在前一篇文章中,我們概述了 AlertSnitch 的功能和應用場景,特別是在告警歷史可視化中的重要性。後來有好幾個小夥伴紛紛表示對 AlertSnitch 與 Loki、Grafana 的整合很有興趣,這也讓我想在特地為 AlertSnitch 搭配 Loki 的絕配組合寫一篇安裝指引。這篇文章將探討其架構設計、組件功能,以及如何在實際環境中進行安裝與配置,幫助各位快速上手。
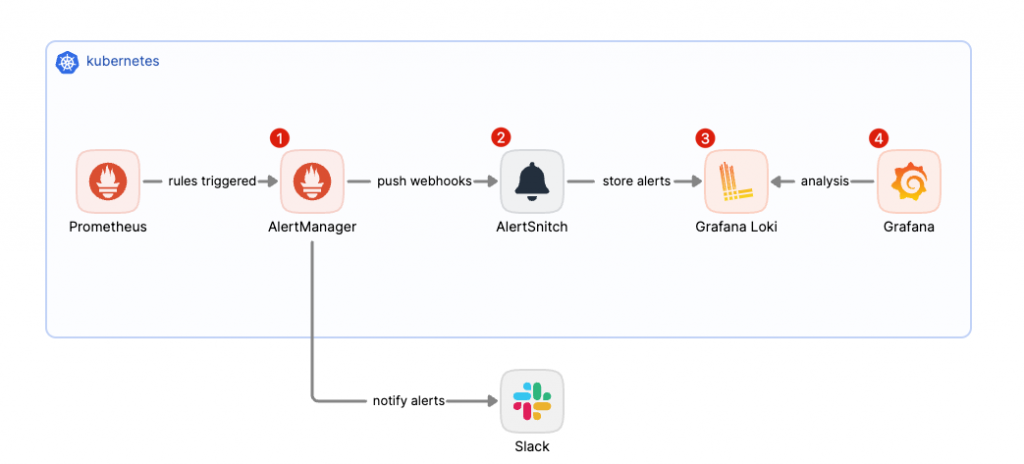
相信大家在看到上面的架構圖時,應該已經注意到 AlertSnitch 是實現告警事件資訊持久化的關鍵角色。它負責將告警資訊儲存於 Grafana Loki,並透過 Grafana 進行告警歷史的查看與分析,這與原本 Prometheus → AlertManager → Slack 或其他通知目的地的流程有很大不同。
AlertManager 的核心職能是處理告警路由的相關任務,包括告警的去重、分組與抑制等功能,但它並不具備持久化存儲或分析告警資訊的能力。這樣的設計使得 AlertManager 能保持簡單、高效與穩定的特性。因此,為了補足這一缺陷,我們需要引入 AlertSnitch,幫助我們實現對告警歷史的存儲與分析功能。
有興趣的小夥伴可以參考我的這篇 AlertManager 介紹。
首先,我們第一步需要安裝 AlertSnitch 專案,並且使用 AlertSnitch for Loki 現成設定檔:
git clone git@github.com:MikeHsu0618/alertsnitch.git
接下來,我們來看看如何配置 Grafana Loki,然後繼續安裝並配置 AlertSnitch。
Note:本篇教學的運作環境將以 Kubernetes 為主,因此需要具備基本的 Kubernetes 和 Helm 使用經驗,以及對 Grafana Stacks 概念的理解。如果對這些關鍵字還不熟悉的朋友,可以參考我之前撰寫的 Kubernetes 和 Grafana Stacks 入門系列文。
AlertManager 作為接收 Prometheus Rule 告警的端點並進行分派的角色,允許我們配置告警接收者(receivers)以及使用 Labels 制定各種路由策略。因此,我們需要在 AlertManager 中為 AlertSnitch 分別配置相關的 routes 和 receivers 欄位,以確保告警能正確傳遞並處理。
# config.yaml
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: team-X-mails
routes:
- matchers:
- alertname =~ "InfoInhibitor|Watchdog"
receiver: "null"
- receiver: alertsnitch
continue: true
- matchers:
- service=~"foo1|foo2|baz"
receiver: team-X-mails
...
