

在全文搜尋或是模糊搜尋的時候,常常會聯想到使用 ElasticSearch 加快速度,但其實 PostgreSQL 本身也有提供模糊搜尋的功能。今天這篇文章,就來看看 PostgreSQL 提供的 pg_trgm extension吧!
當我們遇到使用者輸入不夠精確的情況,例如搜尋「tabel」其實是想找「table」,或是搜尋「guthib」其實是要找「github」。這類模糊搜尋(fuzzy search)就很適合用pg_trgm 做「近似比對」。
pg_trgm 全名為 trigram matching,它的核心概念是將字串拆解成三個字母一組的片段(trigrams),並透過這些片段來計算相似度或加速模糊比對的查詢。
Trigram(或稱三元組)是指將字串拆成三個一組的片段,其中非字元的部分會自動被忽略。例如:
"foo|bar" 拆成 → "f", "fo", "foo", "oo", "b", "ba", "bar", "ar"
pg_trgmignores non-word characters (non-alphanumerics) when extracting trigrams from a string.
pg_trgmCREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE TABLE test_trgm (
id serial PRIMARY KEY,
t text
);
INSERT INTO test_trgm (t)
VALUES
('apple'),
('appl'),
('appel'),
('appple'),
('aaple'),
('aple'),
('pineapple'),
('application'),
('apply'),
('ample'),
('maple'),
('banana'),
('grape'),
('orange');
這個運算子會比較兩個字串的 trigram 相似度,並回傳布林值。只有當相似度高於目前設定的 pg_trgm.word_similarity_threshold 門檻時,才會回傳 true。
SELECT t, word_similarity('apple', t) AS sim
FROM test_trgm
WHERE 'apple' <% t
ORDER BY sim DESC;
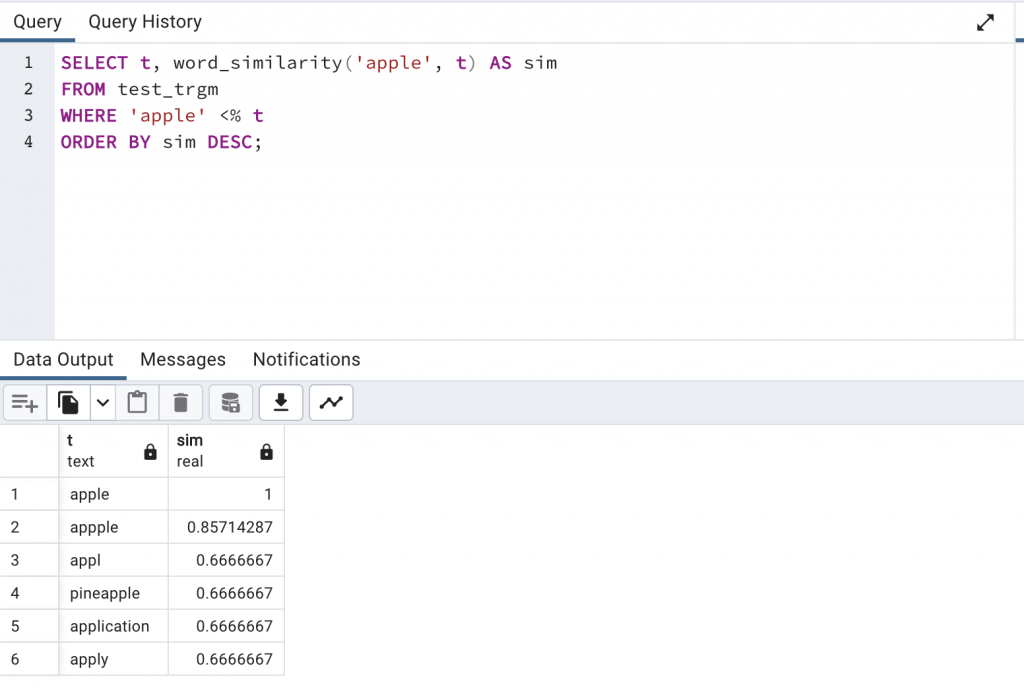
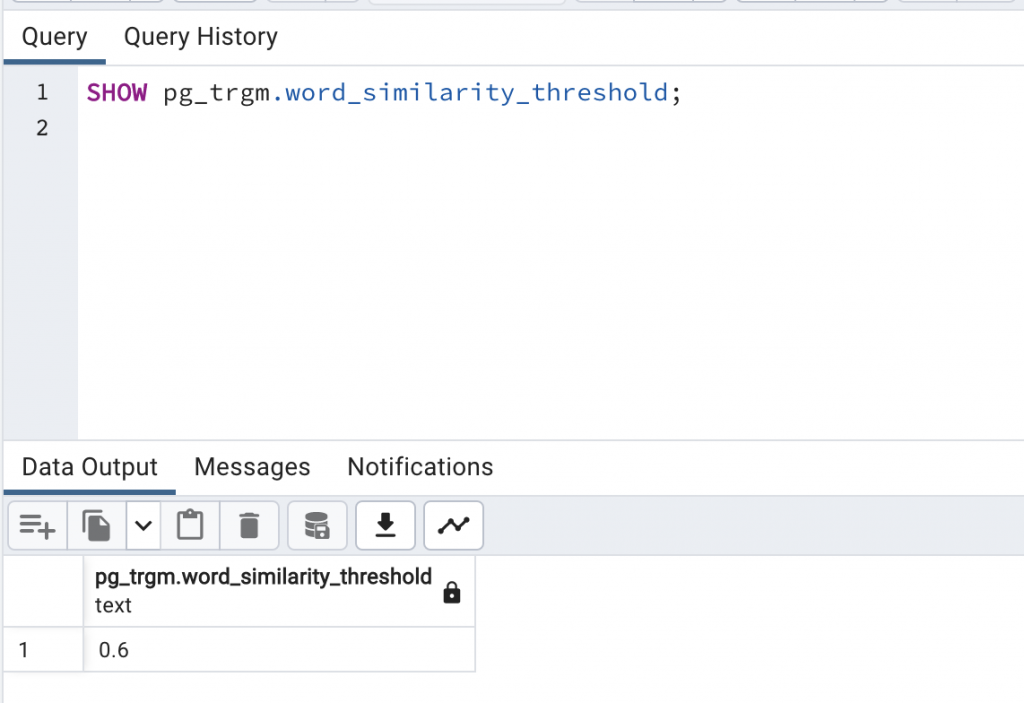
你可能會發現為什麼到了 0.6 之後就沒有資料了?那就是因為預設的門檻是 0.6,這個數字可以自己更改,也可以用 SHOW pg_trgm.word_similarity_threshold 來查詢到。
pg_trgm.word_similarity_threshold - Sets the current word similarity threshold that is used by the
<%and%>operators. The threshold must be between 0 and 1 (default is 0.6).
這個運算子會回傳一個距離值(distance),也就是 1 - similarity(text1, text2) ,距離越小,代表兩個字串越相似。
