
昨天我們探討了 Flink + Iceberg 如何在分鐘級延遲下提供更好的成本效益,看到了 Data Lakehouse 架構的優勢。但你可能會好奇:既然 Flink 在流式處理領域如此強大,為什麼不直接開發一個專門為流式處理優化的 Lakehouse 格式呢?
答案就是今天的主角:Apache Paimon(原名 Flink Table Store)- 由 Flink 社群開發的流式原生 Lakehouse 格式。
Paimon 採用 LSM-Tree (Log-Structured Merge Tree) 作為底層存儲結構,這是 NoSQL 資料庫常用的架構:
LSM-Tree in Paimon:
┌─────────────────────────────────────────────────────────┐
│ Memory │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ MemTable 1 │ │ MemTable 2 │ │
│ │ (Active) │ │ (Flushing) │ │
│ └─────────────┘ └─────────────┘ │
└─────────────────────┬───────────────────────────────────┘
│ Flush to Disk
▼
┌─────────────────────────────────────────────────────────┐
│ Disk Storage │
│ Level 0: [SST1] [SST2] [SST3] [SST4] │
│ Level 1: [──── SST5────] [────SST6────] │
│ Level 2: [──────────SST7──────────] │
│ │
│ New data in upper levels, periodic merge to lower │
└─────────────────────────────────────────────────────────┘
LSM-Tree 的流式優勢:
實時寬表的傳統困境:
在實時場景下,通常需要構建大寬表來支持 Ad-Hoc Query。傳統做法是使用多流 JOIN:
訂單流 + 用戶流 + 商品流 + 支付流 + 物流流
↓
流式 JOIN 引擎
↓
大寬表
多流 JOIN 的狀態爆炸問題:
Partial Update 的解決方案:
Paimon 通過 Partial Update 將 JOIN 操作下沉到存儲層:
訂單流 → 寫入訂單相關欄位
用戶流 → 寫入用戶相關欄位
商品流 → 寫入商品相關欄位
支付流 → 寫入支付相關欄位
物流流 → 寫入物流相關欄位
→ 存儲層自動 Merge
→ 完整寬表
核心優勢:
以往在流處理中需要 Lookup Join 數據時,常見做法是:
流式事件 → 查詢 Redis/KV → 獲取資料 → 組裝完整記錄
傳統方案的問題:
Paimon Lookup Join 的解決方案:
Paimon 直接支援 Lookup Join:
流式事件 → 直接 JOIN Paimon 維度表 → 獲取資料 → 組裝完整記錄
核心優勢:
目前 Iceberg 不支援索引,但 Paimon 支援欄位等級的索引,可有效加強點查詢與範圍查詢能力
file-index.bloom-filter.columns: specify the columns that need bloom filter index.
file-index.bloom-filter.<column_name>.fpp to config false positive probability.
file-index.bloom-filter.<column_name>.items to config the expected distinct items in one data file.
file-index.bitmap.columns: specify the columns that need bitmap index.
file-index.bitmap.<column_name>.index-block-size: to config secondary index block size, default value is 16kb.
file-index.range-bitmap.columns: specify the columns that need range-bitmap index.
file-index.range-bitmap.<column_name>.chunk-size: to config the chunk size, default value is 16kb.
例如與 Flink-CDC 整合,能自動達成 auto schema evolution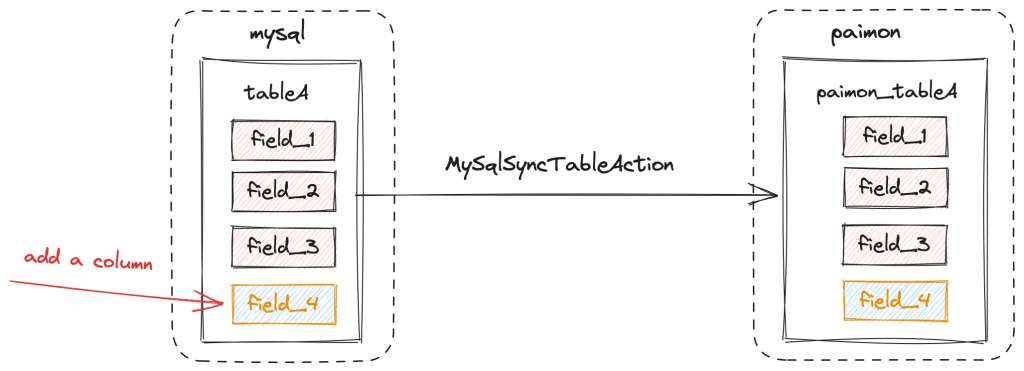
Paimon 支援產生與 Iceberg 相容的元數據,以便 Iceberg 使用者可以直接使用 Paimon 表。
Paimon 繼承了 Iceberg 統一批流存儲的成本優勢,並在延遲性能上實現了重大突破,並增加了不少功能讓 streaming 生態更完整,與 Iceberg 一樣,Paimon 不需要維護 Kafka + OLAP Database 的多套存儲系統,帶來了顯著的系統成本降低和維運複雜度簡化。
在延遲表現上,Paimon 相比 Iceberg 有了質的飛躍:
Latency Comparison:
┌────────────────────────────────────────────────────┐
│ Iceberg: 5-10 minutes (small file problem) │
│ ↓ │
│ Paimon: 30 seconds - 1 minute (LSM-Tree optimized)│
└────────────────────────────────────────────────────┘
關鍵技術差異:
Business Latency Requirements:
┌──────────────────────────────────────────────────────┐
│ < 1 second: Kafka + Flink (millisecond real-time)│
│ 30s - 1 minute: Paimon (near real-time) │
│ 5-10 minutes: Iceberg (near real-time) │
│ > 1 hour: Traditional batch processing │
└──────────────────────────────────────────────────────┘
Paimon 填補了 Kafka 的高成本複雜性和 Iceberg 的高延遲之間的空白,為大多數準實時業務場景提供了理想的平衡點。
在深入了解了 Flink、Kafka、Iceberg、Paimon 等技術後,你可能會問:「這些方案看起來都很強大,但在實際開發中遇到的痛點呢?」
下一章我們將分享筆者的真實經歷:為什麼在使用 Flink 一段時間後,開始考慮更易用的 SQL-based 流處理引擎。