receivers:
- name: 'team-X-mails'
email_configs:
- to: 'team-X+alerts@example.org'
- name: alertsnitch
webhook_configs:
- url: http://localhost:9567/webhook?source=alertsnitch
在這段配置中,我們可以注意到一些設計巧思:
Routes 的匹配順序與 continue 設定
Routes 是按照順序從上至下進行匹配的,並在匹配到條件後執行相應的接收者(receiver)。為了讓 AlertSnitch 能夠實現持久化存儲而不影響原有的告警通知,我們將 AlertSnitch receiver 放在靠前的位置,並設置 continue: true,使告警可以繼續向下匹配其他規則。
在這裡,我們注意到 AlertSnitch receiver 被放在第二條匹配規則中,而不是第一條。這是因為第一條規則針對的是 InfoInhibitor 和 Watchdog,這些是 Prometheus 的內建告警,用於監控 AlertManager 本身的健康狀態,通常不需要持久化或特別處理,因此可以直接忽略。
Receivers 的 Webhook 配置
在 receivers 的配置中,alertsnitch receiver 使用了一個帶有 query string 的 Webhook URL,例如:
http://localhost:9567/webhook?source=alertsnitch
這種設計支持將靜態 Label 作為參數傳遞,便於在寫入 Loki 時標記來源,如:{source="alertsnitch"}。如此一來,當需要將來自多個 AlertManager 的告警集中存儲於一個中心化的 Loki 集群時,這樣的設計可以幫助我們有效區分不同的告警來源,避免數據混淆。
從現在開始,我們將快速在 Kuberentes 環境中建立起一個完整的 AlertSnitch 所需的最低要件。首先我們需要建立一個讓 AlertSnitch 持久化告警訊息的儲存後端。
helm upgrade --install loki grafana/loki --version 6.21.0 -n loki --create-namespace -f values.yaml
----
Release "loki" does not exist. Installing it now.
NAME: loki
LAST DEPLOYED: Sun Dec 22 22:39:49 2024
NAMESPACE: loki
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to Grafana Loki
Chart version: 6.21.0
Chart Name: loki
Loki version: 3.3.0
***********************************************************************
** Please be patient while the chart is being deployed **
Tip:
Watch the deployment status using the command: kubectl get pods -w --namespace loki
If pods are taking too long to schedule make sure pod affinity can be fulfilled in the current cluster.
***********************************************************************
Installed components:
***********************************************************************
* gateway
* minio
* compactor
* index gateway
* query scheduler
* ruler
* distributor
* ingester
* querier
* query frontend
在這裡我們可以注意到我們特地將 Loki 的 max query series 設定調整到比原本 500 更大的值,主要是為了滿足 loki query 統計告警訊息後的大量時序資料。
loki:
limits_config:
max_query_series: 100000
對於大範圍、多告警紀錄進行分析時,原本的 500 條 series 的保守限制很容易觸發上限,影響分析結果,所以調高 max_query_series 可以確保我們處理更大的告警資料。
在AlertSnitch 的環境參數中,我們可以看到儲存後端的相關設定,特別是這裡還支持了 Loki 多租戶功能。而啟動 AlertSnitch 的唯一必要條件是成功與一個儲存後端綁定,例如 Grafana Loki、MySQL 或 PostgreSQL。
# helm/alertsnitch/values.yaml
fullname: alertsnitch
image:
repository: mikehsu0618/alertsnitch
pullPolicy: IfNotPresent
tag: "latest"
service:
type: ClusterIP
port: 9567
env:
ALERTSNITCH_ADDR: ":9567"
ALERTSNITCH_DEBUG: "true"
ALERTSNITCH_BACKEND: "loki"
ALERTSNITCH_BACKEND_ENPOINT: "http://loki-gateway.loki"
ALERTSNITCH_LOKI_TENANT_ID: ""
沒問題的話,我們就能夠開始進行安裝:
helm upgrade --install alertsnitch ./ -n alertsnitch --create-namespace
---
Release "alertsnitch" does not exist. Installing it now.
