在現代作業系統中,硬碟排程(HDD Scheduling)是儲存效能優化的關鍵一環。雖然 SSD 已逐漸普及,但瞭解 HDD 背後的排程邏輯,對理解作業系統運作仍然非常重要,尤其在學術與教學場域。
作業系統在控制 HDD 存取時,主要有兩大目標:
| 項目 | 說明 |
|---|---|
| Seek Time | 磁頭從目前位置移動到目標磁軌(Cylinder)的時間 |
| Rotational Latency | 磁碟旋轉至目標資料所在的 sector 所需時間(平均半圈) |
| Bandwidth | 傳輸總資料量 ÷ 處理整批請求所需的總時間 |
在多工環境下,作業系統會同時收到來自不同行程(Process)的大量磁碟 I/O 請求。如果完全不加管理,直接按照請求的先後順序處理,磁頭可能會像無頭蒼蠅一樣在磁碟的兩端來回奔波,導致大量的 Seek Time,使系統效能急遽下降。因此,作業系統需要一套有效的硬碟排程演算法 (Disk Scheduling Algorithm) 來決定下一個要處理的 I/O 請求是哪一個,核心目標就是最佳化磁頭的移動路徑。
為了方便說明,我們假設以下情境:
這是最直觀也最簡單的演算法,完全按照請求到達的順序來處理。

這個演算法會選擇下一個與磁頭目前位置「最近」的請求來處理。
邏輯: 貪心法 (Greedy Algorithm),每次都走最短的路。
路徑:
SCAN 演算法模擬了電梯的運作模式。磁頭會從一端開始,朝著一個方向移動,處理沿途所有的請求,直到到達該方向的盡頭,然後再掉頭反向移動。
邏輯: 像電梯一樣,單向服務,避免來回跳動。
假設磁頭初始方向: 朝磁軌號碼大的方向移動 (例如:朝 199 移動)。
路徑:
優點:
缺點:
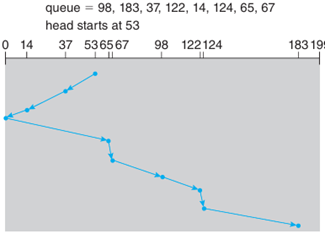
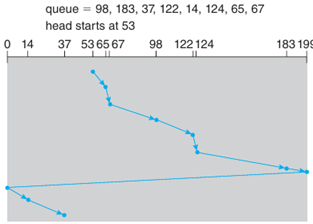
C-SCAN 是對 SCAN 的改良,旨在提供更平均的等待時間。
隨著技術演進,非揮發性記憶體(NVM),特別是固態硬碟(SSD),已成為現代電腦系統的主流儲存方案。其排程策略與傳統硬碟(HDD)截然不同,主要源於其獨特的物理特性。
首先,NVM 裝置最大的特點是無機械構造。它內部沒有旋轉的碟盤或移動的磁頭,因此不存在傳統硬碟的搜尋時間(Seek Time)與旋轉延遲(Rotational Latency)問題。這意味著存取任何位置的資料,其延遲時間都相對一致。
其次,這個特性帶來了高速隨機存取的優勢。NVM 裝置能夠提供極高的每秒讀寫次數(IOPS),其隨機存取性能遠遠超過傳統硬碟,使得處理零碎檔案或大量小檔案的效率大幅提升。
最後,基於上述兩點,NVM 的排程策略也趨於簡單化。由於搜尋延遲不再是效能瓶頸,複雜的排程演算法(如 SCAN 或 C-LOOK)失去了意義。因此,現代作業系統在面對 NVM 裝置時,多半採用最直觀的 FCFS(先來先服務)排程策略,直接按照請求的先後順序進行處理,這樣既公平又能有效利用其硬體性能。
雖然 NVM 存取快速,但其寫入行為仍然面臨一些挑戰。首先,快閃記憶體(Flash Memory)的物理特性決定了其讀取速度比寫入速度快。寫入操作需要先將整個區塊(Block)的資料擦除後才能寫入新的資料,這個過程比直接讀取耗時許多。
其次,裝置的寫入效能會隨著使用而下降。快閃記憶體的儲存單元有其壽命限制,尤其是區塊的擦除次數是有限的,過度使用會導致其逐漸耗損。
因此,在設計 NVM 的寫入機制時,必須周全地考慮三件事。第一是 Erase 限制,資料必須以整個區塊為單位進行擦除。第二是 Wear Leveling(損耗均衡),需要透過演算法將寫入操作平均分散到裝置的所有區塊上,避免某些區塊因過度使用而提早損壞。第三是 Garbage Collection (GC)(垃圾回收),當裝置空間不足時,需要搬移有效的資料並重整區塊,這個過程會額外耗費效能,造成短暫的延遲。
