

在高併發(High Concurrency)的場景下,我們除了關心速度之外,更重要的是「資料會不會錯」。想像你正在操作一筆銀行轉帳交易,當你從帳戶扣款的同時,有另一個交易在查詢餘額,結果查到了錯誤的金額;或者你剛查完商品數量,下一行要下訂單時,庫存卻已經變了,這些問題,都是交易隔離層級(Isolation Levels)要處理的範圍。
在介紹解法之前,我們先來看看不同隔離層級時,會遇到哪些問題:
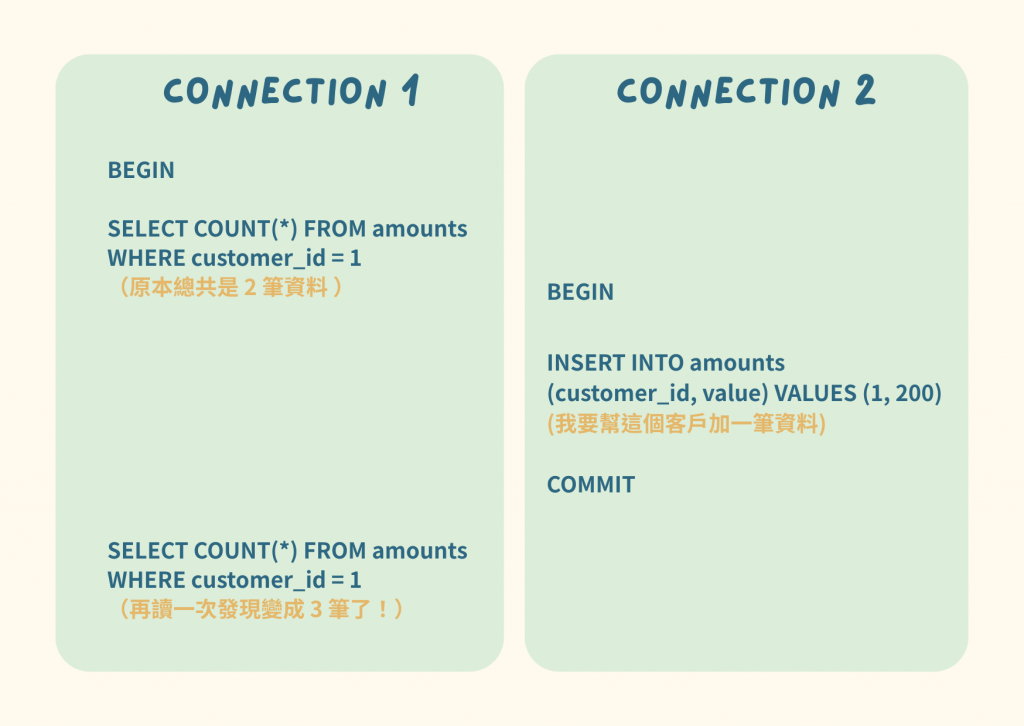
Dirty read 是指在 transaction 內,讀到了另一個 transaction 還沒被 commit 的資料。因為另一個 transaction 可能之後會被 rollback,就會造成誤判。
Non-repeatable Reads 是指同一筆資料,在同一個 transaction 中讀兩次,卻得到不同的結果。跟 Dirty read 的差別是這時候 connection 2 是有 commit 的狀態。

Phantom Reads 是指在同一個 transction 中,查詢一整筆資料後,因為其他 transaction 塞入了新資料,導致再次查詢時出現資料筆數不一致的情況。
Serialization Anomaly 是指多筆 transaction 結果無法用單一順序解釋的邏輯矛盾。這句話聽起很抽象,可以直接用例子來看會比較容易懂。
假設初始資料如下:
| Category | Amount |
|---|---|
| 1 | 10 |
| 1 | 20 |
| 2 | 100 |
| 2 | 200 |
Connection 1: Category 1 的總和為 30,我想以這個總和幫 Category 2 加一筆新的資料
Connection 2: Category 2 的總和為 300,我想以這個總和幫 Category 1 加一筆新的資料
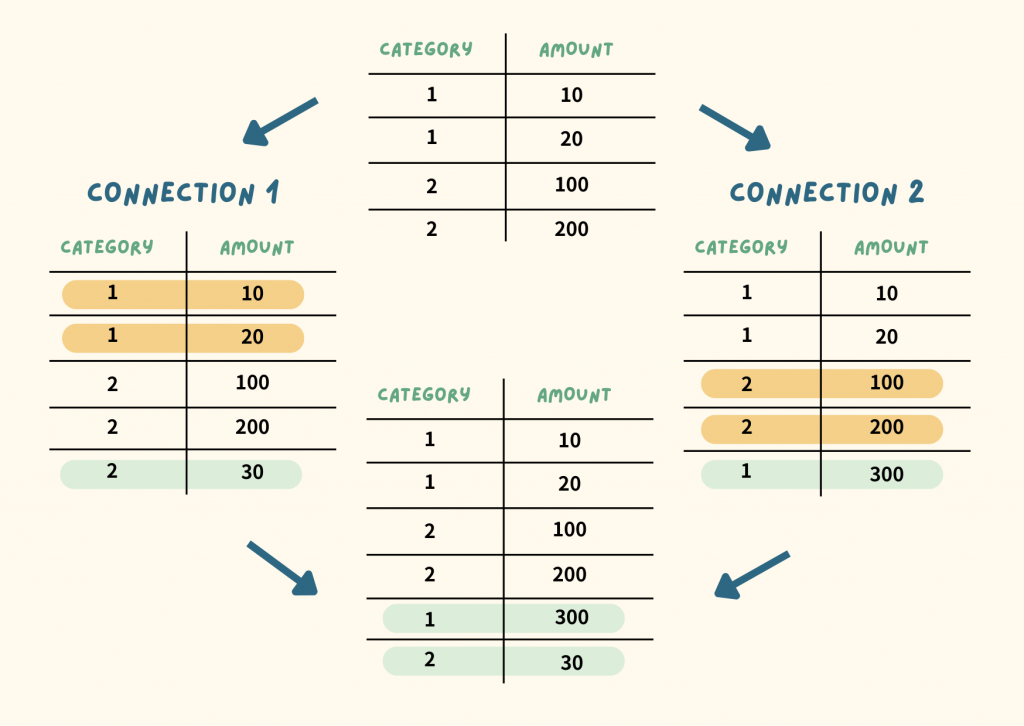
假設兩者同時發生,Category 1 會新增 300,Category 2 會新增 30。但是如果是有順序性的話:
A. Connection 1 先執行,接著換成 Connection 2
