大語言模型LLM通常在一般的問題中都可以做準確地回答,但到專業領域就會出現虛幻的答案,所以就發展出RAG、Fine-tuning,都是來解決這個問題的。看一下他們的原理:
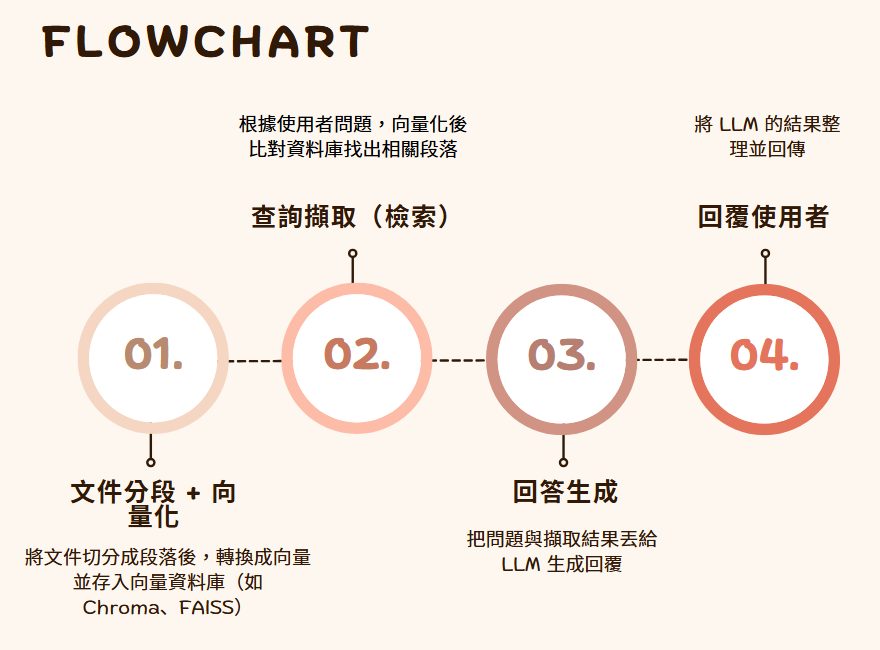
模型並不需要在訓練時記住這些知識,而是像一位隨身攜帶資料庫的助理,即時檢索、即時整合。這種方式最大的好處是靈活,只要資料庫更新,模型便能即時學到新知,不必重新訓練。
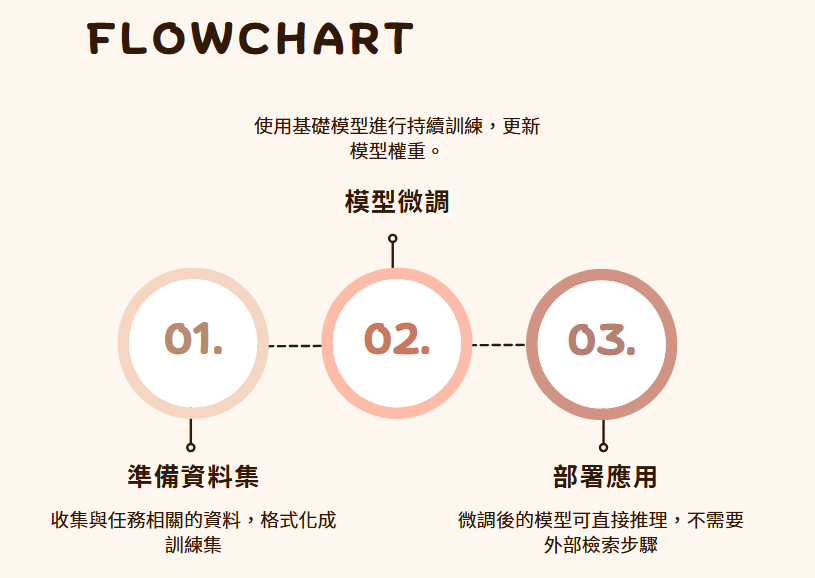
這樣的模型在部署後能直接回答問題,省去了檢索步驟,速度更快,也更容易保持一致的表達風格。但缺點在於更新成本高—每當知識變動,就需要重新蒐集資料並再次微調,才能讓模型跟上最新資訊。
| RAG(Retrieval-Augmented Generation) | 微調(Fine-tuning) | |
|---|---|---|
| 資料位置 | 知識存在外部資料庫(向量庫、SQL、文件系統) | 知識存在模型內部參數 |
| 更新方式 | 只要更新資料庫,不必重新訓練模型 | 要重新訓練或增量微調模型 |
| 即時性 | 可以即時加入最新資料 | 資料更新慢,必須等重新微調完成 |
| 成本 | 成本低(建立與查詢資料庫) | 成本高(需要大量計算資源和時間) |
| 靈活性 | 高,可隨時替換知識庫內容 | 低,一旦微調完成,知識固定 |
| 模型需求 | 用通用 LLM 搭配檢索系統就好 | 需要能微調的 LLM(且通常需訓練資源) |
| 適用場景 | 文件問答、內部知識庫 | 風格定制、專用領域語言模式 |
| 缺點 | 檢索質量不佳 | 更新不即時 |
用 RAG → 資料量大、常變動、希望即時更新(例如公司知識庫、新聞、技術文件)
用微調 → 資料穩定、希望模型本身能學會特定格式或行為(例如客服對話風格、專用領域名詞)
補充:
這是RAG流程
這是微調流程