所謂「寫入放大」,指的是使用者或作業系統發出的一次簡單寫入請求,可能導致儲存裝置在內部進行多次額外的讀寫操作。這種現象是控制 NVM 效能與壽命的關鍵,尤其在觸發垃圾回收或資料搬移時最為明顯。
其流程大致如下:當系統嘗試寫入新資料時,若目標區塊已滿,便會啟動垃圾回收機制。首先,控制器會讀出該區塊中仍然有效的資料,然後將這些資料搬移到一個預留的空白區塊(這個區域稱為 Over-Provisioning)。接著,控制器會清除整個舊區塊,最後才將使用者最初要寫入的新資料寫入到一個乾淨的區塊中。
最終結果是,一次看似單純的寫入請求,在裝置內部卻觸發了多次讀取、搬移和寫入。這種放大的寫入量不僅增加了延遲,也加速了快閃記憶體的耗損。因此,如何有效控制寫入放大,是 SSD 韌體中快閃記憶體轉換層(FTL)設計的核心重點之一。
NVM 裝置,特別是快閃記憶體,在長時間使用後可能因為物理耗損或外部干擾而發生資料錯誤。這些錯誤主要分為兩類。
第一類是 Transient Error(軟性錯誤),這類錯誤是偶發且非永久性的,例如因為電磁干擾或宇宙高能粒子撞擊導致的位元翻轉(bit flip)。
第二類是 Permanent Error(硬性錯誤),這類錯誤通常是永久性的損壞,例如快閃記憶體的儲存單元(cell)因達到抹寫壽命上限而老化,或發生其他無法修復的硬體故障。
為了應對這些問題,NVM 裝置內部整合了多種解決方式。常見的是 ECC(Error Correction Code),例如漢明碼(Hamming Code)或 LDPC 碼,這類演算法可以在一定範圍內自動偵測並修正資料錯誤。此外,也會使用 CRC(Cyclic Redundancy Check)來進行循環冗餘校驗,以確保資料在傳輸或儲存過程中的完整性與正確性。
一個新的儲存裝置從出廠到能夠被作業系統使用,需要經過一系列的管理與設定程序。
低階格式化也稱為物理格式化,這個步驟主要是將儲存裝置的物理媒介劃分為一個個可供控制器操作的基本單位。對於傳統硬碟,這個單位是 Sector(磁區);對於固態硬碟,這個單位則是 Page(頁面)。
每個儲存單位都包含固定的結構。最前端是 Header(標頭),用於儲存標記、位址等控制資訊;中間是 Data Area(資料區),用於存放使用者實際的資料;尾端則是 Trailer(結尾),通常含有 ECC 或 CRC 這類用於錯誤校驗的編碼。低階格式化通常由硬體製造商在工廠端完成,一般使用者或作業系統不會主動執行這個操作,除非使用特殊的工具來強制重建裝置的底層結構。
邏輯格式化又稱為高階格式化,這個步驟由作業系統負責執行,其目的是在儲存裝置上建立檔案系統所需的資料結構。這些結構包括用於記錄檔案存放位置的檔案表、呈現資料夾層級的目錄結構,以及追蹤可用空間的空間配置資訊。不同的作業系統使用不同的檔案系統。例如,Windows 系統常用的有 NTFS、exFAT 或 FAT32;而 Linux 系統則常用 ext4、XFS 或 Btrfs。透過邏輯格式化,作業系統才能夠理解並管理這個磁碟上存放的資料。
分割是將一顆實體磁碟劃分成多個獨立邏輯區段的過程,每一個區段(Partition)都可以被作業系統看作一顆獨立的小磁碟來使用。
分割有多種實際用途。例如,可以將系統檔案儲存在一個分割區(如 Windows 的 C: 槽或 Linux 的 / 根目錄),將使用者資料放在另一個分割區(如 /home),並劃分專門的空間作為 Linux 的虛擬記憶體(Swap),或存放開機引導程式(/boot)。
一個重要的概念是,一個分割區通常對應一個檔案系統。在更複雜的 RAID 磁碟陣列系統中,一個邏輯儲存區域甚至可以橫跨多顆實體的硬碟。
「掛載」是讓一個已經格式化好的檔案系統能夠被作業系統存取並使用的最後一個步驟。
Windows 的掛載方式相當直觀,它透過磁碟代號(如 C:, D:)來代表每一個分割區,每個分割區都是一個獨立的路徑起點。
