鐵人賽來到一半,剛好主要流程也串好,今天就先來總結一下目前的架構然後測試一下大量請求時是否符合 Cloud Native 的 Auto-Scaling 要求。
目前的架構圖如下,非常簡潔:
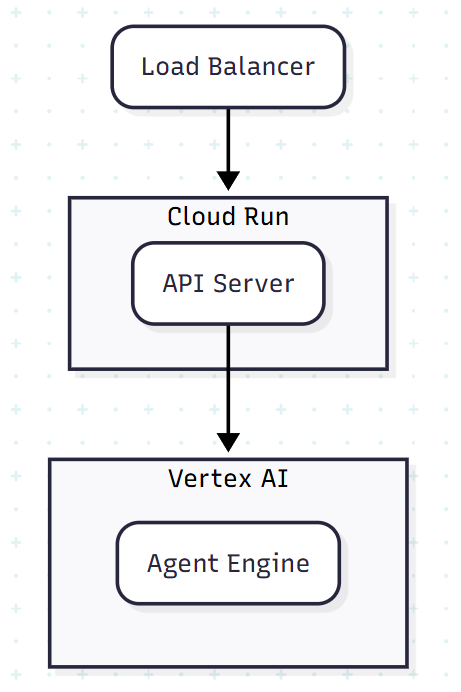
最外層是 Load Balancer 會呼叫由 Cloud Run 架設的 API Server,而 API Server 會呼叫由 Vertex AI 管理的 Agent Engine。如果設定正確的話,當大量請求進來時 API Server 和 Agent Engine 應該要能夠自動複製自己來回應請求,像是這樣:
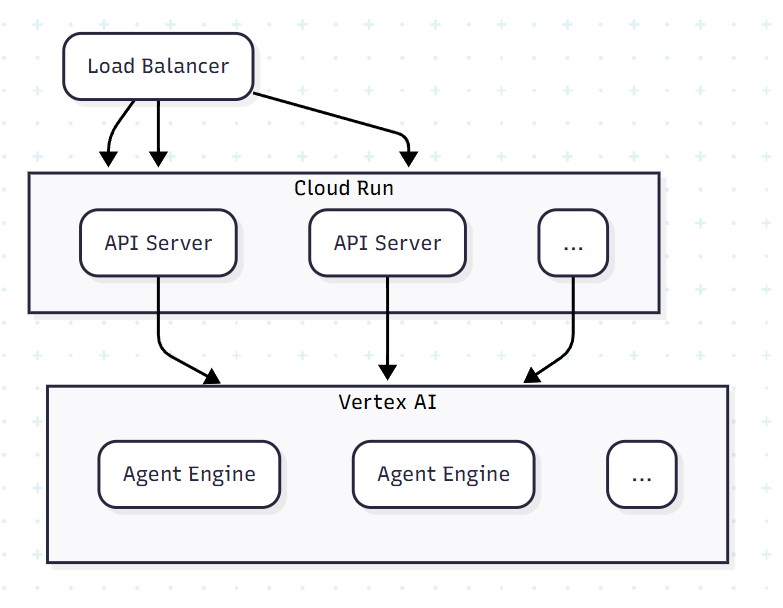
那就來寫個範例程式來瘋狂請求試試看,但因為之前把 Load Balancer 關掉了,現在先直接對 Cloud Run 產生的 URL 操作:
#!/bin/bash
export APP_URL=...
