在深度學習的網路架構中,主要由三個部分組成:Backbone、Neck、Head。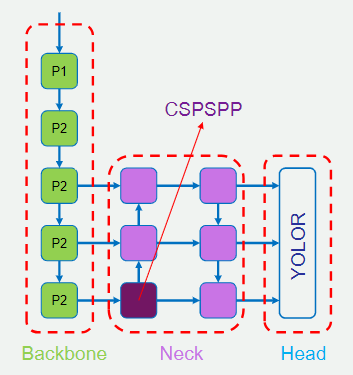
Backbone 是網路架構中的骨幹,負責提取特徵,也就是從輸入圖片中獲取資訊。在 Yolov7 中,使用的是 ELAN 和 E-ELAN 來進行特徵提取。
Neck 位於 Backbone 和 Head 之間,負責融合不同尺度的特徵,以便更好地完成 Head 的任務。在 Yolov7 中,使用的是 CSPSPP+(ELAN, E-ELAN) 和 PAN。
為了順利完成所有步驟,建議先掌握以下技術:
首先需要熟悉 Linux 環境,這包括如何在終端上輸入命令,如 cd、ls 這些基本操作,還有如何安裝和更新軟件包。這些操作在安裝 Yolov7 的過程中會經常用到。
我們會用 Git 從 GitHub 上下載 Yolov7 的代碼,所以你需要了解如何使用 git clone 來獲取專案,並知道如何在專案目錄中進行操作。
你需要會使用 Python,特別是如何使用 pip 來安裝套件。還要懂得一些基本的 Python 語法,因為之後的模型訓練和推理都會用到 Python。
Yolov7 是基於 PyTorch 的,所以你需要先了解 PyTorch 框架,特別是如何安裝 PyTorch,以及如何檢查安裝是否支援 GPU,這會直接影響模型運行效率。
如果你有 NVIDIA GPU,我們會用到 CUDA 來加速運算。你需要知道如何確認 CUDA 和 GPU 是否正常運行,以確保模型運行時高效。
了解物件偵測模型的基本原理,例如 YOLO 模型的工作原理,這將有助於你更好地理解 Yolov7 的架構。
建議使用虛擬環境(如 virtualenv 或 conda)來管理 Python 的依賴,以避免不同項目之間的套件衝突。
學會基本的問題排查能力非常重要。如果在安裝過程中遇到依賴包錯誤或版本不兼容問題,你應該知道如何查看錯誤信息並解決問題。
這些技能是學習 Yolov7 安裝和使用過程中的基礎知識。有了這些準備,你將發現整個過程更加順利,並且能更好理解每一步的意義。
我也將會在往後整理相關技術!!!!!
在 Linux 中安裝 Yolov7,需依序執行以下指令:
$ sudo apt update
$ sudo apt install -y python3-pip
$ pip3 install --upgrade pip
$ git clone https://github.com/WongKinYiu/yolov7.git
$ cd yolov7
$ vim requirements.txt
$ sudo apt install -y libfreetype6-dev
$ pip3 install -r requirements.txt
Yolov7 需要至少 4GB 以上的 GPU 來進行推理和訓練,建議在 NVIDIA 驅動和 CUDA 安裝完畢後進行硬體檢查。
確保 Python 的版本在 3.6 以上,否則可能會遇到兼容性問題。
```bash
$ python3 --version
```bash
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
```

訓練資料集分成三個部分:
常使用的分配比例:
沒有絕對的比例,需要透過測試得到精度較高的比例。