Linux 的掛載方式則採用統一的樹狀目錄結構。所有的儲存裝置,無論是硬碟、USB 隨身碟或網路磁碟,都必須被「掛載」到根目錄(/)之下的某個指定目錄(稱為掛載點)才能存取。例如,執行指令 mount /dev/sdb1 /mnt/usb,就是將 /dev/sdb1 這個裝置的檔案系統連接到 /mnt/usb 這個目錄上,之後使用者就能透過存取 /mnt/usb 來讀寫該裝置上的檔案。
除了管理儲存裝置本身的內部結構,例如進行格式化、分割與掛載等操作外,作業系統還必須處理一個更根本的問題:儲存裝置是如何連接到系統上的。不同的連接方式決定了資料的存取速度、共享能力與管理複雜度。
這是最傳統也最常見的儲存方式。它的定義是儲存裝置透過本機的 I/O 介面直接連接在主機上。我們日常使用電腦時,內部的硬碟或外接的隨身碟都屬於此類。
常見的連接介面非常多樣,例如用於連接內部 HDD 或 SSD 的 SATA 與 SAS 介面;用於連接外接硬碟或隨身碟的 USB 與 Thunderbolt 介面;以及一些較舊設備會使用的 FireWire 或 IDE 介面。此外,光碟機如 CD、DVD 或藍光,以及用於備份的磁帶機,甚至是企業級的儲存區域網路(SAN),在本質上也屬於主機直連的範疇。
在這種連接模式下,作業系統會以邏輯資料區塊(Logical Block)的單位來對裝置進行識別與存取,通常會使用匯流排 ID(bus ID)或邏輯單元編號(LUN)來定位裝置。
這種方式的優點在於其存取速度非常快,因為資料傳輸無需經過網路,延遲極低。同時,它的架構簡單,設定也相當容易,基本上是隨插即用。然而,它的缺點也十分明顯。資料僅限於連接該裝置的主機可以存取,形成了一個資訊孤島。因此,它無法輕易地將儲存空間共享給多台電腦或多位使用者,協同作業能力較差。
網路附加儲存,也就是我們常說的 NAS,是為了解決主機直連儲存共享不便的問題而生的設備。你可以將它想像成一台專門用來透過網路提供檔案存取服務的迷你伺服器。NAS 設備通常透過區域網路(LAN),例如乙太網路(Ethernet),連接到家裡或公司的路由器上。它可以支援多種網路檔案分享協定,如 NFS、SMB 或 AFP,這使得 Windows、macOS 和 Linux 等不同作業系統的裝置都能夠順利地存取其中的資料,允許多位使用者同步使用。
NAS 的主要優點是支援多台裝置方便地共享檔案。管理者可以設定不同的使用者帳號,讓每個人登入後都能存取自己的專屬目錄與共享資料夾。這使得它非常適合中小企業作為檔案伺服器,或是在家庭環境中進行跨裝置的資料同步與備份。相對地,它的缺點在於存取效能會受到網路頻寬與延遲的限制。如果區域網路不穩定或速度慢,檔案傳輸就會受到影響。此外,資料的同步與使用者權限管理需要進行額外的後台設定。
常見的應用包括家用市場知名的 QNAP、Synology 等品牌,用於集中管理家庭照片、影音檔案;在企業中則作為部門的檔案共享伺服器;它也常用於蘋果時光機(Time Machine)的網路備份,或是儲存攝影監控系統的錄影存檔。
雲端儲存可以看作是 NAS 的一種進化形式,它將資料共享的概念從區域網路擴展到了整個網際網路。與 NAS 的核心差異在於,資料不再存放在你家中的實體設備裡,而是被上傳並存放於由服務供應商維運的遠端資料中心。使用者透過廣域網路(WAN),也就是網際網路,來存取這些資料。市面上有許多知名的雲端儲存服務,例如 Dropbox、Google Drive、OneDrive、Amazon S3 以及蘋果的 iCloud 等。
雲端儲存的最大優點是提供了極致的跨平台與跨地點存取能力。只要裝置能連上網路,無論你身在何處,使用何種設備,都能存取到自己的檔案。它通常具備強大的自動備份與多裝置同步功能,且儲存空間易於擴充,使用者可根據需求訂閱付費來升級容量。不過,它的缺點也與其優勢一體兩面。它完全仰賴網路的穩定性,若沒有網路連線,就無法存取檔案。由於資料需要經由網際網路傳輸,其延遲通常高於區域網路內的 NAS,並且使用者也會對資料的隱私與安全性產生潛在的疑慮。對於需要長時間傳輸大量或大型檔案的場景,其速度可能也較慢。

