前情提要:昨天我們理解了 Deployment、ReplicaSet和Pod,它們三者的職責與關聯。以及 label 和 selector 的搭配使用。
掌握 KinD 多節點集群的建立與配置
深入理解 Pod Anti-Affinity 親和性機制
學會使用 kubeadmConfigPatches 自定義節點配置
實踐多節點環境下的 Pod 調度策略
✅ 成功建立 KinD 多節點集群(1 control-plane + 2 worker)
✅ 掌握 kubeadmConfigPatches 的配置與作用
✅ 理解 Pod Anti-Affinity 的調度機制
✅ 學會節點標籤的設定與查看方法
✅ 驗證親和性規則對 Pod 分布的影響
今天來玩多節點,補充講到之前 Day2 提到的 Affubuty(親和性)。看看我們能怎控制 deployment 去佈署 pod 在想要的節點上。
kind-config.yaml
# kind-config.yaml
# API 版本和資源類型
kind: Cluster # 資源類型:cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: multi-node-cluster # cluster 名稱
# 節點配置
nodes:
# 🏗️ Control Plane 節點(主節點)
- role: control-plane # 節點角色:控制平面
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "node-type=control-plane" # 自定義節點標籤
# 🔧 Worker 節點 1
- role: worker # 節點角色:工作節點
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "node-type=worker,node-name=node-a" # 自定義節點標籤
# 🔧 Worker 節點 2
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "node-type=worker,node-name=node-b"
這段裡面 kubeadm 的 ConfigPatches
kubeadmConfigPatches:
- |
kind: InitConfiguration # 或 JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "key=value"
作用:
建立多節點 KinD 集群
> kind create cluster --config kind-config.yaml
Creating cluster "multi-node-cluster" ...
✓ Ensuring node image (kindest/node:v1.33.1) 🖼
✓ Preparing nodes 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-multi-node-cluster"
You can now use your cluster with:
kubectl cluster-info --context kind-multi-node-cluster
Have a nice day! 👋
驗證節點
> kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
multi-node-cluster-control-plane Ready control-plane 104s v1.33.1 172.18.0.3 <none> Debian GNU/Linux 12 (bookworm) 6.8.0-60-generic containerd://2.1.1
multi-node-cluster-worker Ready <none> 94s v1.33.1 172.18.0.5 <none> Debian GNU/Linux 12 (bookworm) 6.8.0-60-generic containerd://2.1.1
multi-node-cluster-worker2 Ready <none> 94s v1.33.1 172.18.0.4 <none> Debian GNU/Linux 12 (bookworm) 6.8.0-60-generic containerd://2.1.1
為節點添加自定義標籤(方便識別)
kubectl label nodes multi-node-cluster-worker node-role=node-a
kubectl label nodes multi-node-cluster-worker2 node-role=node-b
查看節點標籤
> kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
multi-node-cluster-control-plane Ready control-plane 2m54s v1.33.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=multi-node-cluster-control-plane,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-type=control-plane,node.kubernetes.io/exclude-from-external-load-balancers=
multi-node-cluster-worker Ready <none> 2m44s v1.33.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=multi-node-cluster-worker,kubernetes.io/os=linux,node-name=node-a,node-role=node-a,node-type=worker
# 這裡就能看到剛剛新增的標籤 node-role=node-a
multi-node-cluster-worker2 Ready <none> 2m44s v1.33.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=multi-node-cluster-worker2,kubernetes.io/os=linux,node-name=node-b,node-role=node-b,node-type=worker
# 這裡就能看到剛剛新增的標籤 node-role=node-b
deployment-multi-node.yaml
# deployment-multi-node.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: multi-node-app
labels:
app: multi-node-app
