在大型語言模型時代,為了在有限資源下,讓模型快速適應特定領域,過去的做法是全量微調(Full Fine-tuning),直接更新整個模型的所有權重,但這種方法需要龐大的運算資源和消耗大量儲存空間。為了解決這個問題,微軟在 2021 年提出了 LoRA(Low-Rank Adaptation),成為如今高效微調 LLM 的關鍵技術。
在最傳統的做法中,我們會同時更新整個 預訓練權重(Pretrained Weight) 和 更新權重(Update Weight),最後得到一個新的「適配後權重(Adapted Weight)」。
這種方式效果最佳,但計算與儲存成本極高。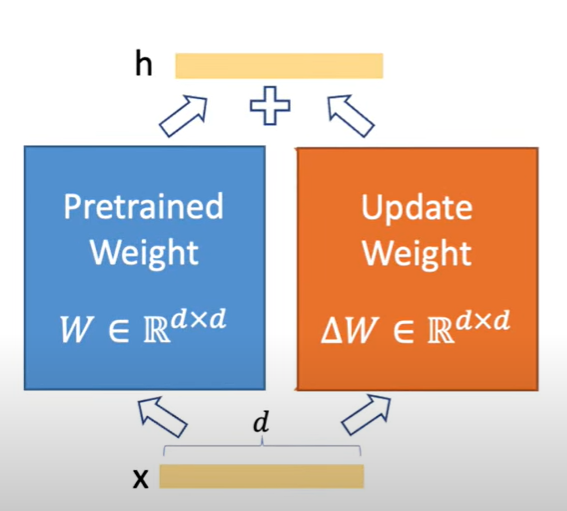
經過全量微調後,模型會得到一個全新的大權重矩陣,雖然適應了新任務,但需要將整個模型重新儲存與部署,非常不便。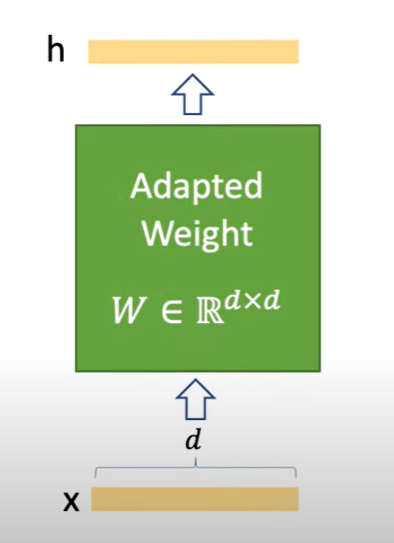
LoRA 引入了 低秩分解(Low-Rank Decomposition) 的想法。
它不再直接更新整個矩陣,而是將更新量 ΔW\Delta WΔW 拆解成兩個小矩陣:
ΔW=A⋅B\Delta W = A \cdot B
ΔW=A⋅B
其中 AAA 是隨機初始化的小矩陣,BBB 初始為 0,只需訓練這兩個矩陣即可,這樣就能用極少的參數量達到類似全量微調的效果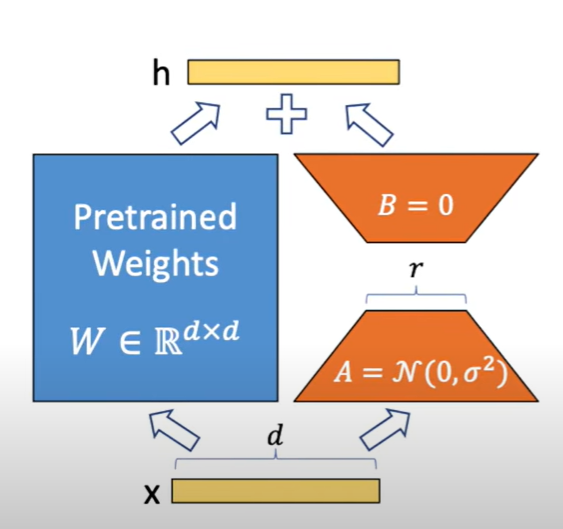
LoRA 的出現,讓LLM 微調不再是巨頭公司才能進行的任務,而是能普及到更多研究者與開發者。