SELECT t, 'apple' <-> t AS dist
FROM test_trgm
ORDER BY dist
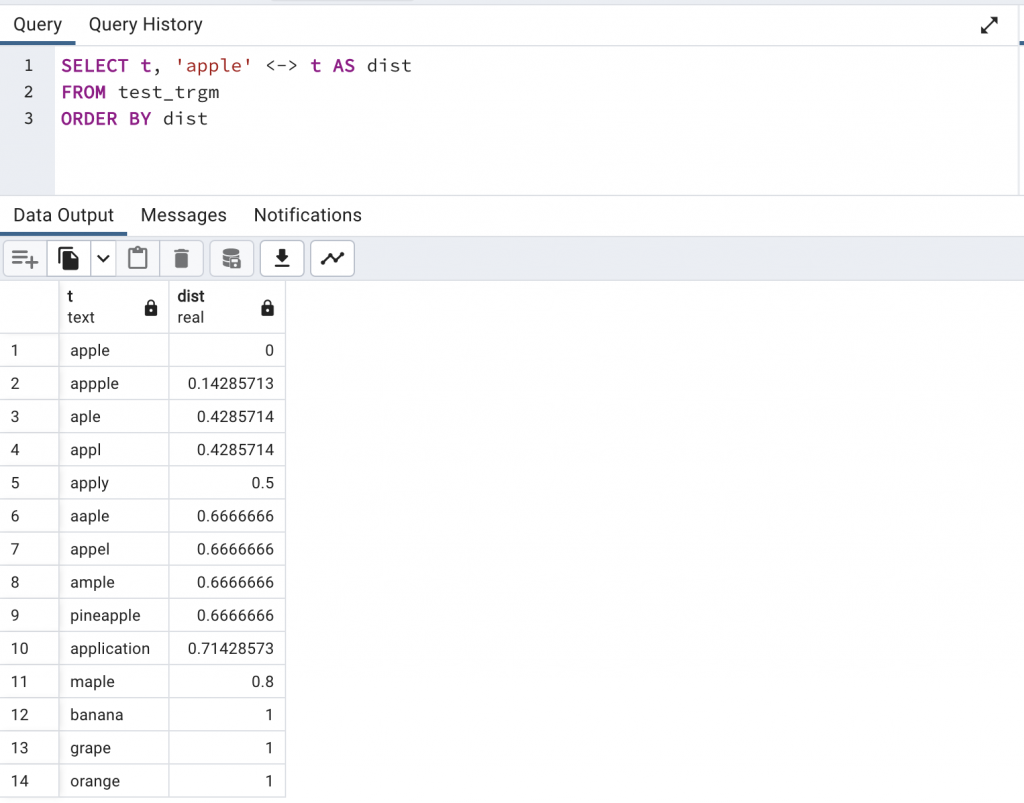
相似度查詢是篩選哪些字串夠相似,相似度高於門檻才會是 true;相似度距離排序是哪個字串最像,傳回距離(愈小愈相似)沒有過濾作用。
兩者都可以用個嚴格的條件篩選,像是 <<% 以及 <<-> ,可以查看 PostgreSQL 官方的表格。
昨天我們有提到,pg_trgm 是可以跟 GiST 和 GIN 的 Index 一起使用的,兩者一起用的時候,能夠加快基於 trigram 的模糊搜尋。
-- GiST
CREATE INDEX trgm_idx ON test_trgm USING GIST (t gist_trgm_ops);
-- GIN
CREATE INDEX trgm_idx ON test_trgm USING GIN (t gin_trgm_ops);
test_trgm ,總共十萬筆。import psycopg2
from faker import Faker
import json
import random
fake = Faker()
conn = psycopg2.connect(dbname="", user="", password="")
cur = conn.cursor()
insert_query = "INSERT INTO test_trgm (t) VALUES (%s)"
data = [(fake.paragraph(nb_sentences=5),) for _ in range(1, 100001)]
