
承接前兩天的討論,當我們意識到同步模型的局限性後,自然會想:「那就直接用 Streaming 處理所有數據吧!」但在 2010 年代初期,純 Streaming 架構面臨技術上的挑戰。
在大數據剛興起的年代,「即時處理」還是個奢侈品。Hadoop 和 MapReduce 擅長批量處理大數據,但對於秒級甚至分鐘級的即時查詢幾乎無能為力。Lambda Architecture 就是為了解決這個痛點而誕生的經典架構。
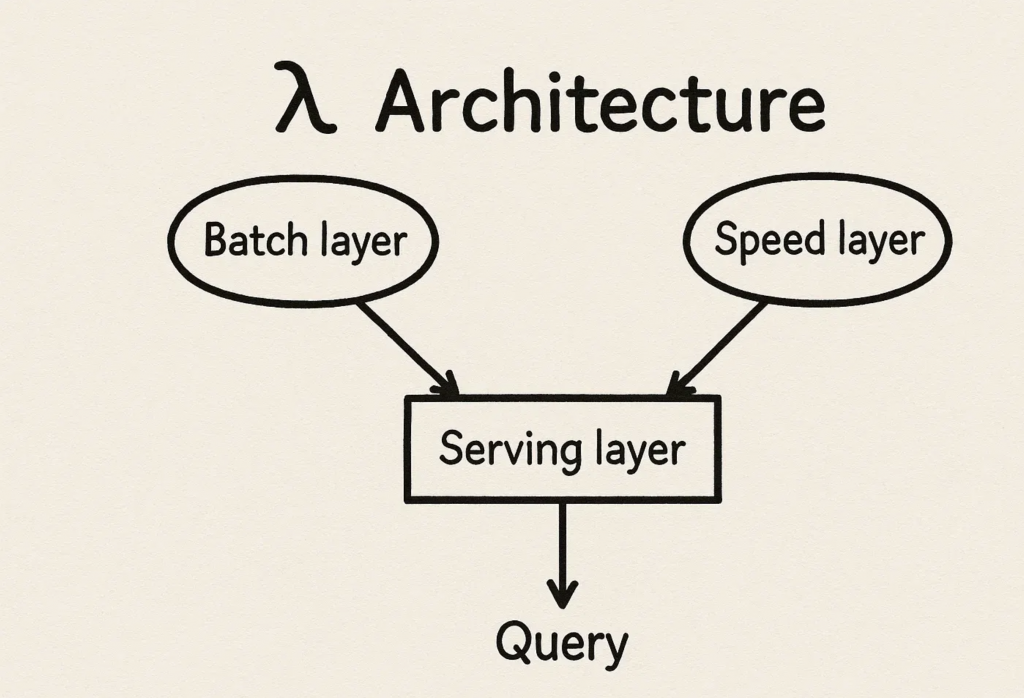
Lambda 架構採用分層處理的策略,將數據處理分為三個獨立的層次:
Raw Data Stream
│
┌───────────────────┐
│ │
▼ ▼
┌─────────────┐ ┌──────────────┐
│ Batch Layer │ │ Speed Layer │
│ │ │ │
│ │ │ │
└─────────────┘ └──────────────┘
│ │
│ │
│ │
└──────────┼─────────┘
▼
┌─────────────────────┐
│ Serving Layer │
└─────────────────────┘
Batch Layer(批次層)
Speed Layer(速度層)
Serving Layer(服務層)
這種設計的核心價值是同時滿足「即時」與「最終一致」兩個目標。
在 Lambda 架構的典型實作中:
Batch Layer 處理流程:
Speed Layer 處理流程:
查詢端整合:
查詢端只需要對 Serving DB 發送請求,Batch 和 Speed 的數據會在此無縫合併。
💡注意
本文所有程式碼皆為 示意用 Pseudo Code,目的在於解釋實作的觀念與流程。
以電商訂單統計為例:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/query/<merchant_id>")
def query(merchant_id):
batch_result = query_batch_table(merchant_id) # 查 Batch layer 結果
speed_result = query_speed_table(merchant_id) # 查 Speed layer 結果
combined_result = batch_result + speed_result # 合併查詢結果
return jsonify({"merchant_id": merchant_id, "order_count": combined_result})
def query_batch_table(merchant_id):
# 模擬 batch layer 查詢(完整歷史數據)
return 1000 # 假設 batch 計算出 1000 筆
def query_speed_table(merchant_id):
# 模擬 speed layer 查詢(今日增量),會有一些計算在這
return 50 # 假設 speed 計算出 50 筆
if __name__ == "__main__":
app.run(debug=True)
這段程式展示了 Lambda 架構的精神:查詢時動態合併 Batch 與 Speed 的結果,讓用戶獲得近即時且最終一致的數據。
Lambda Architecture 在 Hadoop 時代確實解決了核心痛點,讓企業第一次有機會做到「幾乎即時」的分析體驗。雖然它付出了雙倍的開發與維護代價,但這個架構的演進歷程告訴我們:技術架構往往是當時技術能力的最佳妥協方案。
前三天我們從理論角度探討了:
接下來,我們要從紙上談兵進入實戰階段!
從 Day 4 開始,接下來的十幾天我們將動手實作,從最基礎的 Python 手寫 Kafka consumer 開始,透過簡單的 pseudo code 逐步理解一個 Stream Processing Engine 背後的核心功能與運作原理。
準備好捲起袖子寫程式了嗎?讓我們實際感受一下,當年那些工程師是如何用最樸實的方式一步步構建出強大的 Stream Processing 系統的!

 iThome鐵人賽
iThome鐵人賽