

剩下最後來看看 BRIN Index 了。根據官方文件的敘述,BRIN 的全名為 Block Range Index,字面上來說是「區塊範圍」的 Index 。它適合處理非常大的資料表,特別是當欄位與資料的實體位置存在自然關聯性時。
聽起來有點抽象,但可以把重點放在「區塊範圍」與「自然關聯性」。我們知道 PostgreSQL 中儲存資料的單位是頁(Page),可以把每一頁當成是區塊範圍。
假設我有一張 table 是用來記 log,這張 table 有非常多的資料,其中一個欄位為 timestamp,照理來說 timestamp 的資料是有序的,新的資料 append 到這張 table,timestamp 也會越來越大。
這時候剛好可以利用這個特性來做一張小抄,因為 timestamp 是有順序性的,我可以記錄成:第 1-5 頁是 2000-2005 年的 log、第 6-10 頁是 2006-2010 年的資料。這樣假如我想找 2008 年的 log,我就可以直接去看第 6-10 頁,速度是不是就會變很快?這就是「時間欄位」與「資料實體位置」(Page)的自然關聯。
BRIN is designed for handling very large tables in which certain columns have some natural correlation with their physical location within the table.
| Page | Value |
|---|---|
| 1 - 5 | 2000 - 2005 |
| 6 - 10 | 2006 - 2010 |
| 11 - 15 | 2011 - 2015 |
| 16 - 20 | 2016 - 2020 |
另外文件中還有提到一點是,BRIN Index 的體積很小,雖然說查詢時需要多做一步查小抄的步驟,但是它可以省去尋找其他幾十幾百頁的時間,這也是為什麼它適合處理資料量大的 table。
Because a BRIN index is very small, scanning the index adds little overhead compared to a sequential scan, but may avoid scanning large parts of the table that are known not to contain matching tuples.
BRIN 實際上存哪些特定的資料,取決於 Index 的 operator class(文件內有表格可以看所有類別)。假如具有線性排序順序的資料型態,像剛剛時間的舉例,BRIN 就會在每個區塊範圍內存最小值和最大值。