訓練資料準備:
標記檔可透過 Labelimg 工具來產生。
框選並標註標籤:
對所有圖片進行框選並為每個物體標註相應的標籤。
標記檔產生:
每一張圖片會生成一個對應的 .txt 檔案,該檔案會儲存該圖片的標籤資訊。
標記檔內容格式:
以下圖為例:
0 表示第 0 個標籤(類別)多標籤支持:
一張圖片中可以有多個標籤,每個物體都可單獨標註並儲存在同一個 .txt 檔案中。
$ sudo apt install labelImg
CMD輸入labelImg
啟動labelImg
$ labelImg
使用Open Dir開啟預訓練的圖片位置
在Change Save Dir執行與Open Dir一樣的動作
按照下圖啟動自動儲存功能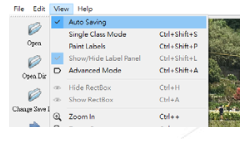
按一下PascalVOC改成下圖YOLO以符合YOLO的標籤格式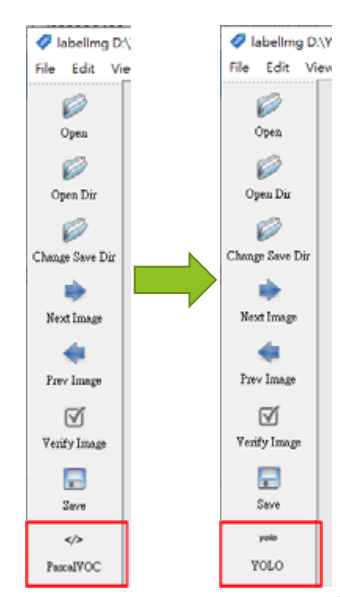
按下Create RectBox框選預辨識的位置,會跳出預定義的Label清單,也就是剛剛我們輸入至predefined_classes.txt的標籤
將所有圖片都框選並標註標籤
這時每一張圖片會產生1個txt,裡面會儲存圖片標籤的訊息
Monkey, Cat and Dog detection
https://www.kaggle.com/datasets/tarunbisht11/yolo-animal-detection-small?resource=download
這個資料集的標記資料需要轉換成yolo格式可以參考我的另一篇文章
建立一個YAML檔:
內容需要包含
這個yaml檔我建立後放置在yolov7/data/根目錄下:
也可以用原先的coco.yaml來進行修改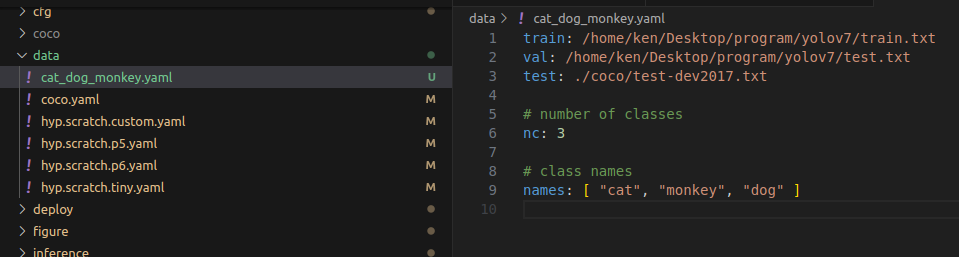
$ python train.py --device 0 --batch-size 8 --data data/cat_dog_monkey.yaml --img 640 --cfg cfg/training/yolov7.yaml --weights yolov7.pt
$ python detect.py --weights /home/ken/Desktop/program/yolov7/runs/train/exp2/weights/best.pt --conf 0.25 --img-size 640 --source /home/ken/Desktop/program/yolov7/monkey/monkey.png

在原始的 GitHub 網頁中,有非常詳細的 YOLOv7 使用教學,而本文只是簡單地示範如何快速搭建 YOLOv7 以進行分類任務。這是一個入門級的教學,目的是讓讀者能夠快速上手。然而,YOLOv7 的設置中還有許多可調整的參數與細節,這些內容可以在 cfg/training/yolov7.yaml 文件中找到。該配置文件中包含了關於訓練模型的各種選項,例如學習率、batch size、網絡架構等。根據不同的應用場景,這些參數可以進行靈活的調整,以優化模型性能。
https://github.com/WongKinYiu/yolov7
 kxkken
kxkken

 iThome鐵人賽
iThome鐵人賽