

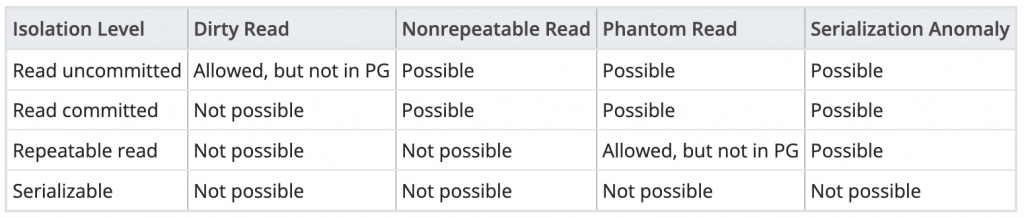
經過前一天的文章,我們發現併發的 request 可能造成的現象,以及調整資料庫的 Isolation Level 可能影響資料庫的一致性。接下來我們就來實驗看看調整 Isolation Level,觀察是否真的會出現這些錯誤現象。
以 Dirty Read 來說,在 Read uncommitted 的模式會出現,不過 PostgreSQL 的 Read uncommitted 表現方式和 Read committed 一樣,所以不會發生 Dirty Read。
PostgreSQL's Read Uncommitted mode behaves like Read Committed. This is because it is the only sensible way to map the standard isolation levels to PostgreSQL's multiversion concurrency control architecture.
所以我們就直接來看 Read committed 的模式,根據昨天的結論,他會出現 Non repeatable read。
import psycopg2
from psycopg2 import sql, extensions
import time
# 建立兩個獨立的連線
conn1 = psycopg2.connect(dbname="", user="", password="")
conn2 = psycopg2.connect(dbname="", user="", password="")
# 設定兩個連線的隔離層級為 READ COMMITTED
conn1.set_isolation_level(extensions.ISOLATION_LEVEL_READ_COMMITTED)
conn2.set_isolation_level(extensions.ISOLATION_LEVEL_READ_COMMITTED)
print("Isolation level for conn1:", conn1.isolation_level)
print("Isolation level for conn2:", conn2.isolation_level)
cur1 = conn1.cursor()
cur2 = conn2.cursor()
cur1.execute(
"""
CREATE TABLE IF NOT EXISTS amounts (
id SERIAL PRIMARY KEY,
value INTEGER
)
"""
)
cur1.execute("INSERT INTO amounts (value) VALUES (100)")
conn1.commit()

