
}
}
...
第一個部分就是 XDP Generic 的進入點,所以沒有驅動支援的 XDP Generic 真的發生在 socket allocation 後面很多的地方,會比一般的 XDP 慢很多。
if (eth_type_vlan(skb->protocol)) {
skb = skb_vlan_untag(skb);
if (unlikely(!skb))
goto out;
}
接著會把 vlan header 的資料寫入到 sk_buff,然後移除掉封包的 vlan header。
if (skb_skip_tc_classify(skb))
goto skip_classify;
if (pfmemalloc)
goto skip_taps;
接著會做兩個 goto 判斷,skb_skip_tc_classify 是針對 ifb interface 去跳過TC,pfmemalloc 跟記憶體不足的時候處理有關。所以一般來說這兩個 goto 都不會生效。
struct packet_type *ptype;
...
if (pfmemalloc)
goto skip_taps;
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
skip_taps:
skip_taps 跳過的區塊是緊臨接著的這個區塊,這塊會遍歷全域變數 ptype_all 列表,還有保存在封包來源網路設備 net_device 結構內的列表 skb->dev->ptype,然後呼叫deliver_skb函數。
ptype是一個packet_type結構的指標。
// include/linux/netdevice.h
struct packet_type {
__be16 type; /* This is really htons(ether_type). */
bool ignore_outgoing;
struct net_device *dev; /* NULL is wildcarded here */
netdevice_tracker dev_tracker;
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *);
void (*list_func) (struct list_head *,
struct packet_type *,
struct net_device *);
bool (*id_match)(struct packet_type *ptype,
struct sock *sk);
struct net *af_packet_net;
void *af_packet_priv;
struct list_head list;
};
// net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
...
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
packet_type 和 deliver_skb 是網路子系統處理封包接收時最重要的結構,packet_type 定義了一種 protocol packet handler,其中包含了 func 函數指標,當網路子系統以 packet_type 為參數,呼叫 deliver_skb 時,會呼叫到 packet_type 結構定義的 func 函數,並把封包 (skb) 發送給 packet handler 處理。
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
packet_type 也就是網路子系統與協定層溝通的方式,不同的協定會定義各自的 protocol packet handler,比如下面是 IPv4 的封包處理函數,所以當網路子系統確認這是一個IP封包後,就能夠呼叫到 ip_rcv,將封包 (sk_buff) 提交給 IP子系統處理接收。
if (pfmemalloc)
goto skip_taps;
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
skip_taps:
接著讓我們回到 __netif_receive_skb_core,這裡定義的 ptype_all 就是不論他是甚麼類型的封包,都要先送給註冊記錄在 ptype_all 列表裡面的 packet_type packet handler 處理。這裡正是 TCPDUMP 的進入點,當使用者使用 TCPDUMP 想要抓取封包時,便會建立一個 packet_type 結構,掛在 ptype_all,來抓取所有接收到封包,然後再做過濾。
可以發現程式碼並不是把遍歷
ptype_all的結果 (ptype) 作為deliver_skb的參數,而是先用pt_prev作為參數,然後才將新的ptype存到pt_prev內,整個__netif_receive_skb_core都採用這樣延遲呼叫的方式去運作,先將要呼叫的packet_type結構保存在pt_prev指標變數中,當找到下一個要執行的packet_type時才會在覆蓋pt_prev前執行deliver_skb(skb, pt_prev, ...)