NAME: alertsnitch
LAST DEPLOYED: Sun Dec 22 22:42:00 2024
NAMESPACE: alertsnitch
STATUS: deployed
REVISION: 1
TEST SUITE: None
完成後,我們將可以看到順利連接 database 的相關 log。
Connected to database
2024/12/22 14:57:31 Starting listener on :9567
如果你的 Loki 是剛建立出來還沒有寫入任何資料時,將會導致 AlertSnitch 將無法判定其為健康狀態。而這時我們可以簡單的手動寫入一筆資料到 Loki 來解決:
curl -H "Content-Type: application/json" -XPOST -s "http://127.0.0.1:3100/loki/api/v1/push" \
--data-raw "{\"streams\": [{\"stream\": {\"job\": \"test\"}, \"values\": [[\"$(date +%s)000000000\", \"fizzbuzz\"]]}]}"
到此,我們已經大略完成了運作起 AlertSnitch 的最低要件了,接下來我們將透過實戰演練來體驗 AlertSnitch 的強大之處。
在實戰演練的部分,我們將利用 K6 產生如下所示的 AlertManager 告警訊息內容,並且對 AlertSnitch 發出請求,模擬現實情況各種不同狀態的告警 firing、resolved 等狀態紀錄,並且在 Grafana 介面中實現告警歷史分析可視化。
{
"receiver": "webhook",
"status": "firing",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "Test",
"dc": "eu-west-1",
"instance": "localhost:9090",
"job": "prometheus24"
},
"annotations": {
"description": "some description"
},
"startsAt": "2018-08-03T09:52:26.739266876+02:00",
"endsAt": "0001-01-01T00:00:00Z",
"generatorURL": "http://example.com:9090/graph?g0.expr=go_memstats_alloc_bytes+%3E+0\u0026g0.tab=1"
}
],
"groupLabels": {
"alertname": "Test",
"job": "prometheus24"
},
"commonLabels": {
"alertname": "Test",
"dc": "eu-west-1",
"instance": "localhost:9090",
"job": "prometheus24"
},
"commonAnnotations": {
"description": "some description"
},
"externalURL": "http://example.com:9093",
"version": "4",
"groupKey": "{}:{alertname=\"Test\", job=\"prometheus24\"}"
}
如果還沒有安裝 K6 的話可以透過 brew 指令快速安裝:
brew install k6
在專案中 K6 的現成腳本中,我們只需要指定到我們的 AlertSnitch 端點就能輕鬆產生告警資料:
# generator.js
const ALERTSNITCH_URL = 'http://localhost:9567/webhook';
const res = http.post( ALERTSNITCH_URL, JSON.stringify(payload), {
headers: { 'Content-Type': 'application/json' },
});
接著執行指令就能產生 AlertManager 告警資訊請求:
k6 run k6/generator.js
---
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: k6/generator.js
output: -
scenarios: (100.00%) 1 scenario, 1 max VUs, 10m30s max duration (incl. graceful stop):
* default: 30 iterations shared among 1 VUs (maxDuration: 10m0s, gracefulStop: 30s)
running (00m03.3s), 0/1 VUs, 30 complete and 0 interrupted iterations
default ✓ [======================================] 1 VUs 00m03.3s/10m0s 30/30 shared iters
接著就讓我們來安裝 Grafana 並且載入特製的 Dashboard 來體驗 AlertSnitch 為我們帶來的可視化資訊。
helm upgrade --install grafana grafana/grafana --version 8.6.4 -n grafana --create-namespace -f values.yaml (orbstack/default)
Release "grafana" does not exist. Installing it now.