run () {
curl -X POST $APP_URL/query \
-H "Content-Type: application/json" \
-d '{
"locations": ["Tokyo"],
"startDate": "2025-09-10",
"days": 2,
"language": "Chinese Traditional" }' > /dev/null
}
for i in {1..20}; do
run &
done
wait
同時進行 20 個請求的 Log 如下:
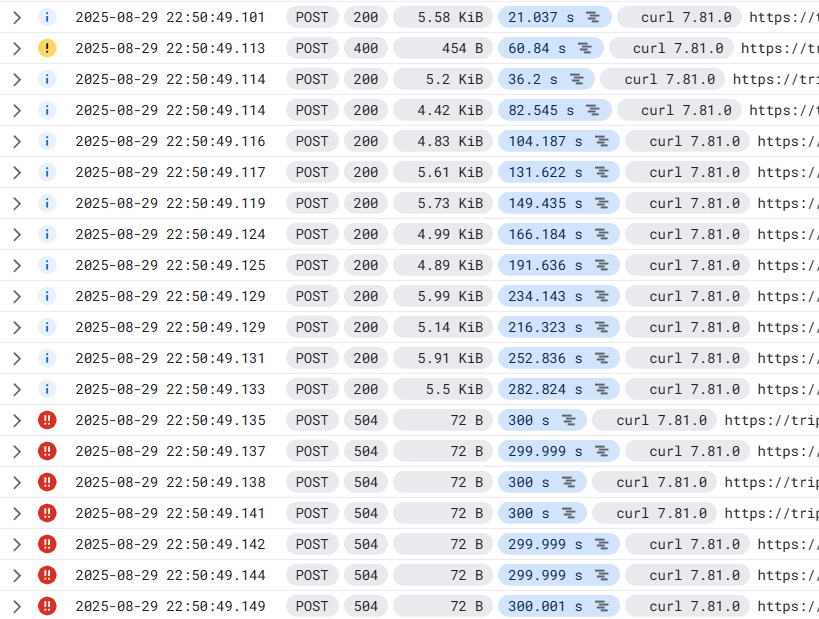
可以看到後面幾個都 504 Timeout 了,但 Cloud Run 建立的 Container 數量還是只有 1 :
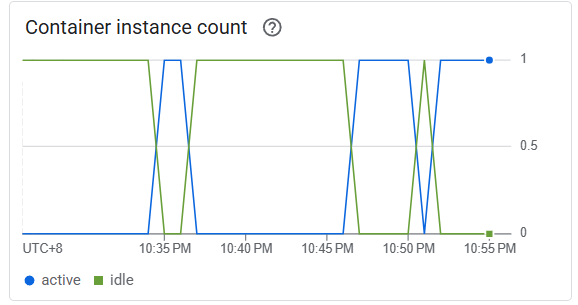
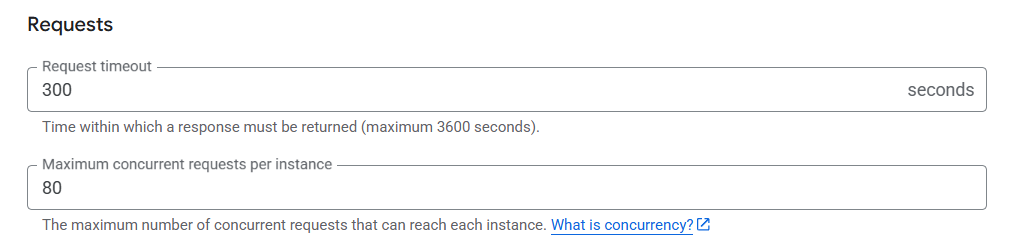
查了一下 Cloud Run 的設定,發現可以限制每個 Instance 的最大請求數。這邊設定是 80,所以只有 20 個請求還不足以觸發 Auto-Scaling:
而 Agent Engine 則是 CPU allocation 有上升:
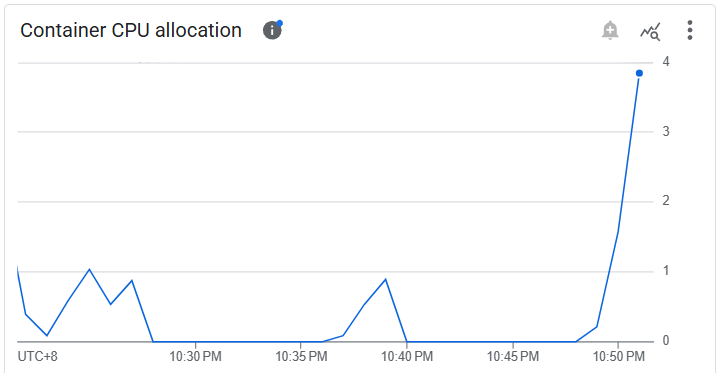
體感上雖然同時放出 20 個請求,但回應還是慢慢的一個一個回來,不太確定是 API Server 呼叫 Agent 的地方寫壞,還是有什麼設定沒調對,明天再來看看怎麼處理。