skip_taps:
#ifdef CONFIG_NET_INGRESS
if (static_branch_unlikely(&ingress_needed_key)) {
bool another = false;
nf_skip_egress(skb, true);
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev,
&another);
if (another)
goto another_round;
if (!skb)
goto out;
nf_skip_egress(skb, false);
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)
goto out;
}
#endif
skb_reset_redirect(skb);
skip_classify:
我們繼續往下看,接下來的重點是中間的sch_handle_ingress。這裡正是 Linux TC (Traffic Control) 子系統的 Ingress 進入點,當然也就是 eBPF TC ingress 的進入點。
sch_handle_ingress
- tc_run
-- tcf_classify // include/net/pkt_cls.h
另外一個重點是 nf_ingress,這個是 netfilter 中 NF_NETDEV_INGRESS 的進入點,查了一下資料,這個好像除了 prerouting, input, forward, output, postrouting 以外,比較後來加入的進入點。
nf_ingress
- nf_hook_ingress
-- nf_hook_slow(NF_NETDEV_INGRESS) // include/linux/netfilter_netdev.h
接下來的程式邏輯與 VLAN Interface有關,我們先回憶一下。在 Linux 我們可以對一個介面建立一個 VLAN 的子介面。
modprobe 8021q
ip link add link enp0s3 name enp0s3.100 type vlan id 100
ip addr add 192.168.0.200/24 dev enp0s3.100
當一個帶 VLAN ID 100 的封包被 enp0s3 網卡接收後,我們可以從 enp0s3.100 這個網路介面操作去除 VLAN header 後的封包。
__netif_receive_skb_core 接下來這段邏輯就是要處理 vlan 介面。
skip_classify:
if (pfmemalloc && !skb_pfmemalloc_protocol(skb))
goto drop;
if (skb_vlan_tag_present(skb)) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto out;
}
先把執行前一個 packet handler (pt_prev) ,然後重點是呼叫 vlan_do_receive 函數。
bool vlan_do_receive(struct sk_buff **skbp)
{
struct sk_buff *skb = *skbp;
__be16 vlan_proto = skb->vlan_proto;
u16 vlan_id = skb_vlan_tag_get_id(skb);
struct net_device *vlan_dev;
struct vlan_pcpu_stats *rx_stats;
vlan_dev = vlan_find_dev(skb->dev, vlan_proto, vlan_id);
if (!vlan_dev)
return false;
...
skb->dev = vlan_dev;
...
__vlan_hwaccel_clear_tag(skb);
...
return true;
可以看到,會 vlan_do_receive 呼叫 vlan_find_dev 找到該 vlan ID 對應的子介面,也就是剛剛舉例的enp0s3.100。然後將該封包的關聯設備 skb->dev 從原本的乙太網卡設備變更成 vlan_dev,同時將 skb 中 vlan 的相關資訊清除,然後回傳 true。
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
/* 變數初始化 */
...
another_round:
...
if (vlan_do_receive(&skb))
goto another_round;
如果 vlan_do_receive 回傳 true 的話,就會 goto 到 another_round,也就是從__netif_receive_skb_core函數的最頭,重新在執行過一次,就好像真的是從 vlan_dev 接收到這個封包的。
可以看到在 net_device 設備結構中可以保存一個 rx_handler。
// include/linux/netdevice.h
enum rx_handler_result {
RX_HANDLER_CONSUMED,
RX_HANDLER_ANOTHER,
RX_HANDLER_EXACT,
RX_HANDLER_PASS,
};
typedef enum rx_handler_result rx_handler_result_t;
typedef rx_handler_result_t rx_handler_func_t(struct sk_buff **pskb);
struct net_device {
...
rx_handler_func_t __rcu *rx_handler;
...
}
rx_handler 一樣是一種 packet handler 的函數。
// __netif_receive_skb_core
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
break;
case RX_HANDLER_PASS:
break;
default:
BUG();
}
}
...
out:
*pskb = skb;
return ret;
}
__netif_receive_skb_core會執行 net_device 綁定的 handler,然後根據 handler 的回傳值(rx_handler_result_t) 決定後續的處理行為。
rx_handler 最經典用例就是 Linux Bridge,當我們將一個網路卡加入到 Linux Bridge 時 (brctl addif br0 eth0),實際上就是將該網卡的 rx_handler 設置為 Linux Bridge 系統提供的 br_handle_frame (net/bridge/br_input.c) 函數。
當網卡接收到封包時,就會執行 br_handle_frame,如果是一般情況下,封包可能就會被送到另外一個網路介面卡的TX,那__netif_receive_skb_core就沒有必要繼續處理該封包及送到協定層了,那就會回傳RX_HANDLER_CONSUMED,表示該封包已經由 rx_handler 處理完成,__netif_receive_skb_core 就會直接 goto out,結束處理。
接著有一段是對 vlan id 無效之類的特殊 VLAN情況的處理就直接跳過。
當上面的一切都處理完後,接著就是 __netif_receive_skb_core 的最後一個部分,也就是準備往協定層發送。
type = skb->protocol;
/* deliver only exact match when indicated */
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&ptype_base[ntohs(type) &
PTYPE_HASH_MASK]);
}
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&orig_dev->ptype_specific);
if (unlikely(skb->dev != orig_dev)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&skb->dev->ptype_specific);
}
if (pt_prev) {
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
goto drop;
*ppt_prev = pt_prev;
} else {
drop:
...
