在Deadlock Prevention(死結預防) 中,系統一開始就會硬性規定執行緒的資源請求方式,以破壞四大死結條件之一,雖然安全但保守,會浪費資源。而再死結避免(Deadlock Avoidance)上,這是一種動態且更彈性的策略。系統在每次資源請求時,都會進行安全檢查,只有在確認分配後系統仍處於安全狀態時,才會同意該請求。這種方法允許更高的資源利用率,但需要更多關於執行緒未來資源需求的資訊。
簡單來說,在安全狀態下,系統總能找到一條「不發生死結」的執行路徑,即使當前的資源分配看起來很緊張。安全狀態是死結避免的核心。一個系統處於安全狀態,意味著存在一個安全序列,其中所有執行緒都能依次順利完成其任務,保證不會發生死結。安全序列:一個由所有執行緒組成的序列,滿足以下條件:對於序列中的每個執行緒,它目前額外需要的資源,都能從所有在它之前完成的執行緒所釋放的資源中獲得。
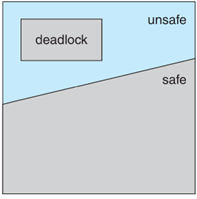
理解死結避免,必須先分清楚這三種狀態:安全狀態、不安全狀態與死結狀態。死結避免的目標就是確保系統永遠不會從安全狀態進入不安全狀態。
這邊的演算法我自己也認為表達得不太好,在上作業系統的同學可以自行再去Youtube尋找相關教學。
資源配置圖演算法主要針對每種資源只有一個實例的情況。它透過在資源配置圖上新增虛擬的「請求邊(Request Edge)」來預測未來。
當執行緒請求資源時,系統會先在圖中繪製一條虛擬的「請求邊」。接著,它會檢查如果將這條邊轉換成實際的「分配邊」,是否會導致圖中出現循環。如果會,則表示這個請求會將系統帶入不安全狀態,因此拒絕;如果不會,則同意分配。
優點是 簡單直觀,計算效率高。
缺點是只能處理單一實例的資源,通用性較差。
銀行家演算法是死結避免最著名的演算法,可以處理有多個資源實例的情境。它的概念就像銀行家發放貸款,必須確保所有客戶(執行緒)最終都能「償還」貸款(完成任務),才同意新的借貸。
運作原理:
優點是適用於多實例資源,資源利用率高。
缺點是需要預先知道每個執行緒的最大資源需求量,這在實際應用中可能很難實現。每次請求都需要執行複雜的安全性演算法,計算開銷較大。
安全狀態演算法是銀行家演算法的「核心檢查機制」。
銀行家演算法是一個宏觀的決策流程,負責處理每次資源請求。它會先檢查目前系統的可用資源、每個執行緒的最大需求量、已分配量等資訊。
安全狀態演算法是銀行家演算法中一個獨立的子程序。當銀行家演算法需要判斷「如果我現在同意這個請求,系統會不會進入安全狀態?」時,它就會呼叫安全狀態演算法來執行這項檢查。
前面章節所討論的死結預防(Prevention)和死結避免(Avoidance)都是「事前」預防的策略。然而,在某些追求高效率或簡化設計的系統中,為了避免額外的檢查開銷,系統可能選擇不進行預防,而是等到死結「真的發生時」再進行處理。這就是 死結復原(Deadlock Recovery) 的核心思想。死結復原的目標是在最小化系統損失的前提下,將系統從死結狀態中解救出來,使其恢復正常運作。主要有兩種常見的復原方法:終止程序和資源搶回。
這是最直接、最簡單的復原方法,透過終止(Kill)參與死結的執行緒來破壞循環等待條件。這種方法又可以細分為兩種:
第一種是全部終止(Kill All Involved Processes):
一次只終止一個參與死結的執行緒,然後立即重新執行死結檢測。如果死結解除,則停止終止;如果死結依然存在,則繼續終止下一個,直到死結被完全解除。優點是簡單粗暴,保證有效,實作成本低。缺點是因為所有相關的計算進度都將付諸東流,會導致大量的資源浪費和資料遺失風險,代價極高。
第二種是逐一終止(Partial Termination):
一次只終止一個參與死結的執行緒,然後立即重新執行死結檢測。如果死結解除,則停止終止;如果死結依然存在,則繼續終止下一個,直到死結被完全解除。相較於一次全部終止,這種方式能最大程度地保留計算成果,減少系統的損失。但每次終止後都需要重新進行死結檢測,會產生額外的效能開銷。而且,選擇終止哪一個執行緒會直接影響恢復的效率,需要一個合理的「受害者選擇」策略。
資源搶回是一種相對溫和的復原方式,它不終止執行緒,而是透過強制釋放部分資源來打破死結。這個方法包含三個關鍵步驟:
| 項目 | 終止程序 | 資源搶回 |
|---|---|---|
| 方式 | 殺掉執行緒 | 把資源搶回來 |
| 破壞性 | 較高(終止計算) | 較低(可繼續執行) |
| 實作成本 | 較簡單 | 較高(需 rollback 機制) |
| 資料遺失 | 有可能 | 較少 |
| 是否需要選擇受害者 | ✅ | ✅ |
| 是否需要避免飢餓 | ❌ | ✅(可能重複搶同一人) |
| 是否需存還原點 | ❌ | ✅(進行 rollback) |


 iThome鐵人賽
iThome鐵人賽