Hi大家好,
這是我參加 iT 邦幫忙鐵人賽的第 1 次挑戰,這次的主題聚焦在結合 Python 爬蟲、RAG(檢索增強生成)與 AI,打造一套 PTT 文章智慧問答系統。在過程中,我會依照每天進度上傳程式碼到 GitHub ,方便大家參考學習。也歡迎留言或來信討論,我的信箱是 gerryearth@gmail.com。
今天我們將進一步學習如何在 Django 中設計資料模型(Model),這也是開發資料驅動應用的核心步驟。透過定義 Model,我們可以清楚描述資料的結構與關聯,並自動對應到資料庫中的資料表。
我們會搭配 MariaDB 作為後端資料庫,實際操作如何將資料模型儲存到資料庫中,並執行基本的資料操作(增、查、改、刪)。
article apparticle 的 Django App在專案根目錄下輸入以下指令建立新的 app:
python manage.py startapp article
然後就會自動幫你新增以下檔案:
接下來請將 article 加入 settings.py 的 INSTALLED_APPS 中:
INSTALLED_APPS = [
...
'article',
]
編輯 article/models.py:
from django.db import models
class Article(models.Model):
board = models.CharField(max_length=100) # 看板名稱
title = models.CharField(max_length=255) # 文章標題
author = models.CharField(max_length=100) # 作者帳號
content = models.TextField() # 文章內文
post_time = models.DateTimeField() # po文時間
url = models.URLField(max_length=255) # 文章連結
def __str__(self):
return f"[{self.board}] {self.title}"
在執行資料庫遷移前,請先把資料庫設定改為以下內容:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'my_database',
'USER': 'root',
'PASSWORD': 'root',
'HOST': 'localhost',
'PORT': '3306',
}
}
使用 Django 的 ORM migration 流程:
python manage.py makemigrations article
python manage.py migrate
確認後 MariaDB 中會建立 article_article(appname_modelname 格式)這張資料表。
| 欄位名稱 | 資料型別 | 長度 | 說明 |
|---|---|---|---|
| id | BIGINT | 20 | 主鍵,自動遞增 |
| board | VARCHAR | 100 | 看板名稱 |
| title | VARCHAR | 255 | 文章標題 |
| author | VARCHAR | 100 | 作者帳號 |
| content | LONGTEXT | X | 文章內容 |
| post_time | TIMESTAMP | 6 | 發文時間 |
| url | VARCHAR | 255 | 文章連結 |
為了確認資料表與模型設定正確,我們來將測試資料寫入資料庫。
在檔案 scraper.py 最上方增加以下程式碼,手動設定 Django 環境:
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'ptt_rag_dev.settings')
django.setup()
將 ptt_scrape 倒數第三行改為,這樣我們就能運用 url:
article_data.update({'board': board, 'url': article_url}) # 加入版面名稱資訊與網址
接著將 if __name__ == "__main__": 的部分改為:
if __name__ == "__main__":
from article.models import Article
from django.db.utils import IntegrityError
article_datas = ptt_scrape("Gossiping")
for article_data in article_datas:
print(article_data)
try:
Article.objects.create(
board=article_data['board'],
title=article_data["title"],
author=article_data["author"],
url=article_data["url"],
content=article_data["content"],
post_time=article_data["post_time"]
)
except IntegrityError:
print("寫入錯誤!")
print('完成所有寫入!')
直接執行 scraper.py 後可以看到資料庫 article_article 確實寫入資料了!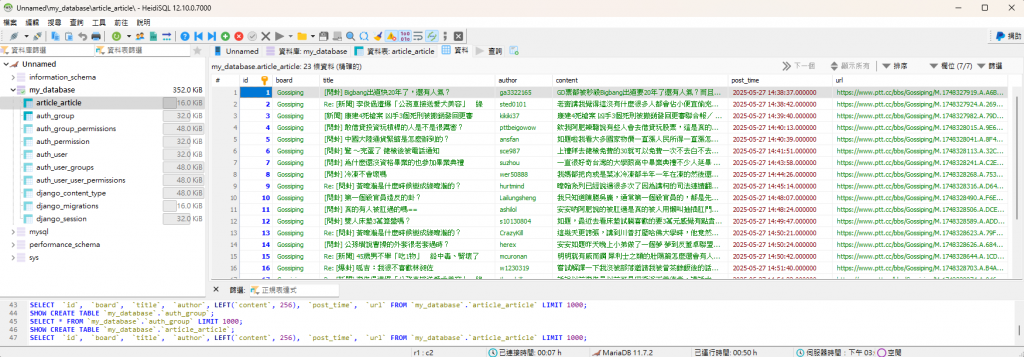
明日預告 –【Day 09】使用 Celery + Redis 建立非同步排程爬蟲
下一篇我們將開始打造自動化爬蟲任務,讓系統可以定期抓取最新文章並寫入資料庫。不必手動點擊,一切交給背景執行!