Connection 1: Category 1 的總和為 30,我想以這個總和幫 Category 2 加一筆新的資料
Connection 2: Category 2 的總和為 330,我想以這個總和幫 Category 1 加一筆新的資料
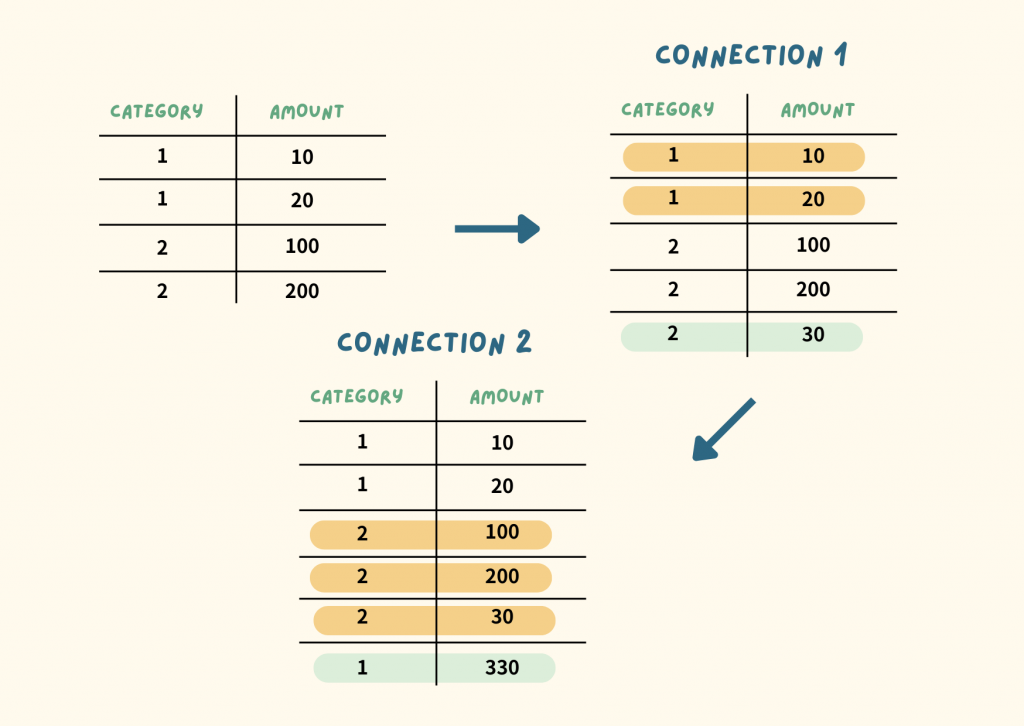
Category 2 會先新增 30,Category 1 會基於前一步而變成新增 330。
B. Connection 2 先執行,接著換成 Connection 1
Connection 2: Category 2 的總和為 300,我想以這個總和幫 Category 1 加一筆新的資料
Connection 1: Category 1 的總和為 330,我想以這個總和幫 Category 2 加一筆新的資料
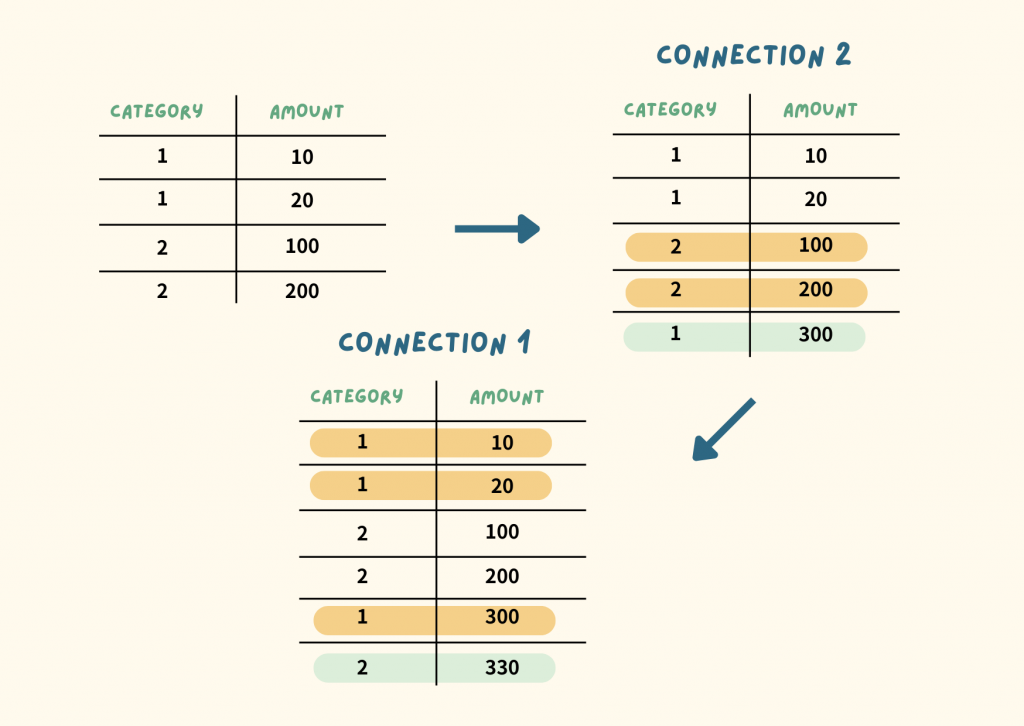
Category 1 會先新增 300,Category 2 會基於前一步而變成新增 330。
結果就會發現,不論是情境 A 還是情境 B,好像都沒辦法還原一開始的情境。當兩個 request 同時發生時,實際上兩者都會查到了原本的 30 和 300,這種情況就是 Serialization Anomaly。
我們了解了在同時併發可能會造成的錯誤以後,就可以來認識 Isolation Levels 了。在 PostgreSQL 當中,設定不同的 Isolation Level,可以避免掉不同的異常狀況。可以參考官方的表格:
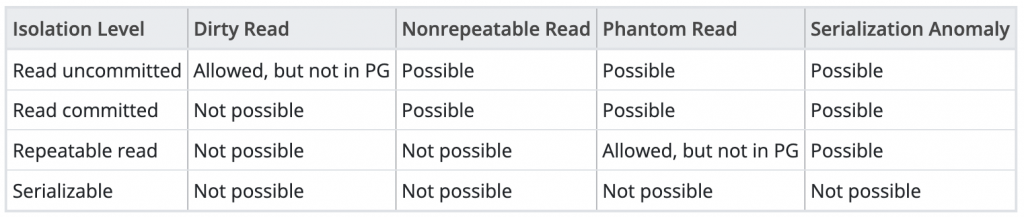
https://www.postgresql.org/docs/current/transaction-iso.html
在 Read uncommitted 中,四種狀況都有可能會發生,不過 PG 的設計是 Read uncommitted 和 Read committed 的行為一樣,所以可以看到左上角是寫 Allowed, but no in PG。