NAME: grafana
LAST DEPLOYED: Sun Dec 22 23:20:54 2024
NAMESPACE: grafana
STATUS: deployed
REVISION: 1
安裝 Grafana 後就讓我們登入其中(預設帳號密碼皆為 admin),載入 AlertSnitch Dashboard 的 ID 22488:
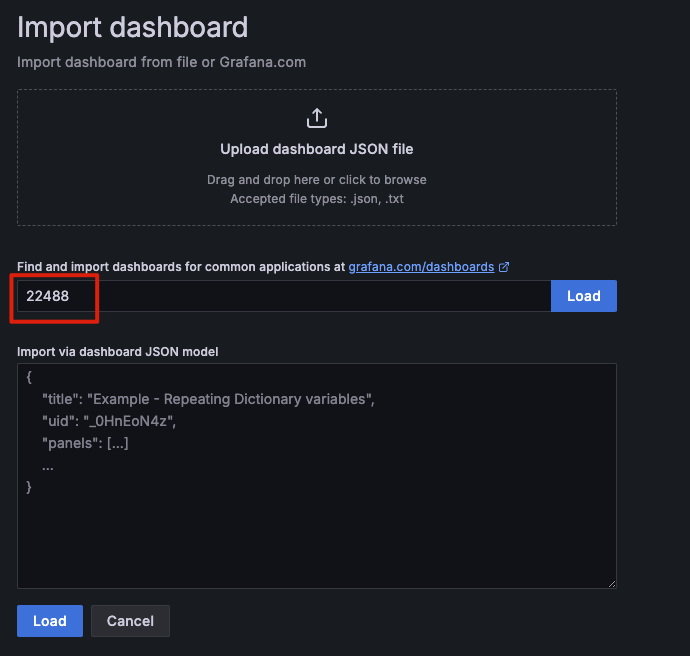
載入後,我們的 AlertSnitch 替我們儲存在 Loki 的各種告警歷史都會被呈現出來。
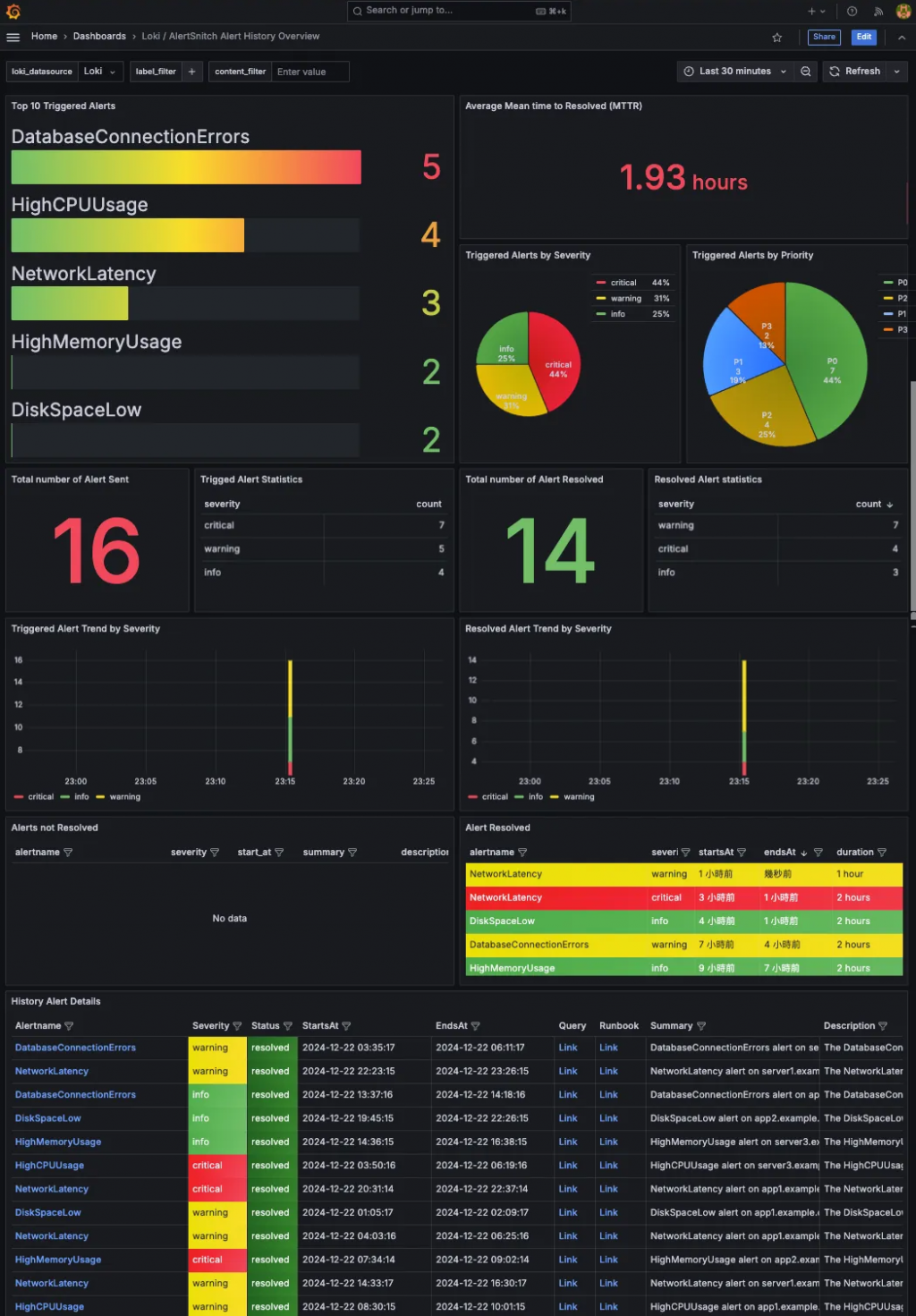