try:
# 在 Connection 1 啟動第一個 transaction
cur1.execute("BEGIN")
cur1.execute("SELECT value FROM amounts WHERE id = 1")
initial_value = cur1.fetchone()[0]
print(f"Initial read value in conn1: {initial_value}")
# 在 Connection 2 啟動第二個 transction 並更新 value
cur2.execute("BEGIN")
cur2.execute("UPDATE amounts SET value = 200 WHERE id = 1")
conn2.commit()
time.sleep(5)
# 在 Connection 1 中再次讀取 value
cur1.execute("SELECT value FROM amounts WHERE id = 1")
new_value = cur1.fetchone()[0]
print(f"New read value in conn1: {new_value}")
conn1.commit()
finally:
# Clean up
cur1.execute("DROP TABLE IF EXISTS amounts")
conn1.commit()
cur1.close()
cur2.close()
conn1.close()
conn2.close()
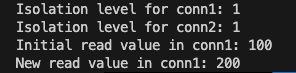
可以看到 Connection 1 在一開始取得的 value 是 100,但在 Connection 2 更改值並改成 200 之後,Connection 1 在同一個 transaction 的情況下再取得 value 時,就變成 200了。
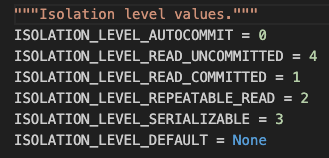
這裡 print 出來的數字是 psycopg2 extension 內 Isolation Level 的對應數字:
根據前一天的文章,如果模式改為 Repeatable read 的話,就能解決這個問題?我們再來實驗看看。
conn1.set_isolation_level(extensions.ISOLATION_LEVEL_REPEATABLE_READ)
conn2.set_isolation_level(extensions.ISOLATION_LEVEL_REPEATABLE_READ)
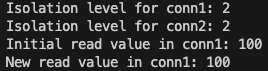
果然改成 Repeatable read 之後,Connection 1 在 transaction 中取得的值都會 100,沒有再被 connection 2 的 commit 影響了。
This level is different from Read Committed in that a query in a repeatable read transaction sees a snapshot as of the start of the first non-transaction-control statement in the transaction, not as of the start of the current statement within the transaction.
根據文件,在 Repeatable read 的模式下,在 transaction 的查詢會看到一個「快照」,這個快照是從 Transation 的第一個 SELECT 查詢開始時的狀態,而不是每次查詢時,都根據當前語句的狀態來決定。也因此在這個模式下,同一個 transaction 查詢到的值都會是一樣的囉。
而這個快照其實就跟 PostgreSQL 的 MVCC (Multi-Version Concurrency Control) 機制有關,即便在當下的 transaction 之外,有其他人已經修改了新版本也無法被看見,這樣可以確保 transaction 內讀取的一致性。
Internally, data consistency is maintained by using a multiversion model (Multiversion Concurrency Control, MVCC). This means that each SQL statement sees a snapshot of data (a database version) as it was some time ago, regardless of the current state of the underlying data.
Phantom Read 是當同一個 transaction 內多次執行相同查詢時,查詢的筆數發生變化。
通常 Serializable 隔離層級能防止 Phantom Read,不過在 PostgreSQL 中 Repeatable read 也有被設計成不會發生(Allow but no in PG)。
The table also shows that PostgreSQL's Repeatable Read implementation does not allow phantom reads. This is acceptable under the SQL standard because the standard specifies which anomalies must not occur at certain isolation levels; higher guarantees are acceptable.
由於 PostgreSQL 這樣的設計,我們就一樣在 Read committed & Repeatable read 兩種模式,觀察看看 Phantom Read 的變化。
import psycopg2
from psycopg2 import sql, extensions
import time
# 建立兩個獨立的連線
conn1 = psycopg2.connect(dbname="", user="", password="")
conn2 = psycopg2.connect(dbname="", user="", password="")
# 設定兩個連線的隔離層級為 READ COMMITTED
conn1.set_isolation_level(extensions.ISOLATION_LEVEL_READ_COMMITTED)
conn2.set_isolation_level(extensions.ISOLATION_LEVEL_READ_COMMITTED)
print("Isolation level for conn1:", conn1.isolation_level)
print("Isolation level for conn2:", conn2.isolation_level)
cur1 = conn1.cursor()
cur2 = conn2.cursor()
cur1.execute(
"""
CREATE TABLE IF NOT EXISTS amounts (
id SERIAL PRIMARY KEY,
customer_id INTEGER,
value DECIMAL(10, 2)
)
"""
)
cur1.execute("INSERT INTO amounts (customer_id, value) VALUES (1, 100.00), (1, 150.00)")
conn1.commit()
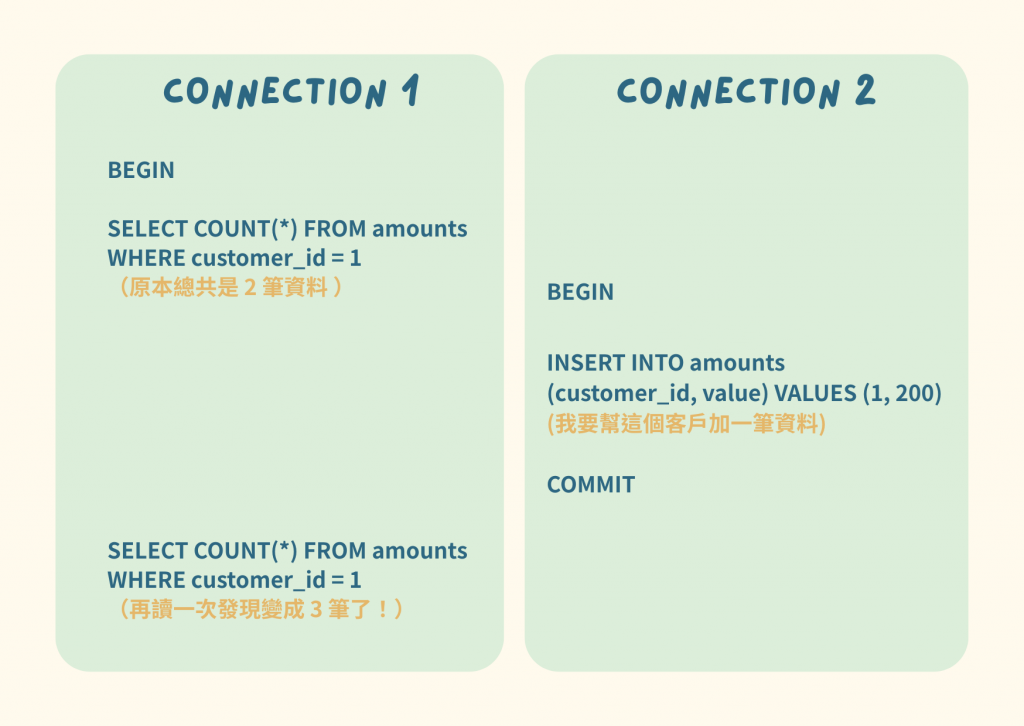
try:
# 在 Connection 1 啟動第一個 transaction
cur1.execute("BEGIN")
cur1.execute("SELECT COUNT(*) FROM amounts WHERE customer_id = 1")
initial_count = cur1.fetchone()[0]
print(f"Initial count of amounts for customer_id 1 in conn1: {initial_count}")
# 在 Connection 2 啟動第二個 transaction 並新增一筆資料
cur2.execute("BEGIN")
cur2.execute("INSERT INTO amounts (customer_id, value) VALUES (1, 200.00)")
conn2.commit()
time.sleep(5)
# 在 Connection 1 中再次讀取筆數
cur1.execute("SELECT COUNT(*) FROM amounts WHERE customer_id = 1")
new_count = cur1.fetchone()[0]
print(f"New count of amounts for customer_id 1 in conn1: {new_count}")
conn1.commit()
finally:
# Clean up
cur1.execute("DROP TABLE IF EXISTS amounts")
conn1.commit()
cur1.close()
cur2.close()
conn1.close()
conn2.close()

可以看到 Connection 1 一開始度的筆數為 2,在 Connection 2 新增一筆資料並且 commit 之後,Connection 1 在同一個 transaction 中再取得資料就變成 3 筆了,造成 Phantom read。
如果模式改為 Repeatable read / Serializable 的話,就能解決這個問題了~
conn1.set_isolation_level(extensions.ISOLATION_LEVEL_REPEATABLE_READ)
conn2.set_isolation_level(extensions.ISOLATION_LEVEL_REPEATABLE_READ)

Connection 1 都是讀到兩筆資料。
今天看了 Non repeatable read & Phantom read 在不同 Isolation Level 的表現行為,明天再繼續看看 Serialization Anomaly。
https://www.postgresql.org/docs/9.5/transaction-iso.html
https://www.postgresql.org/docs/current/mvcc-intro.html

 iThome鐵人賽
iThome鐵人賽