cur.executemany(insert_query, data)
conn.commit()
cur.close()
conn.close()
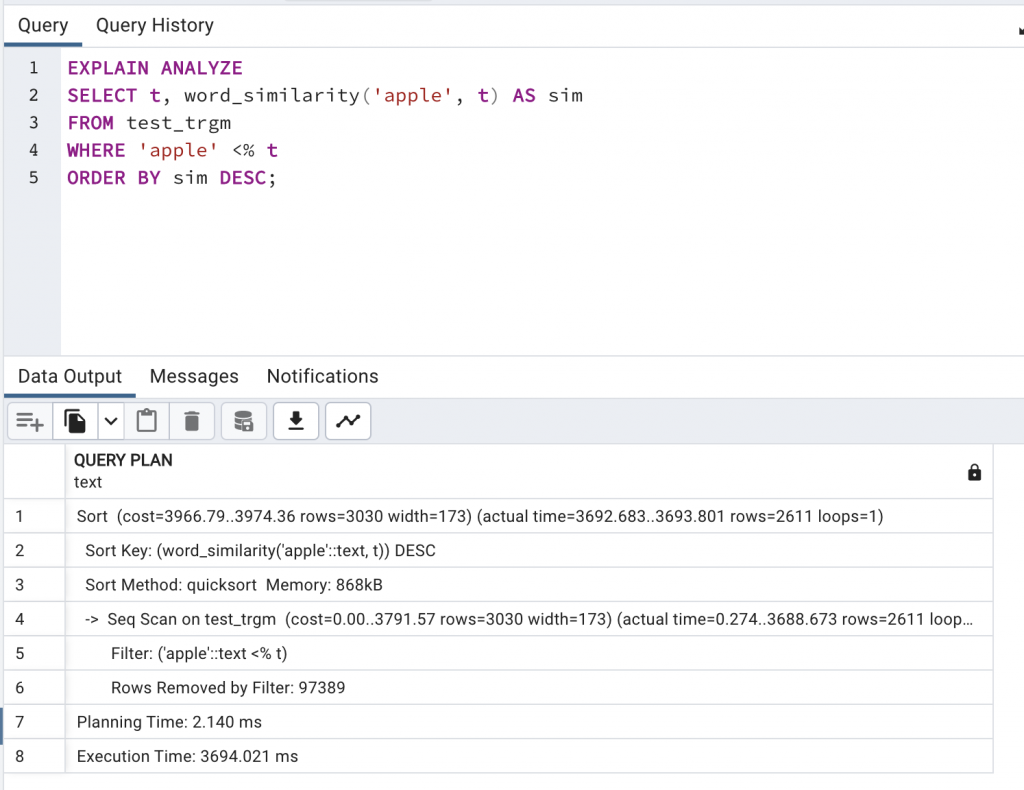
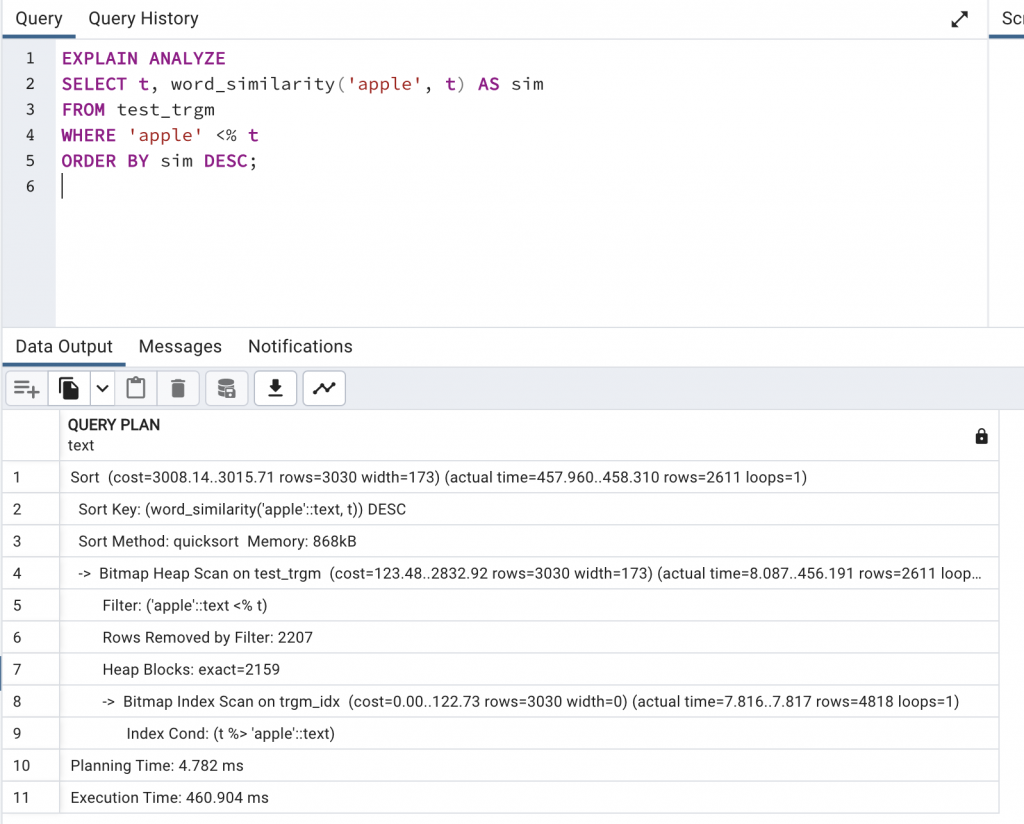
EXPLAIN ANALYZE
SELECT t, word_similarity('apple', t) AS sim
FROM test_trgm
WHERE 'apple' <% t
ORDER BY sim DESC;
CREATE INDEX trgm_idx ON test_trgm USING GIN (t gin_trgm_ops);
EXPLAIN ANALYZE
SELECT t, word_similarity('apple', t) AS sim
FROM test_trgm
WHERE 'apple' <% t
ORDER BY sim DESC;
pg_trgm 是 PostgreSQL 的套件,他會將字串拆解之後,再來評估字串之間的相似度。pg_trgm 適合系統需要接受使用者查詢有錯字、模糊查詢 。pg_trgm 支援相似度查詢運算子 <%,可用於快速篩選與比較字串的相似程度;也支援距離運算子 <->,用來排序相似度。pg_trgm 可以搭配 GIN / GiST Index,能大幅提升模糊搜尋的效能。https://www.postgresql.org/docs/current/pgtrgm.html

 iThome鐵人賽
iThome鐵人賽