得益於 Grafana 和 Loki 的靈活特性,我在設計這張 Dashboard 時,充分結合了兩者的優勢,創造出了一些有趣且實用的使用者體驗:
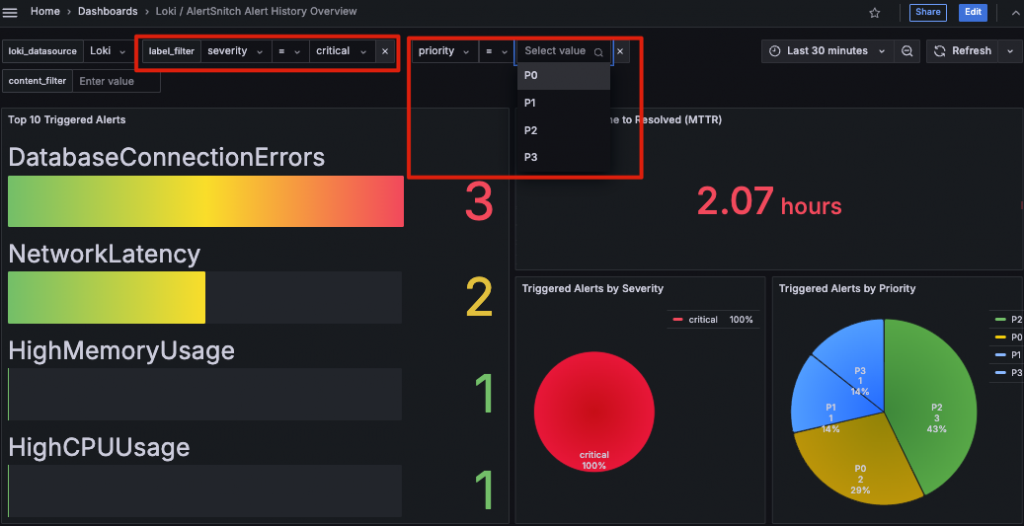
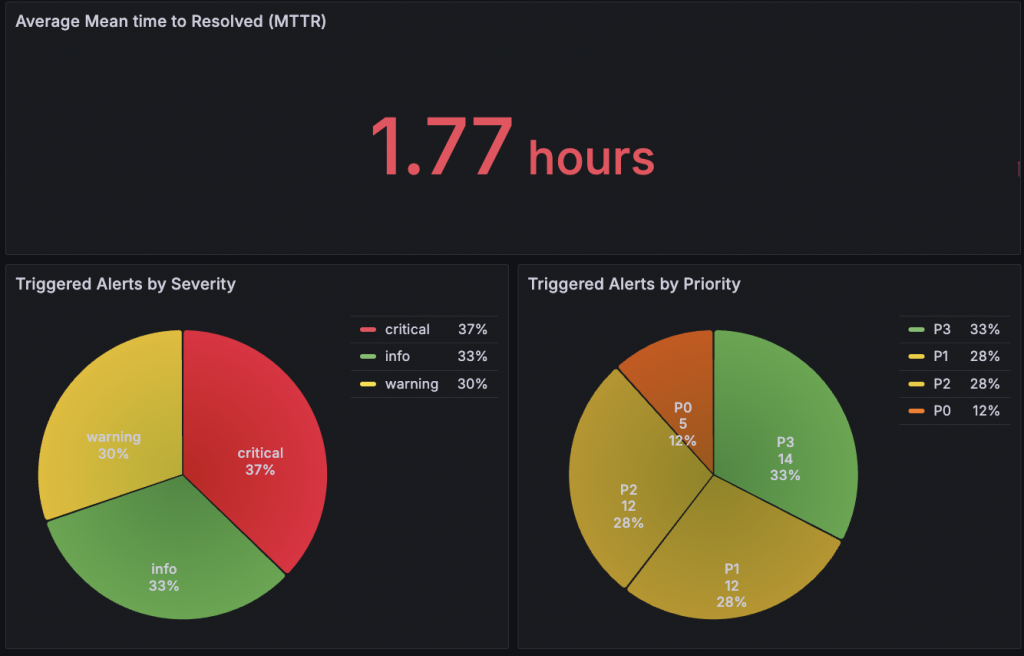
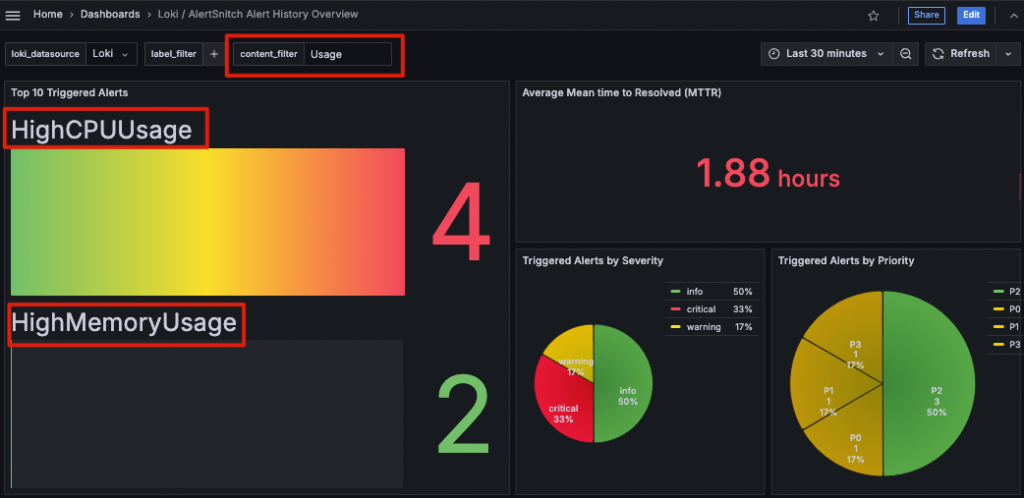
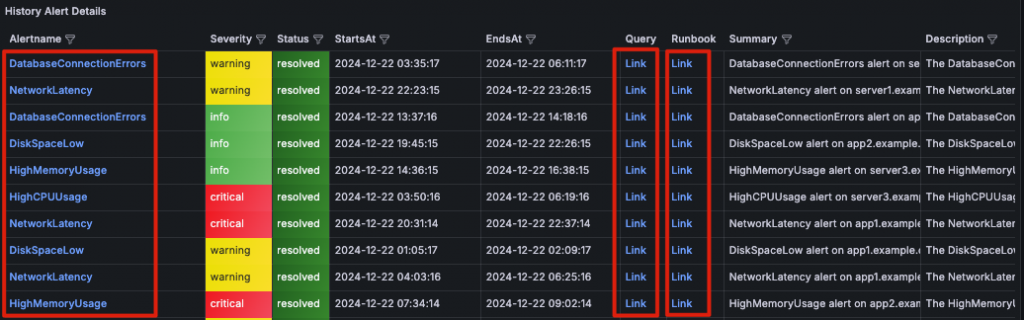
至此,我們已經從零開始成功打造了 AlertSnitch for Loki 的完整服務,並實現了其在分析告警歷史中的實際應用。
在 AlertSnitch 的實踐中,我們不僅實現了對 Grafana 和 Loki 的深度整合,更重要的是成功將那些原本「閱後即忘」的告警資訊轉化為有價值的洞見。這些被忽視的數據,透過 AlertSnitch 的整理與分析,讓我們得以重新審視告警的模式與趨勢,進一步優化系統穩定性與運維效率。
目前,我們主要利用 Grafana 原生的 Panel 來呈現這些告警資訊,通過靈活的查詢與可視化功能,快速了解系統的運行情況。然而,這僅僅是個開始,未來我們可以進一步打造專屬於 AlertSnitch 的 Grafana App,將告警數據的管理與分析功能提升到全新的層次。這不僅能提供更直觀的告警歷史視圖和報表,還能結合自動化的分析與建議,幫助我們更高效地處理告警並持續改進服務的可靠性。AlertSnitch 的潛力,遠不止於此,而是為告警數據帶來更多可能性和價值。