spec:
replicas: 2
selector:
matchLabels:
app: multi-node-app
template:
metadata:
labels:
app: multi-node-app
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
resources:
requests:
memory: "64Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "100m"
# 🎯 使用 Pod Anti-Affinity 確保 pods 分散到不同節點
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- multi-node-app
topologyKey: kubernetes.io/hostname
service.yaml
apiVersion: v1
kind: Service
metadata:
name: multi-node-service
labels:
app: multi-node-app
spec:
selector:
app: multi-node-app
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
type: ClusterIP
nginx-configmap.yaml
# nginx-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-node-info
data:
default.conf: |
server {
listen 80;
listen [::]:80;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
location /node-info {
add_header Content-Type text/plain;
return 200 "Node: $hostname\nPod IP: $server_addr\nTimestamp: $time_iso8601\n";
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
佈署
# 1. 先部署 Deployment
kubectl apply -f deployment-multi-node.yaml
# 2. 部署 Service
kubectl apply -f service.yaml
驗證部署結果
# 檢查 Deployment 狀態
> kubectl get deployment multi-node-app
NAME READY UP-TO-DATE AVAILABLE AGE
multi-node-app 2/2 2 2 21s
# 檢查 Pods 分布在哪些節點上
> kubectl get pods -l app=multi-node-app -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
multi-node-app-7bfdc94778-bhshd 1/1 Running 0 100s 10.244.1.3 multi-node-cluster-worker <none> <none>
multi-node-app-7bfdc94778-wktzl 1/1 Running 0 100s 10.244.2.3 multi-node-cluster-worker2 <none> <none>
🎉 成功! 你可以看到兩個 Pods 分別部署在:multi-node-cluster-workermulti-node-cluster-worker2
或者改用這命令,能更清晰的看見實驗效果。
> kubectl get pods -l app=multi-node-app -o custom-columns="POD NAME:.metadata.name,NODE:.spec.nodeName,STATUS:.status.phase,IP:.status.podIP"
POD NAME NODE STATUS IP
multi-node-app-7bfdc94778-bhshd multi-node-cluster-worker Running 10.244.1.3
multi-node-app-7bfdc94778-wktzl multi-node-cluster-worker2 Running 10.244.2.3
Kubernetes 提供了三種主要的親和性機制:
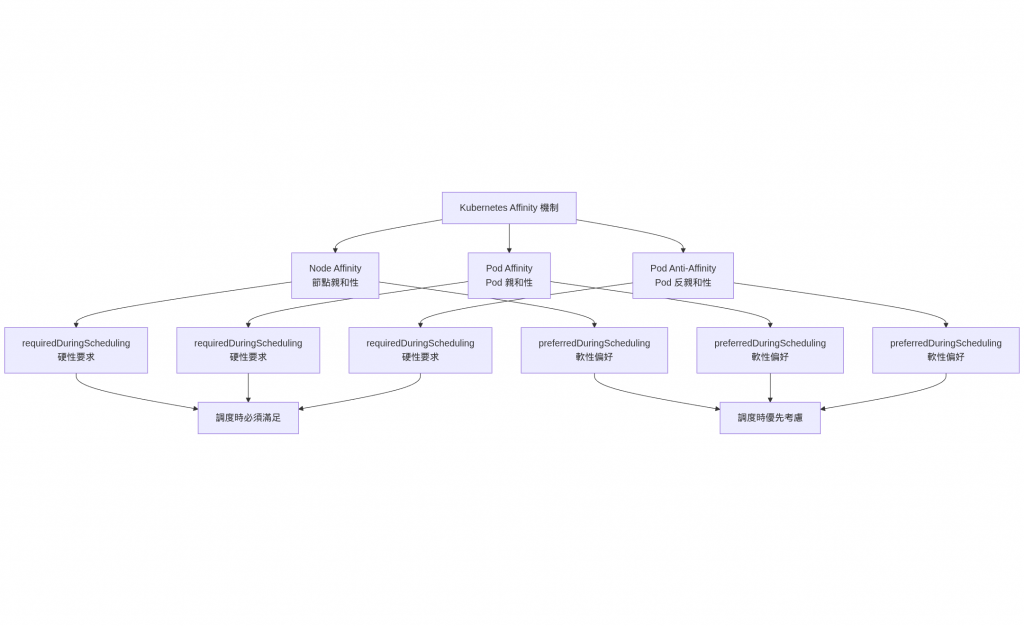
| 類型 | 用途 | 場景 |
|---|---|---|
| Node Affinity | 控制 Pod 調度到特定節點 | 需要特定硬體資源(SSD、GPU) |
| Pod Affinity | Pod 與特定 Pod 調度在一起 | 低延遲網路交互需求 |
| Pod Anti-Affinity | Pod 避開特定 Pod | 高可用性、負載分散 |
Node Affinity 讓你可以指定 Pod 應該調度到哪些節點上,基於節點的label進行選擇。
spec:
# 🎯 Node Affinity 配置
affinity:
nodeAffinity:
# 硬性要求:必須調度到有 SSD 的節點
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk-type
operator: In # 標籤值在以下 values 指定列表中
values:
- ssd
- nvme
# 軟性偏好:優先選擇高性能節點
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: performance
operator: In
values:
- high
- weight: 50
preference:
matchExpressions:
- key: zone
operator: In
values:
- zone-a
Pod Affinity 讓你可以指定 Pod 應該與其他特定的 Pod 調度在一起,通常用於需要低延遲通信的服務。
spec:
# 🎯 Pod Affinity 配置
affinity:
podAffinity:
# 硬性要求:必須與資料庫在同一節點
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- database
topologyKey: kubernetes.io/hostname
# 軟性偏好:優先與 backend tier 的 Pod 在同一區域
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- backend
topologyKey: topology.kubernetes.io/zone
為什麼 Pods 會分散到不同節點?
