
序列化是將數據結構或對象轉換為位序列的過程,以便可以將其存儲在文件或內存緩衝區中,或通過網絡連接進行傳輸,稍後可以在相同或不同的計算機環境中重建。設計一個算法來序列化和反序列化一棵二元樹。這裡對序列化和反序列化算法的實現方式沒有具體的限制,只需要保證可以將二元樹序列化為一個字符串,並且能夠將該字符串反序列化回原始的樹結構。
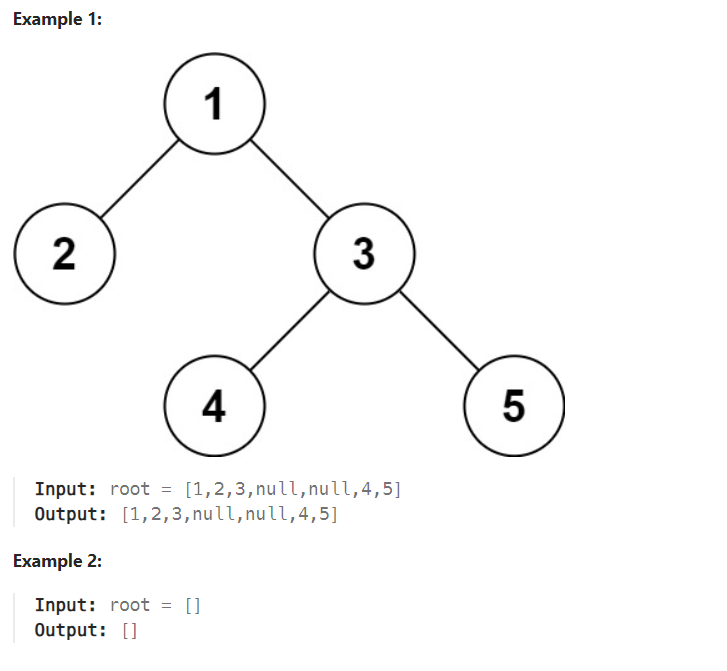
範例 1:
範例 2:
限制條件:
這個問題的核心是如何有效地將二元樹轉換為字符串進行存儲,並且在需要時能夠正確地重建該樹。解決這個問題的典型方法是使用 層序遍歷(BFS) 或 先序遍歷(DFS)。
1. 序列化:
2. 反序列化:
我們將使用 層序遍歷 來實現序列化與反序列化,這樣能更好地處理樹的結構,特別是對於不平衡或有 null 的樹。
class Codec {
public:
// 序列化:將二元樹轉換為字符串
string serialize(TreeNode* root) {
if (!root) return "[]"; // 空樹情況
queue<TreeNode*> q;
q.push(root);
stringstream ss;
ss << "[";
while (!q.empty()) {
TreeNode* node = q.front();
q.pop();
if (node) {
ss << node->val << ",";
q.push(node->left); // 將左子節點加入隊列
q.push(node->right); // 將右子節點加入隊列
} else {
ss << "null,";
}
}
string result = ss.str();
result.pop_back(); // 去掉最後一個逗號
result += "]";
return result;
}
// 反序列化:將字符串轉換為二元樹
TreeNode* deserialize(string data) {
if (data == "[]") return nullptr;
stringstream ss(data.substr(1, data.size() - 2)); // 去掉方括號
string item;
getline(ss, item, ',');
TreeNode* root = new TreeNode(stoi(item));
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
TreeNode* node = q.front();
q.pop();
// 左子節點
if (getline(ss, item, ',')) {
if (item != "null") {
node->left = new TreeNode(stoi(item));
q.push(node->left);
}
}
// 右子節點
if (getline(ss, item, ',')) {
if (item != "null") {
node->right = new TreeNode(stoi(item));
q.push(node->right);
}
}
}
return root;
}
};
1. 序列化與反序列化的選擇:
2. 處理空節點:為了確保二元樹的結構保持一致,必須將空節點用 null 來表示,並在反序列化過程中對應地跳過這些空節點。
3. 時間複雜度:序列化與反序列化的時間複雜度都是 O(n),其中 n 是樹中節點的數量,因為我們需要遍歷整棵樹中的每個節點。
4. 空間複雜度:由於使用了隊列來進行層序遍歷,空間複雜度也是 O(n)。
本題使用層次遍歷(BFS)實現了二元樹的序列化和反序列化,並確保無論樹的結構如何都能準確還原。在序列化時,我們用 null 來標示空節點,這樣可以保證在反序列化時,樹的結構能夠正確地重建。這種方法的時間和空間複雜度都為 O(n),適合處理大規模的二元樹數據。
以上是第二十六天的自學內容分享,謝謝大家。

 iThome鐵人賽
iThome鐵人賽