Read committed 可以解決的是 Dirty read,不過其他三種狀況還可能會發生。而 Read committed 也是 PostgreSQL 預設的隔離層級。
Repeatable read 可以解決 Dirty read & Non repeatable read,剩下兩種錯誤狀況會發生。PostgreSQL 的設計是不會發生 Phantom read。
最後一個層級 Serializable 就可以避免四種錯誤情況發生,看到這裡可能會有個疑問,那為何不把隔離層級都設為 Serializable?這樣資料一定都沒問題啦~
那我們就來看一下 Serializable 他是怎麼做到這件事的,來看看官方文件怎麼說:
The Serializable isolation level provides the strictest transaction isolation. This level emulates serial transaction execution for all committed transactions; as if transactions had been executed one after another, serially, rather than concurrently.
在 Serializable 的層級下,它模擬所有交易是「是依序、一筆一筆執行」的效果。它的運作方式其實和 Repeatable Read 很像,但多了「監控機制」,用來偵測可能導致非序列化結果的狀況(也就是 Serialization Anomaly)。
所以當系統發現這種衝突時,會回報錯誤並 rollback 其中一個交易。
也就是因為他會模擬交易是依序的,需要額外多了監控機制,在高併發、大流量場景的時候,應該可以想像因為 transaction 彼此依賴、互相影響的機會多了,衝突就多,也更容易 rollback。所以事實上 Serializable 確保交易時序以及資料穩定性,但會犧牲花費時間。
明天我們就來實驗看看,在不同隔離層級之下,觀察是否真的會出現這些錯誤現象,那就明天見了~
https://www.postgresql.org/docs/current/transaction-iso.html

 iThome鐵人賽
iThome鐵人賽