https://github.com/yu-ken0207/PascalVOCtoYolo
在訓練 YOLO(You Only Look Once)模型時,產生 train.txt 和 val.txt 這樣的檔案是非常重要的
主要是用來指示 YOLO 模型在哪裡找到訓練和驗證數據集的圖像和標註。
這些檔案包含了圖像文件的路徑,它們是 YOLO 訓練過程中的關鍵部分
訓練 YOLO 模型時,我們通常會有大量的圖像和相對應的標註(例如標註文件如 .txt 或 .xml 文件)。這些圖像和標註文件需要按照特定的路徑和格式來組織,以便 YOLO 訓練程式能夠正確讀取和加載數據。
import os
import random
os 模組:提供與作業系統互動的功能,特別是文件和目錄操作,例如列出檔案列表和組合路徑。
random 模組:用於隨機操作,例如打亂數據。這裡用來隨機打亂圖像文件的順序,以確保訓練和驗證集是隨機分配的。
dataset_folder = '/home/ken/Desktop/program/yolov7/yolo-animal-detection-small/test/'
dataset_folder:設定圖像文件所在的資料夾路徑。這個路徑指向存放所有 .jpg 格式圖像的資料夾。
image_files = [os.path.join(dataset_folder, f) for f in os.listdir(dataset_folder) if f.endswith('.jpg')]
os.listdir(dataset_folder):列出資料夾中所有的文件和子目錄。
if f.endswith('.jpg'):過濾出副檔名為 .jpg 的文件,這些文件將被認為是圖像文件。
os.path.join(dataset_folder, f):將檔案名 f 和 dataset_folder 路徑組合成圖像的完整路徑。
最終,image_files 是一個包含所有圖像文件完整路徑的列表。
random.shuffle(image_files)
split_idx = int(0.8 * len(image_files))
train_files = image_files[:split_idx]
val_files = image_files[split_idx:]
random.shuffle(image_files):隨機打亂圖像文件列表,這樣可以確保分配的訓練和驗證數據集是隨機的。
split_idx = int(0.8 * len(image_files)):計算訓練集的索引位置,這裡選擇了 80% 的圖像用作訓練數據,剩餘 20% 的圖像作為驗證數據。
train_files = image_files[:split_idx]:前 80% 的圖像分配給訓練集。
val_files = image_files[split_idx:]:後 20% 的圖像分配給驗證集。
with open('test.txt', 'w') as train_f:
for file in train_files:
train_f.write(f"{file}\n")
open('test.txt', 'w'):打開 test.txt 文件並以寫入模式('w')開啟。如果文件不存在,則會創建新文件。
for file in train_files:迭代 train_files 列表中的每一個圖像文件。
train_f.write(f"{file}\n"):將每個圖像文件的路徑寫入文件中,並在每行的末尾添加一個換行符 \n。
需要注意的是,這裡寫入的是 test.txt 而不是 train.txt,應該根據需要修改為 train.txt。
with open('val.txt', 'w') as val_f:
for file in val_files:
val_f.write(f"{file}\n")
open('val.txt', 'w'):打開 val.txt 文件並以寫入模式開啟,將驗證集的文件路徑寫入其中。
val_f.write(f"{file}\n"):將每個驗證集圖像文件的路徑寫入 val.txt,每行一個路徑。
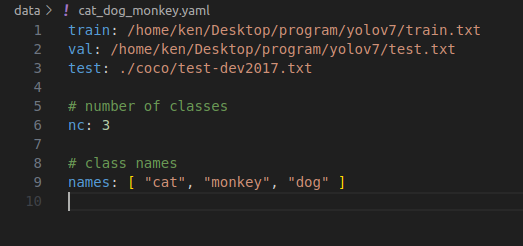
python train.py --device 0 --batch-size 8 --data data/cat_dog_monkey.yaml --img 640 --cfg cfg/training/yolov7.yaml --weights yolov7.pt
 kxkken
kxkken