在 deployment-multi-node.yaml 中,這段配置起了關鍵作用:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- multi-node-app
topologyKey: kubernetes.io/hostname
欄位解釋:podAntiAffinity:Pod 反親和性requiredDuringSchedulingIgnoredDuringExecution:調度時必須滿足,執行時忽略topologyKey: kubernetes.io/hostname:以主機名為拓撲域
簡單來說: 這個設定告訴 Kubernetes:「同一個 app 的 Pods 不能部署在同一個節點上」
更多案例
spec:
affinity:
# 🎯 多層次的 Anti-Affinity 策略
podAntiAffinity:
# 硬性要求:同一應用的 Pod 不能在同一節點
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- high-availability-app
topologyKey: kubernetes.io/hostname
# 軟性偏好:盡量不要與相同版本的 Pod 在同一區域
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: version
operator: In
values:
- v1.0
topologyKey: topology.kubernetes.io/zone
# 軟性偏好:避免與高資源消耗的應用在同一節點
- weight: 50
podAffinityTerm:
labelSelector:
matchExpressions:
- key: resource-intensive
operator: In
values:
- "true"
topologyKey: kubernetes.io/hostname
驗證親和性效果
讓我們試著增加副本數量來測試:
# 將 replicaset 數量增加到 3
> kubectl scale deployment multi-node-app --replicas=3
# 檢查結果
> kubectl get pods -l app=multi-node-app -o custom-columns="POD NAME:.metadata.name,NODE:.spec.nodeName,STATUS:.status.phase"
POD NAME NODE STATUS
multi-node-app-7bfdc94778-bhshd multi-node-cluster-worker Running
multi-node-app-7bfdc94778-r7pcd <none> Pending
multi-node-app-7bfdc94778-wktzl multi-node-cluster-worker2 Running
你會發現第三個 Pod 會處於 Pending 狀態,因為只有 2 個 worker 節點,而反親和性規則不允許同一節點上有多個相同 app 的 Pods。
# 檢查 Pending Pod 的詳細資訊
kubectl describe pod -l app=multi-node-app | grep -A 10 "Events:"
你會看到類似這樣的事件:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 59s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 node(s) didn't match pod anti-affinity rules. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
所以我們要做的事情只有 1. 增加 Node 或者乾脆別弄第3個 pod XD
恢復副本數量
# 恢復到 2 個副本
kubectl scale deployment multi-node-app --replicas=2
KinD 目前不支援動態增加 Node 到現有cluster中,所以如果需要實驗,只能重建cluster,將一開始的 Kind config YAML 去新增 worker node。
TopologyKey 是 Affinity 機制中最重要的概念之一:
常用的 TopologyKey
| TopologyKey | 含義 | 使用場景 |
|---|---|---|
| kubernetes.io/hostname | 節點級別 | 確保 Pod 在不同節點上 |
| topology.kubernetes.io/zone | 可用區級別 | 跨區域高可用 |
| topology.kubernetes.io/region | 地區級別 | 跨地區部署 |
| failure-domain.beta.kubernetes.io/zone | 舊版可用區 | 向後兼容 |
今天學習這些 Affinity 的機制,對後端的我在設計架構上蠻有幫助的。
我能設計高可用性架構,利用podAntiAffinity, 確保 API 服務分散部署,避免單點故障的問題。
也能在設計微服務時,利用podAffinity,盡量讓API 服務與資料庫部署在同一節點,減少網路延遲。或者一些資源密集型的服務,能透過nodeAffinity來調度,像是需要機器學習服務或LLM模型部署到 有 GPU 節點上。
甚至能優化成本,Dev 開發環境,允許 Pod 密集部署節省資源。而運營環境則分散部署確保服務穩定性。
對後端工程師來說,掌握這些概念能夠設計出更穩健、高效的微服務架構!