logs table,其中包含 created_at 欄位就很適合使用 BRIN Index 來做搜尋CREATE TABLE logs (
id SERIAL PRIMARY KEY,
event_type TEXT,
created_at TIMESTAMPTZ DEFAULT now()
);
INSERT INTO logs (event_type, created_at)
SELECT
CASE (s % 3)
WHEN 0 THEN 'LOGIN'
WHEN 1 THEN 'LOGOUT'
WHEN 2 THEN 'ERROR'
END AS event_type,
'2023-01-01 00:00:00 UTC'::timestamptz + (s * INTERVAL '1 second') AS created_at
FROM
GENERATE_SERIES(1, 100000) AS s;
EXPLAIN ANALYZE
SELECT * FROM logs
WHERE created_at BETWEEN '2025-01-01' AND '2025-01-10';
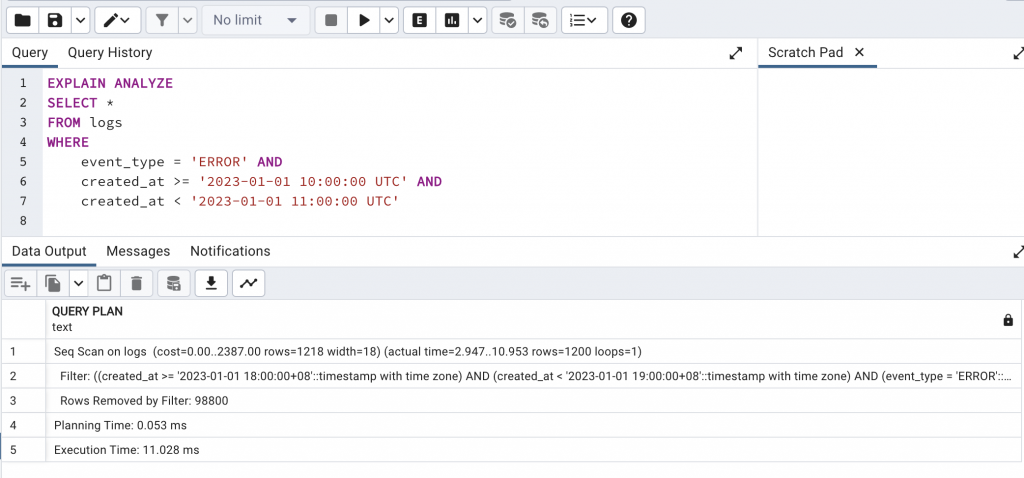
created_at 欄位建立 BRIN IndexCREATE INDEX idx_logs_created_at
ON logs USING BRIN(created_at);
EXPLAIN ANALYZE
SELECT * FROM logs
WHERE created_at BETWEEN '2025-01-01' AND '2025-01-10';
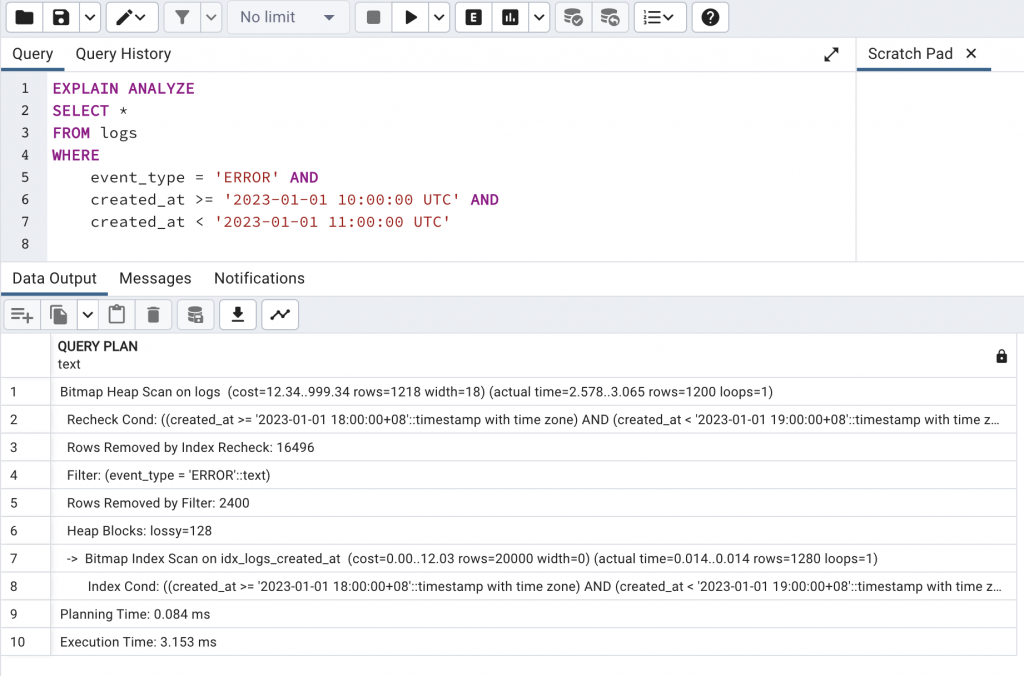
可以發現搜尋速度從 11ms 縮短為 3ms。
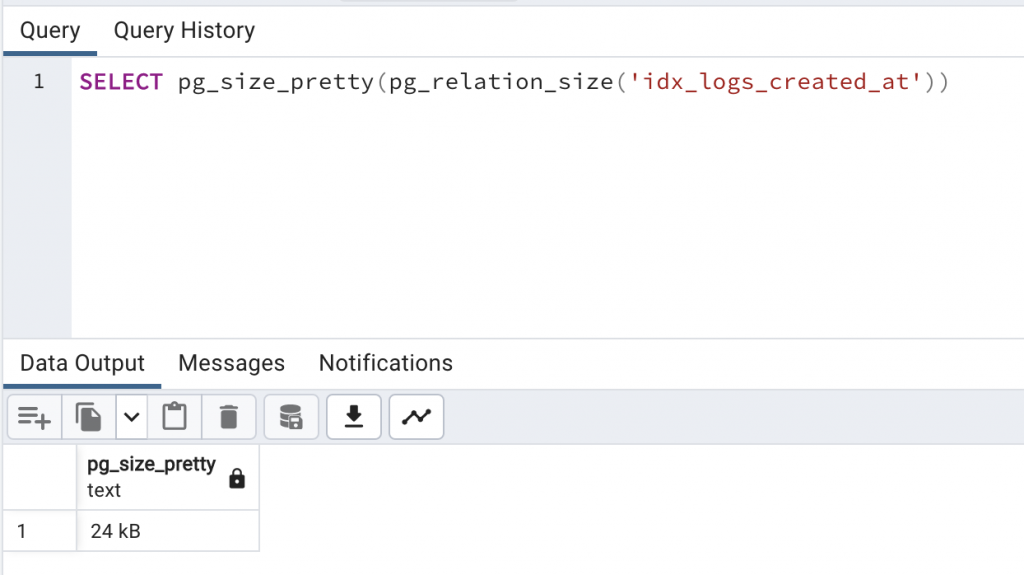
如果我們觀察一下 BRIN Index 的大小的話,會發現十萬筆的資料只佔了 24KB。
SELECT pg_size_pretty(pg_relation_size('idx_logs_created_at'))
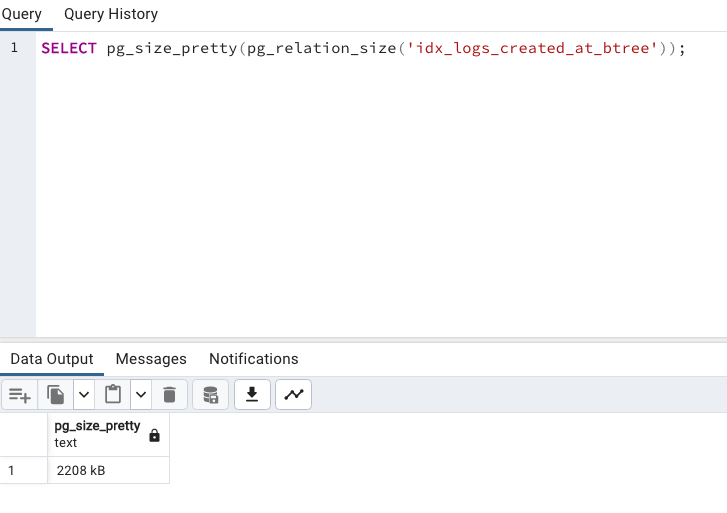
把一樣的欄位設為 B-tree Index,會發現大小是 2208 KB,由此可見 BRIN Index 的體積真的很小。
CREATE INDEX idx_logs_created_at_btree ON logs (created_at);
SELECT pg_size_pretty(pg_relation_size('idx_logs_created_at_btree'))
https://www.postgresql.org/docs/current/brin.html

 iThome鐵人賽
iThome鐵人賽