}
out:
/* The invariant here is that if *ppt_prev is not NULL
* then skb should also be non-NULL.
*
* Apparently *ppt_prev assignment above holds this invariant due to
* skb dereferencing near it.
*/
*pskb = skb;
return ret;
}
這邊會好幾次呼叫 deliver_ptype_list_skb,所以我們先看這個東西。
static inline void deliver_ptype_list_skb(struct sk_buff *skb,
struct packet_type **pt,
struct net_device *orig_dev,
__be16 type,
struct list_head *ptype_list)
{
struct packet_type *ptype, *pt_prev = *pt;
list_for_each_entry_rcu(ptype, ptype_list, list) {
if (ptype->type != type)
continue;
if (pt_prev)
deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
*pt = pt_prev;
}
// include/linux/netdevice.h
struct packet_type {
__be16 type; /* This is really htons(ether_type). */
...
}
deliver_ptype_list_skb 會找到輸入的 ptype_list 列表中,packet_type.type (ether type) 與輸入的 type 相同的 packet_type。
每次輸入的 type 都是 type = skb->protocol;,也就是從封包解析出來的乙太網路類型,主要可能就是 0x0800 (IPv4)、0x0806 (ARP)。
__netif_receive_skb_core 會分別在 ptype_base、orig_dev->ptype_specific、skb->dev->ptype_specific 三個列表中去查找該以太網路類型的處理函數。
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&ptype_base[ntohs(type) &
PTYPE_HASH_MASK]);
}
ptype_base 保存的是 Linux kernel 協定層定義的處理函數,也就是標準的 IP、ARP 等類型的處理函數,因為這些查找會非常頻繁,所以 Linux 做了一個 hash table 的優化 (ntohs(type) & PTYPE_HASH_MASK) 避免每個封包都需要遍歷整個列表。
deliver_exact 只有當 rx_handler 的回傳是 RX_HANDLER_EXACT 才會為真,表示跳過通用的封包處理,只接受 skb 關聯設備的處理函數。
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&orig_dev->ptype_specific);
if (unlikely(skb->dev != orig_dev)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&skb->dev->ptype_specific);
}
所以接下來就會去查找 net_device 保存的 ptype_specific 列表,如果是 vlan interface 之類的情況,那 skb->dev 指向的就會是 vlan 子介面,而不是原本收封包的乙太網路介面,那就會依序查找主介面和子介面的ptype_specific。
比較要留意的點是這邊的設計是所有伏地的 packet handler 都會被執行,而不是只有一個。
