在上一篇文章中,我們已經完成資料的整併,但仍有一些格式不一致之處,或需要確認是否存在遺漏值並刪除。可以透過以下方式進行檢查。
首先,我們可以查看 DataFrame 中的缺失值數量與比例:
import pandas as pd
# 假設 df 是已讀入的評論資料 DataFrame
print(limited_df.isnull().sum())
print(limited_df.isnull().mean())
透過這個方式,我們可以快速了解哪些欄位有缺值,以及缺值比例是否需要進一步處理。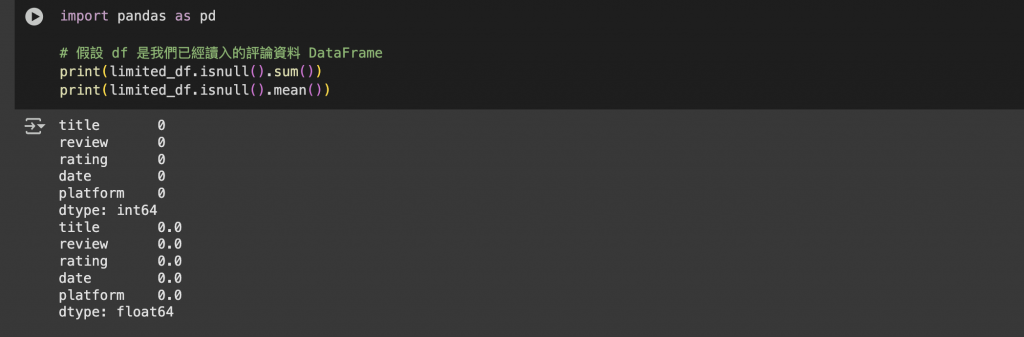
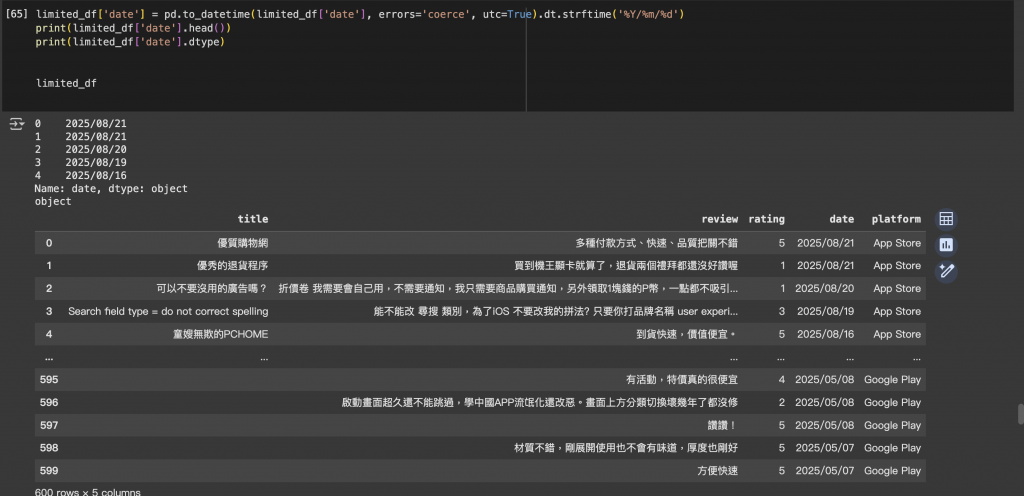
資料中日期欄位可能格式不一致,我們將其統一為 YYYY/MM/DD 格式:
limited_df['date'] = pd.to_datetime(limited_df['date'], errors='coerce', utc=True).dt.strftime('%Y/%m/%d')
print(limited_df['date'].head())
print(limited_df['date'].dtype)
整理後的 DataFrame 如下:
limited_df
為了後續文字分析,我們需要安裝必要套件,並設定繁體中文字型:
!pip install wordcloud matplotlib -qqq
import matplotlib as mpl
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
# 下載繁體中文字型
!wget -O SourceHanSerifTW-VF.ttf https://github.com/adobe-fonts/source-han-serif/raw/release/Variable/TTF/Subset/SourceHanSerifTW-VF.ttf
