Hi大家好,
這是我參加 iT 邦幫忙鐵人賽的第 1 次挑戰,這次的主題聚焦在結合 Python 爬蟲、RAG(檢索增強生成)與 AI,打造一套 PTT 文章智慧問答系統。在過程中,我會依照每天進度上傳程式碼到 GitHub ,方便大家參考學習。也歡迎留言或來信討論,我的信箱是 gerryearth@gmail.com。
在前一篇文章,我們認識了 PTT 的 HTML 結構與 age-check 機制,今天我們將把 PTT 文章完整擷取下來並稍作整理。
首先,先給大家我寫的爬蟲程式做參考:
import requests
from bs4 import BeautifulSoup
from datetime import datetime
from zoneinfo import ZoneInfo
def get_html(url: str) -> str:
session = requests.Session()
payload = {
"from": url,
"yes": "yes"
}
session.post("https://www.ptt.cc/ask/over18", data=payload)
response = session.get(url)
return response.text
def get_urls_from_board_html(html: str) -> list:
html_soup = BeautifulSoup(html, 'html.parser')
r_ent_all = html_soup.find_all('div', class_='r-ent')
urls = []
for r_ent in r_ent_all:
# 若無r_ent.find('a')['href']代表文章已刪除
if r_ent.find('a'):
if r_ent.find('a')['href']:
urls.append('https://www.ptt.cc' + r_ent.find('a')['href'])
return urls
def get_data_from_article_html(html: str) -> dict:
html_soup = BeautifulSoup(html, 'html.parser')
article_soup = html_soup.find('div', class_='bbs-screen bbs-content')
title = article_soup.find_all('span', class_='article-meta-value')[2].text
author = article_soup.find_all('span', class_='article-meta-value')[0].text.strip(')').split(' (')[0]
time_str = article_soup.find_all('span', class_='article-meta-value')[3].text
dt = datetime.strptime(time_str, "%a %b %d %H:%M:%S %Y")
dt = dt.replace(tzinfo=ZoneInfo("Asia/Taipei"))
post_time = dt.strftime("%Y-%m-%d %H:%M:%S")
result = []
for element in article_soup.children:
if element.name not in ["div", "span"]:
text = element.get_text(strip=True) if element.name == "a" else str(element).strip()
if text:
result.append(text)
content = "\n".join(result).strip('-')
data = {
'title': title,
'author': author,
'post_time': post_time,
'content': content,
}
return data
def ptt_scrape(board: str) -> list:
board_url = 'https://www.ptt.cc/bbs/' + board + '/index.html' # 首先建立看板網址
board_html = get_html(board_url) # 由看板網址取得 html
article_urls = get_urls_from_board_html(board_html) # 由看板 html 取得文章網址
article_datas = []
for article_url in article_urls:
article_html = get_html(article_url) # 由文章網址取得 html
article_data = get_data_from_article_html(article_html) # 由文章 html 取得文章資訊
article_data.update({'board': board}) # 加入版面名稱資訊
article_datas.append(article_data) # 將文章資訊蒐集起來
return article_datas # 回傳文章資訊列表
if __name__ == "__main__":
article_datas = ptt_scrape("Gossiping")
for article_data in article_datas:
print(article_data)
範例輸出:
{
'title': '新聞 標題內容',
'author': '作者ID',
'post_time': '2025-05-26 14:12:33',
'content': '這是文章內容',
'board': 'Gossiping'
}
這段程式碼是一個 PTT(批踢踢實業坊)網頁爬蟲,用來從某個特定的看板(例如 Gossiping)中,抓取目前頁面上的文章標題、作者、時間和內文。下面是各部分的簡單說明:
get_html(url: str) -> strget_urls_from_board_html(html: str) -> list<a> 標籤)的文章。get_data_from_article_html(html: str) -> dict功能:從一篇文章的 HTML 中擷取詳細資訊:
技巧:
datetime.strptime 把時間轉成標準格式,並加上時區(台灣時間)。ptt_scrape(board: str) -> list功能:綜合上述函數,完成整個爬蟲流程。
最後如果可以順利拿到類似以下的內容就代表你成功啦!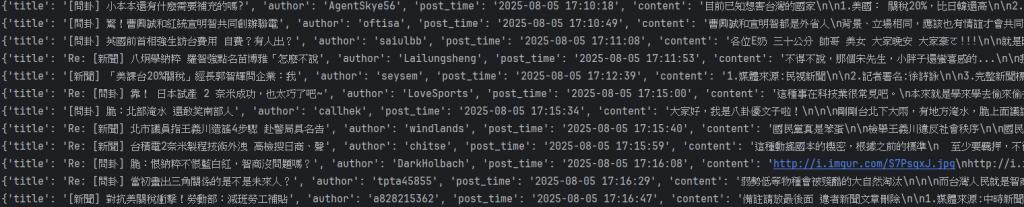
明天【Day08】設計 Django Model 並連接資料庫 - 定義資料結構與模型,我們將進一步學習如何在 Django 中設計資料模型(Model),這也是開發資料驅動應用的核心步驟。透過定義 Model,我們可以清楚描述資料的結構與關聯,並自動對應到資料庫中的資料表。

