昨天我們透過 Helm Chart 把 Deployment / Service / Ingress / ConfigMap / Secret 模板化。
今天來換個節奏,用「觀念+圖解」的方式,快速認識 **Kubernetes 在高可用(HA)與自動擴展(scaling)**上的幾個核心機制。
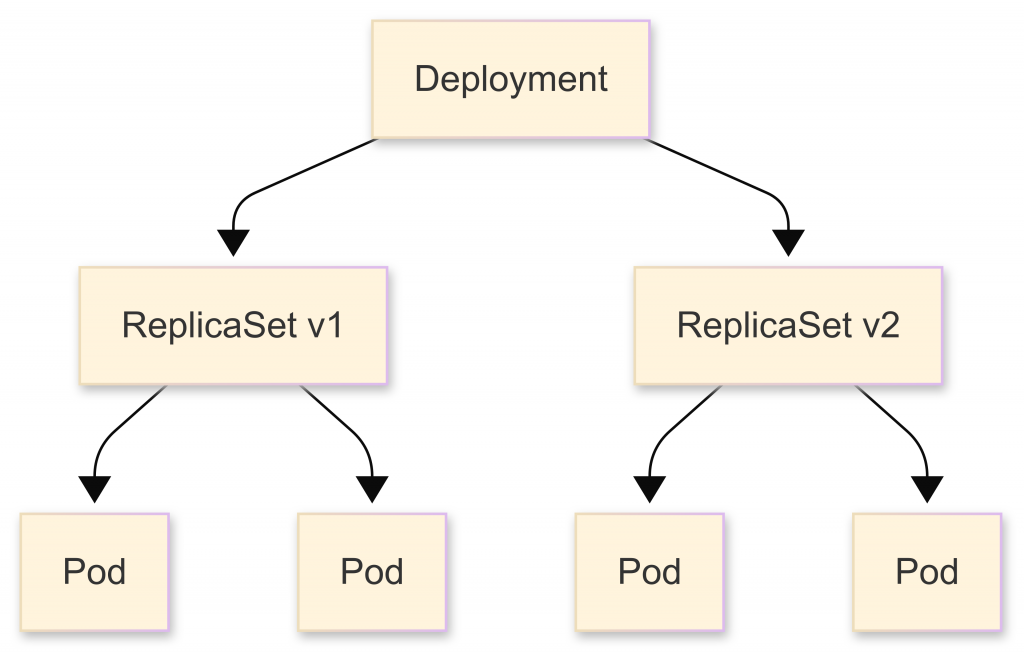
Deployment 為何比 ReplicaSet 更實用?
▪ ReplicaSet:確保 Pod 的數量符合設定,但沒有版本控制
▪ Deployment:在 ReplicaSet 之上,支援滾動更新與回滾,才是主流的應用部署方式
📌 圖解:Deployment → 管理多個 ReplicaSet → ReplicaSet 再管理 Pod
「遇到流量暴增,要怎麼自動擴展?」
▪ 根據 CPU / Memory(或自定義 metrics)自動調整 Pod 數量
▪ 適合應付流量高峰,避免資源浪費
▪ 實戰常見 CPU threshold:50%~70%,避免過度頻繁的伸縮
📌 圖解:流量上升 → HPA 擴增 Pod → 負載平均分散

「升級時如何避免一次掛光?」
▪ 限制同時可中斷的 Pod 數量,避免維護或升級時導致服務不可用
▪ 常用場景:Cluster 升級、節點重啟時保護關鍵服務
📌 圖解:有 3 個 Pod,PDB 設定 minAvailable: 2 → 任何時刻至少保留 2 個 Pod

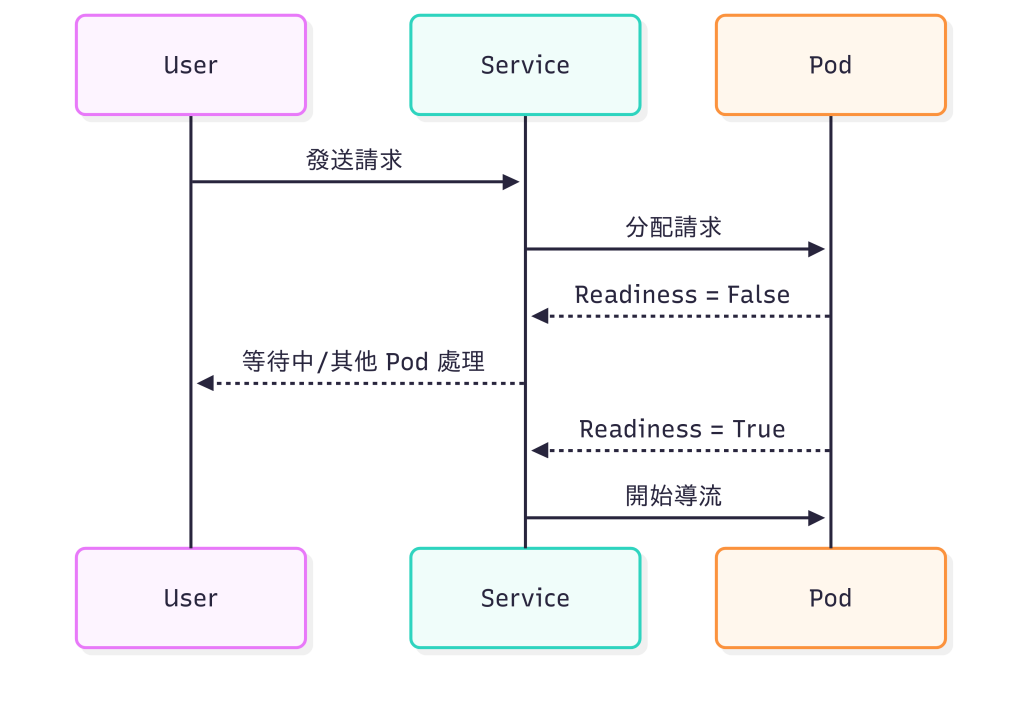
「Pod 什麼時候才算真正 Ready?」
▪ 常搭配 Liveness Probe,分別處理『是否可接流量』與『是否還活著』
▪ 控制 Pod 何時對外「可用」
▪ 在應用尚未初始化完成前,不會被加入 Service 負載平衡
📌 圖解:Pod Ready 狀態 = ✅ 才能接收流量
今天主要用 圖解+最小 YAML 來認識高可用與自動擴展的核心工具:
▪ Deployment 負責滾動更新與回滾 → 解決版本更新
▪ HPA 幫你自動水平擴展 → 解決流量高峰
▪ PDB 確保升級或維護時不會全部掛掉 → 解決維護容錯
▪ Readiness Probe 控制 Pod 何時能真正接流量 → 解決啟動可用性
🧭 「高可用不是靠單一機制,而是 Deployment × HPA × PDB × Probe 的組合拳。」
Day 17|Terraform 佈署雲端資源