# 加入字型
fm.fontManager.addfont('SourceHanSerifTW-VF.ttf')
# 設定字型
mpl.rc('font', family='Source Han Serif TW VF')
新增一欄計算每則評論的字數,並以直方圖檢視字數分布:
# 新增一欄計算評論字數
limited_df_new = limited_df.copy()
limited_df_new['comment_length'] = limited_df_new['review'].astype(str).apply(len)
# 繪製字數分布圖
plt.hist(limited_df_new['comment_length'], bins=30)
plt.title('評論字數分布')
plt.xlabel('字數')
plt.ylabel('評論數')
plt.show()
透過字數分布,我們可以快速掌握評論的長度趨勢,並為後續文字分析做準備。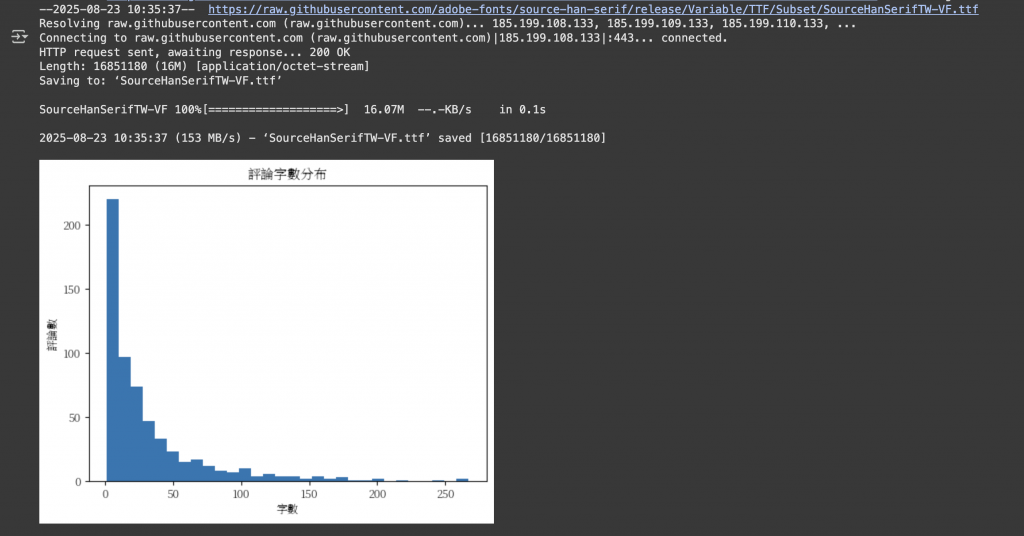
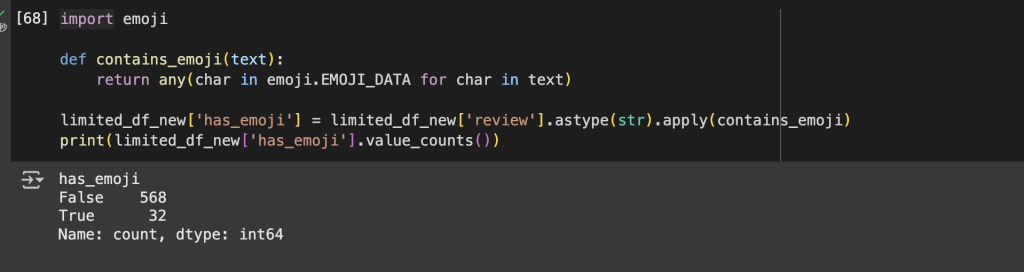
最後,我們可以檢查每則評論中是否包含 emoji,作為文字內容特徵的一部分:
import emoji
def contains_emoji(text):
return any(char in emoji.EMOJI_DATA for char in text)
limited_df_new['has_emoji'] = limited_df_new['review'].astype(str).apply(contains_emoji)
print(limited_df_new['has_emoji'].value_counts())
以上步驟,我們初步完成對資料格式、字數與 emoji 特徵的基本檢查與整理。


 iThome鐵人賽
iThome鐵人賽