如同前面有提到 packet_type.func 都不是在找到的時候被執行,而是會被保存在 pt_prev 裡面,延後執行,最後一個 pt_prev 保存的 packet_type 會被延後到 __netif_receive_skb_one_core 結束後執行。
static int __netif_receive_skb_one_core(struct sk_buff *skb, bool pfmemalloc)
{
struct net_device *orig_dev = skb->dev;
struct packet_type *pt_prev = NULL;
int ret;
ret = __netif_receive_skb_core(&skb, pfmemalloc, &pt_prev);
if (pt_prev)
ret = INDIRECT_CALL_INET(pt_prev->func, ipv6_rcv, ip_rcv, skb,
skb->dev, pt_prev, orig_dev); // 等價 deliver_skb
return ret;
}
__netif_receive_skb_core 找到的最後一個 packet_type 會被推遲到呼叫 __netif_receive_skb_core 的函數中執行。以 GRO 為例的話,是由 __netif_receive_skb_one_core 呼叫 __netif_receive_skb_core。
這邊不是用 deliver_skb 去執行 pt_prev->func,而是用 INDIRECT_CALL_INET,但其實行為deliver_skb相同。這個INDIRECT_CALL_INET是跟CPU分支預測漏洞和效能有關的,但結果都是執行 pt_prev->func 函數。
所以如果接收到的是一個一般的 ipv4 封包,在 __netif_receive_skb_core 中,會依序處理 tcpdump、Traffic Cotnrol、netfitler、vlan interface、bridge 相關的功能,最後呼叫 ip_rcv 將封包交給 IP 協定層去處理 routing及filtering。
到此,我們就介紹完 igb 網卡驅動是怎麼接收封包以及網路子系統是怎麼處理封包然後交給協定層處理的。同時也到了Linux Kernel 網路巡禮 這個系列的尾聲,相較於兩年前的教練我想玩eBPF :: 2022 iThome 鐵人賽系列,這次參加鐵人賽非常的突然,也沒有想清楚這次要講甚麼,找了一找之前介紹 Linux 網路技術跟虛擬化的投影片,想想決定,乾脆重複利用,來介紹 Linux 的網路技術好了,剛好之前為了研究就看過好幾次 igb 網卡驅動的原始碼,把這些內容寫進鐵人賽,也算是給自己的學習成果留下點紀錄和價值,為了避免 30 天沒內容可以寫,就把範圍擴大了一下,想說把完全沒有看過的namespace操作管理也一起了解一下,畫了這張目標地圖。
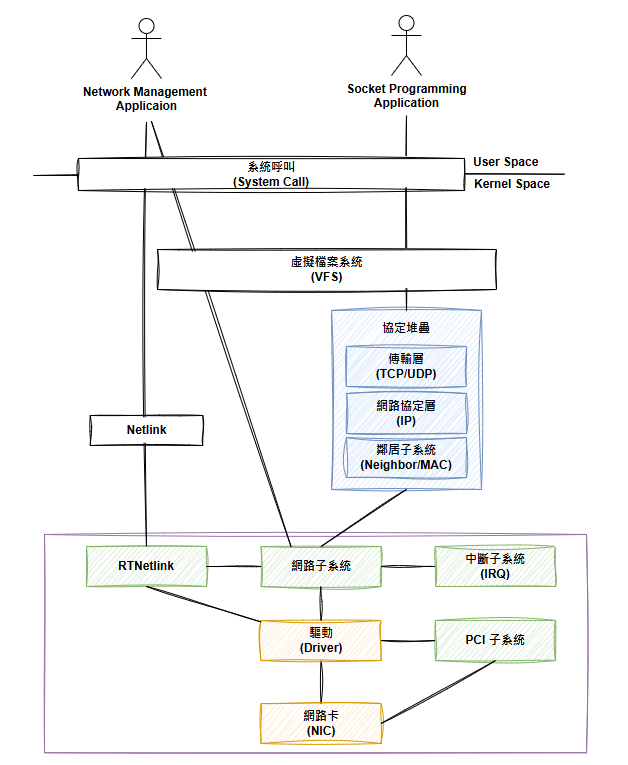
結果寫者寫著畫風就越來越奇怪了,從最一開始解析 network namespace 的原始碼,然後逐漸跑到 VFS 檔案系統、System Call、字元檔案系統驅動、Proc 檔案系統去了,完全變成檔案系統巡禮了,然後前15天的時間就這麼消失了。從第16天的內容開始,才回到我原先投影片的主軸,從介紹記憶體映射和PCI(e)的概念出發,延伸到網卡驅動和網路子系統的運作。算是有成功把這個系列給帶回正軌,不過最後介紹網路子系統的時間就超級短,導致最後3天的文章篇幅直接是前面的兩倍以上。比較可惜的是,原本規畫要介紹的 netlink 還有 DPDK、虛擬機封包處理等部分就來不急在這個系列文章中來探索了。
很開心,事隔兩年能夠再次參加iThome舉辦的鐵人賽,透過這次的文章競賽,對於之前模糊了解的 Linux 網路系統運作有了更深刻、實際的了解,希望各位讀者也能從這系列文章中有所收穫。
那麼,一樣,到這邊下台一鞠躬。
這次系列文章可以拆成介紹VFS還有網路卡驅動等好幾個獨立的子系列,之後會整理到 Louis Li's Blog (louisif.me)。


 iThome鐵人賽
iThome鐵人賽