嗚呀~今天人在台東,但也不能忘記發文@@
在傳統的連續記憶體配置中,一個完整的程式(或行程)必須被完整地載入到一塊連續的實體記憶體區塊中。當記憶體中的程式不斷進出時,會留下許多大小不一的「小洞」。即使這些小洞的總和空間足夠容納一個新程式,但因為沒有一個單一、連續的大洞,導致新程式無法被載入,這就是外部碎裂。而分頁(Paging)能夠解決外部碎裂(External Fragmentation)的原因,在於它徹底改變了程式在記憶體中存放的方式。
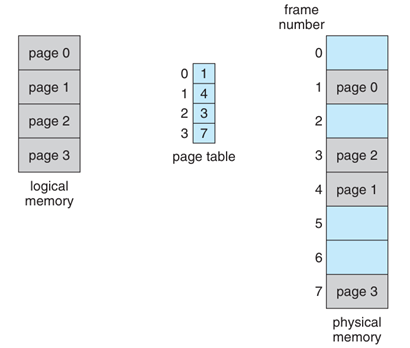
分頁系統則引入了「非連續記憶體配置」的概念。它將程式的邏輯記憶體切成固定大小的頁(Page),並將實體記憶體也切成相同大小的框(Frame)。當程式需要被載入時,它的各個頁可以被分散地載入到實體記憶體中任何可用的框裡,不需要連續排列。這樣一來,無論實體記憶體中的空洞多麼分散,只要能找到足夠多的「框」來存放程式的「頁」,程式就能順利載入。系統不再需要尋找一大塊連續的空間,而是只需要將這些小空洞(框)拼湊起來,這就從根本上消除了外部碎裂的問題。
雖然分頁解決了外部碎裂,但它也可能產生內部碎裂(Internal Fragmentation)。內部碎裂指的是:當記憶體被分配給一個程式時,實際分配的空間比程式所需要的空間還要大,而多出來的這部分空間因為太小,無法被其他程式使用,因此被浪費掉。在分頁系統中,這種情況發生在每個「頁」的最後。因為頁的大小是固定的(例如 4 KB),如果一個程式的大小不是頁大小的整數倍,那麼它的最後一頁就不會被完全填滿。
舉例來說,如果一個程式的大小是 13 KB,而頁的大小是 4 KB:
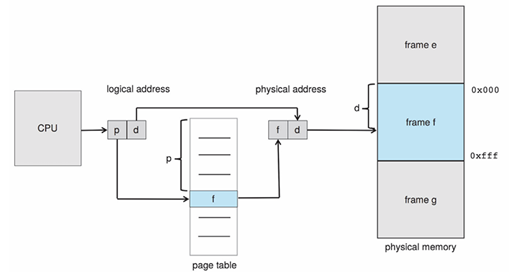
每個邏輯位址分為兩部分:
Logical Address = [ p | d ]
p = Page number(頁號)
d = Page offset(頁內偏移)
轉換公式為:Physical Address = (Frame number × Frame size) + d
假設:
page size = 4 bytes,Logical address = 13
Page number = 13 / 4 = 3, offset = 1
查 page table 得 page 3 → frame 2
所以 physical address = (2 × 4) + 1 = 9
當分頁(Paging)透過頁表(Page Table)將邏輯位址轉換成實體位址。這個過程會產生一個嚴重的效能問題:每次資料存取都需要兩次記憶體存取。
第一次存取:從主記憶體讀取頁表,以找到對應的頁框號碼(Frame number)。
第二次存取:利用這個頁框號碼,從主記憶體存取實際的資料。
這使得分頁系統的執行速度變成傳統記憶體存取的一半,顯然是無法接受的。為了解決這個問題,硬體設計者引入了一種名為 TLB(Translation Lookaside Buffer) 的硬體裝置。
TLB 是一種小型、高速的專用快取記憶體,專門用來存放最近被存取過的頁表項目。你可以把它想像成一個小型的、專門的頁表副本,它直接內建在記憶體管理單元(MMU)中,通常位於 CPU 晶片上,因此速度比主記憶體快上許多。
TLB 的運作原理非常簡單,就像任何快取一樣:它利用了參考的局部性原理(Principle of Locality of Reference),即程式在執行時,會重複存取相近的位址。因此,最近被存取過的頁表項目很可能在不久的將來會再次被存取。
TLB 的效能取決於它的命中率(Hit Rate)。命中率越高,表示邏輯位址轉換的過程越常在高速的 TLB 中完成,而不必去存取速度慢的主記憶體。
舉例而言,如果 TLB 的命中率是 90%,假設主記憶體存取時間為 100ns,TLB 存取時間為 20 ns。
在沒有TLB情況下,每次存取都需要兩次主記憶體存取,總時間為 2 * 100 ns = 200 ns。
而有TLB情況下:
在分頁系統中,每個程式都擁有自己獨立的邏輯位址空間,並透過頁表(Page Table)映射到實體記憶體。然而,如果沒有適當的保護機制,一個程式可能會意外或惡意地存取不屬於它的記憶體區域,例如:
為了解決這些問題,分頁系統在硬體層級提供了保護機制。這些保護機制的核心是在頁表中為每個頁面附加額外的控制位元(control bits),讓記憶體管理單元(MMU)在進行位址轉換時,同時檢查這些位元,以確保存取的合法性。
除了記錄邏輯頁(Page)與實體框(Frame)的對應關係外,頁表中的每一個項目(entry)還包含了以下重要的保護位元:
保護位元(Protection Bits):這些位元用來設定每個頁面的存取權限。最常見的三種權限是:
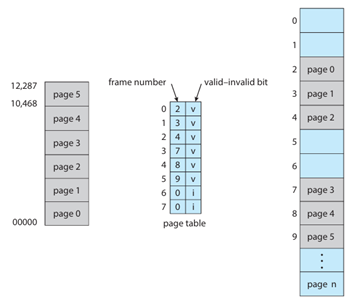
有效/無效位元(Valid/Invalid Bit):這個位元是分頁保護機制中最基礎的防護。它用來標記頁表中的一個項目是否有效,即該邏輯頁是否屬於目前程式的合法邏輯位址範圍。
在多工作業系統中,多個程式(Process)經常需要使用相同的資源,最常見的就是標準函式庫(Standard Libraries)、系統呼叫介面或共用的執行檔。如果每個程式都單獨複製一份這些共用的程式碼到自己的記憶體空間中,會造成極大的記憶體浪費。
舉例來說,當你同時開啟多個瀏覽器分頁時,每個分頁背後的瀏覽器程式(例如 Chrome)都使用相同的核心程式碼。如果這些核心程式碼被每個分頁單獨載入一次,會佔用大量的實體記憶體。為了解決這個問題,分頁(Paging)系統提供了一個強大的機制:共用頁面(Shared Pages)。
共用頁面的核心思想是,讓多個程式可以共用一份存在實體記憶體中的程式碼副本。這個機制之所以可行,是因為分頁將邏輯位址與實體位址分開,並透過頁表(Page Table)進行映射。
共用頁面機制要能安全運作,前提是所共用的程式碼必須是可重入的(Reentrant),也稱為純程式碼(Pure Code)。可重入程式碼指的是一種特殊的程式碼,它在執行過程中不會修改自身的內容。這意味著:
因此,即使有多個程式同時執行同一份可重入程式碼,它們各自的變數、堆疊(Stack)和資料都是獨立的,互不干擾。這就確保了共用程式碼的安全性:一個程式的執行不會意外地修改或破壞其他程式所使用的程式碼。
在分頁系統中,每個 process 都有一份 page table,用來記錄邏輯頁號(Page Number)與實體框號(Frame Number)的對應。
若有數百個 process 同時執行 → page table 空間消耗極大。解決方案:改良頁表結構,降低記憶體浪費。
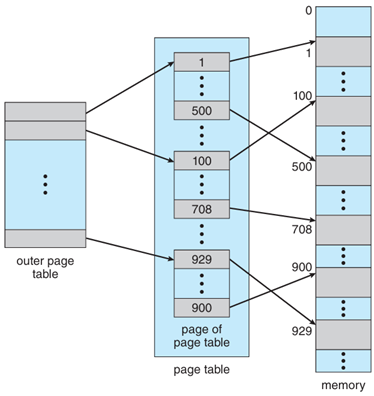
不再使用單一線性(flat)頁表。改成多層頁表(multi-level page table)。
分頁 page table 本身,只建立需要的部分,節省空間。
範例:二階層分頁範例(Two-Level Paging)
|p1 (10 bits)|p2 (10 bits)|d (12 bits)|
運作流程:
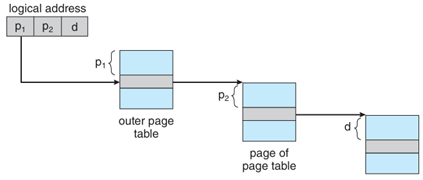
運作流程:
傳統缺點:每個 process 都有一份 page table,當系統 process 很多時,浪費大量記憶體。
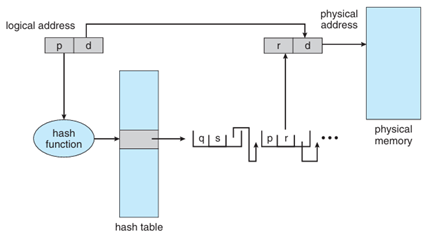
核心概念:
<Process ID, Page Number>
運作流程:
<PID, PageNumber> 是否存在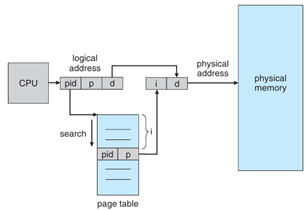
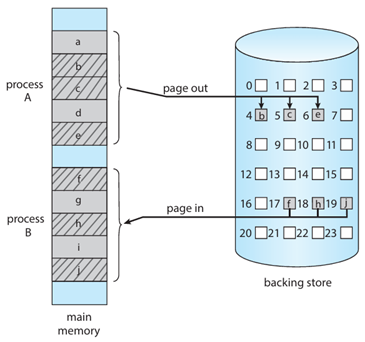
Swapping(交換)是指將整個程序或程序的一部分從主記憶體移到備份儲存裝置(如硬碟)以釋放記憶體空間,等到需要時再搬回主記憶體。這項技術的目的是:允許實體記憶體不足的情況下,同時容納更多程序,提升多工程度(degree of multiprogramming)。
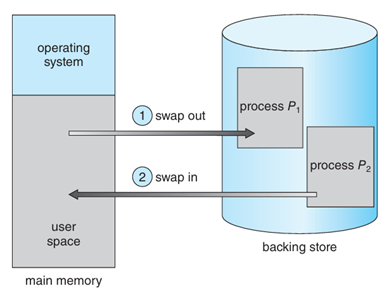
儲存內容包括:
優點是有效利用有限的主記憶體資源,非常適合用於「長時間閒置的程序」。缺點是整體速度慢,因為搬移整個程序耗時。在記憶體壓力不大的現代系統中已不常見。
標準交換是要般整個 process。分頁交換的話是只搬「需要的頁面」(Page-level Swapping)。優勢


 iThome鐵人賽
iThome鐵人賽